 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLights, Camera, Matching: The Role of Image Illumination in Fair Face Recognition
Jan 15, 2025



Facial brightness is a key image quality factor impacting face recognition accuracy differentials across demographic groups. In this work, we aim to decrease the accuracy gap between the similarity score distributions for Caucasian and African American female mated image pairs, as measured by d' between distributions. To balance brightness across demographic groups, we conduct three experiments, interpreting brightness in the face skin region either as median pixel value or as the distribution of pixel values. Balancing based on median brightness alone yields up to a 46.8% decrease in d', while balancing based on brightness distribution yields up to a 57.6% decrease. In all three cases, the similarity scores of the individual distributions improve, with mean scores maximally improving 5.9% for Caucasian females and 3.7% for African American females.
What is a Goldilocks Face Verification Test Set?
May 24, 2024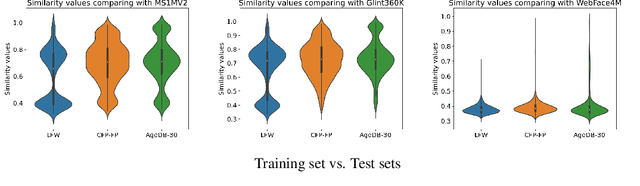
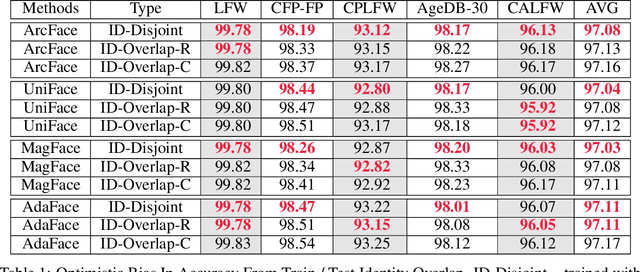


Face Recognition models are commonly trained with web-scraped datasets containing millions of images and evaluated on test sets emphasizing pose, age and mixed attributes. With train and test sets both assembled from web-scraped images, it is critical to ensure disjoint sets of identities between train and test sets. However, existing train and test sets have not considered this. Moreover, as accuracy levels become saturated, such as LFW $>99.8\%$, more challenging test sets are needed. We show that current train and test sets are generally not identity- or even image-disjoint, and that this results in an optimistic bias in the estimated accuracy. In addition, we show that identity-disjoint folds are important in the 10-fold cross-validation estimate of test accuracy. To better support continued advances in face recognition, we introduce two "Goldilocks" test sets, Hadrian and Eclipse. The former emphasizes challenging facial hairstyles and latter emphasizes challenging over- and under-exposure conditions. Images in both datasets are from a large, controlled-acquisition (not web-scraped) dataset, so they are identity- and image-disjoint with all popular training sets. Accuracy for these new test sets generally falls below that observed on LFW, CPLFW, CALFW, CFP-FP and AgeDB-30, showing that these datasets represent important dimensions for improvement of face recognition. The datasets are available at: \url{https://github.com/HaiyuWu/SOTA-Face-Recognition-Train-and-Test}
Beard Segmentation and Recognition Bias
Aug 30, 2023
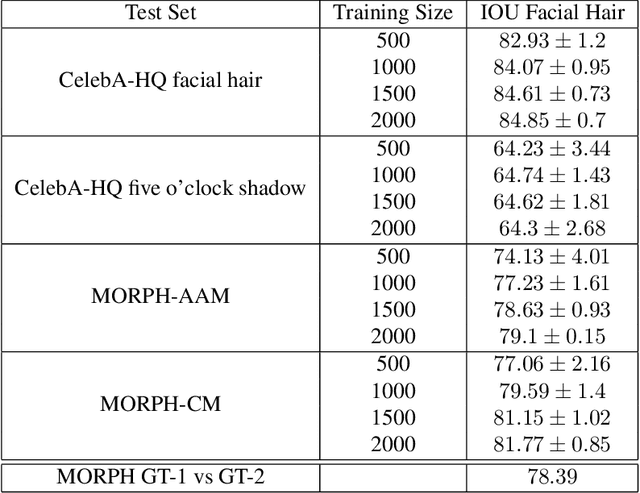

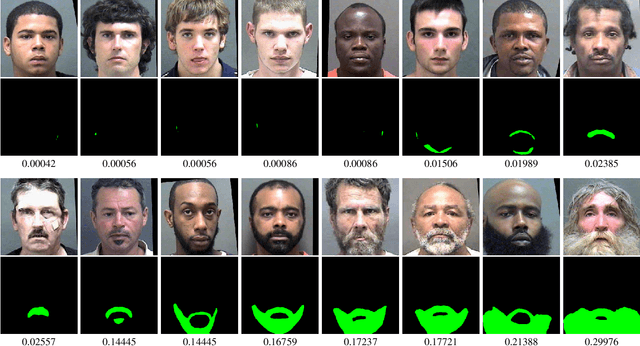
A person's facial hairstyle, such as presence and size of beard, can significantly impact face recognition accuracy. There are publicly-available deep networks that achieve reasonable accuracy at binary attribute classification, such as beard / no beard, but few if any that segment the facial hair region. To investigate the effect of facial hair in a rigorous manner, we first created a set of fine-grained facial hair annotations to train a segmentation model and evaluate its accuracy across African-American and Caucasian face images. We then use our facial hair segmentations to categorize image pairs according to the degree of difference or similarity in the facial hairstyle. We find that the False Match Rate (FMR) for image pairs with different categories of facial hairstyle varies by a factor of over 10 for African-American males and over 25 for Caucasian males. To reduce the bias across image pairs with different facial hairstyles, we propose a scheme for adaptive thresholding based on facial hairstyle similarity. Evaluation on a subject-disjoint set of images shows that adaptive similarity thresholding based on facial hairstyles of the image pair reduces the ratio between the highest and lowest FMR across facial hairstyle categories for African-American from 10.7 to 1.8 and for Caucasians from 25.9 to 1.3. Facial hair annotations and facial hair segmentation model will be publicly available.
Exploring Causes of Demographic Variations In Face Recognition Accuracy
Apr 14, 2023In recent years, media reports have called out bias and racism in face recognition technology. We review experimental results exploring several speculated causes for asymmetric cross-demographic performance. We consider accuracy differences as represented by variations in non-mated (impostor) and / or mated (genuine) distributions for 1-to-1 face matching. Possible causes explored include differences in skin tone, face size and shape, imbalance in number of identities and images in the training data, and amount of face visible in the test data ("face pixels"). We find that demographic differences in face pixel information of the test images appear to most directly impact the resultant differences in face recognition accuracy.
Logical Consistency and Greater Descriptive Power for Facial Hair Attribute Learning
Feb 22, 2023Face attribute research has so far used only simple binary attributes for facial hair; e.g., beard / no beard. We have created a new, more descriptive facial hair annotation scheme and applied it to create a new facial hair attribute dataset, FH37K. Face attribute research also so far has not dealt with logical consistency and completeness. For example, in prior research, an image might be classified as both having no beard and also having a goatee (a type of beard). We show that the test accuracy of previous classification methods on facial hair attribute classification drops significantly if logical consistency of classifications is enforced. We propose a logically consistent prediction loss, LCPLoss, to aid learning of logical consistency across attributes, and also a label compensation training strategy to eliminate the problem of no positive prediction across a set of related attributes. Using an attribute classifier trained on FH37K, we investigate how facial hair affects face recognition accuracy, including variation across demographics. Results show that similarity and difference in facial hairstyle have important effects on the impostor and genuine score distributions in face recognition.
Consistency and Accuracy of CelebA Attribute Values
Oct 13, 2022
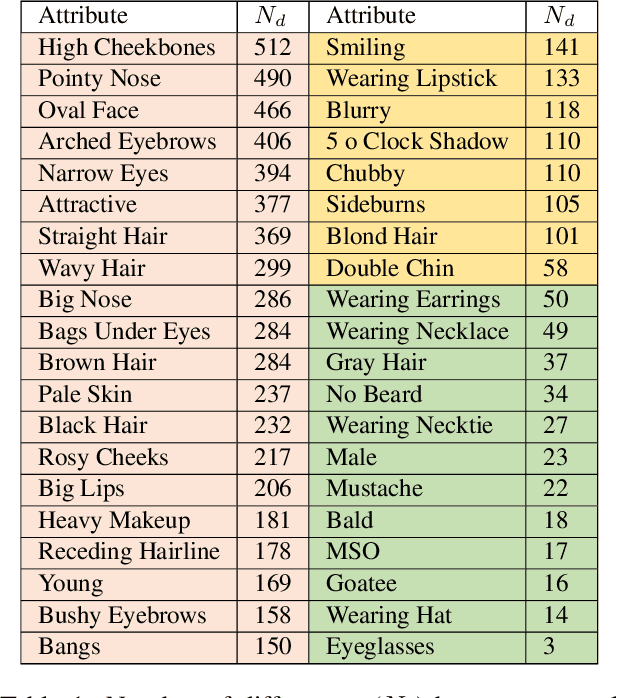

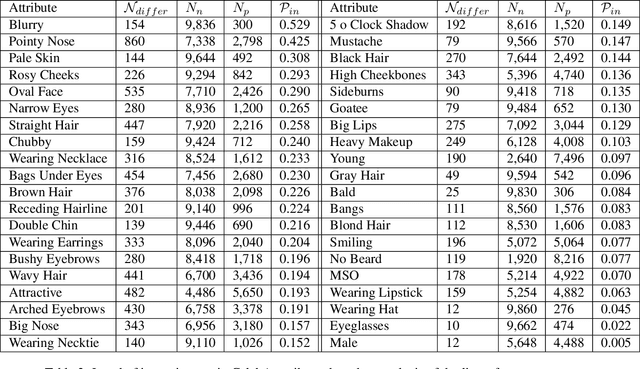
We report the first analysis of the experimental foundations of facial attribute classification. An experiment with two annotators independently assigning values shows that only 12 of 40 commonly-used attributes are assigned values with >= 95% consistency, and that three (high cheekbones, pointed nose, oval face) have random consistency (50%). These results show that the binary face attributes currently used in this research area could re-focused to be more objective. We identify 5,068 duplicate face appearances in CelebA, the most widely used dataset in this research area, and find that individual attributes have contradicting values on from 10 to 860 of 5,068 duplicates. Manual audit of a subset of CelebA estimates error rates as high as 40% for (no beard=false), even though the labeling consistency experiment indicates that no beard could be assigned with >= 95% consistency. Selecting the mouth slightly open (MSO) attribute for deeper analysis, we estimate the error rate for (MSO=true) at about 20% and for (MSO=false) at about 2%. We create a corrected version of the MSO attribute values, and compare classification models created using the original versus corrected values. The corrected values enable a model that achieves higher accuracy than has been previously reported for MSO. Also, ScoreCAM visualizations show that the model created using the corrected attribute values is in fact more focused on the mouth region of the face. These results show that the error rate in the current CelebA attribute values should be reduced in order to enable learning of better models. The corrected attribute values for CelebA's MSO and the CelebA facial hair attributes will be made available upon publication.