 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Causes of Demographic Variations In Face Recognition Accuracy
Apr 14, 2023In recent years, media reports have called out bias and racism in face recognition technology. We review experimental results exploring several speculated causes for asymmetric cross-demographic performance. We consider accuracy differences as represented by variations in non-mated (impostor) and / or mated (genuine) distributions for 1-to-1 face matching. Possible causes explored include differences in skin tone, face size and shape, imbalance in number of identities and images in the training data, and amount of face visible in the test data ("face pixels"). We find that demographic differences in face pixel information of the test images appear to most directly impact the resultant differences in face recognition accuracy.
Analysis of Gender Inequality In Face Recognition Accuracy
Jan 31, 2020


We present a comprehensive analysis of how and why face recognition accuracy differs between men and women. We show that accuracy is lower for women due to the combination of (1) the impostor distribution for women having a skew toward higher similarity scores, and (2) the genuine distribution for women having a skew toward lower similarity scores. We show that this phenomenon of the impostor and genuine distributions for women shifting closer towards each other is general across datasets of African-American, Caucasian, and Asian faces. We show that the distribution of facial expressions may differ between male/female, but that the accuracy difference persists for image subsets rated confidently as neutral expression. The accuracy difference also persists for image subsets rated as close to zero pitch angle. Even when removing images with forehead partially occluded by hair/hat, the same impostor/genuine accuracy difference persists. We show that the female genuine distribution improves when only female images without facial cosmetics are used, but that the female impostor distribution also degrades at the same time. Lastly, we show that the accuracy difference persists even if a state-of-the-art deep learning method is trained from scratch using training data explicitly balanced between male and female images and subjects.
Does Face Recognition Accuracy Get Better With Age? Deep Face Matchers Say No
Nov 14, 2019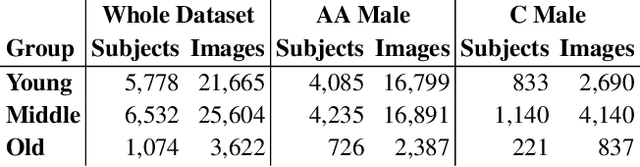

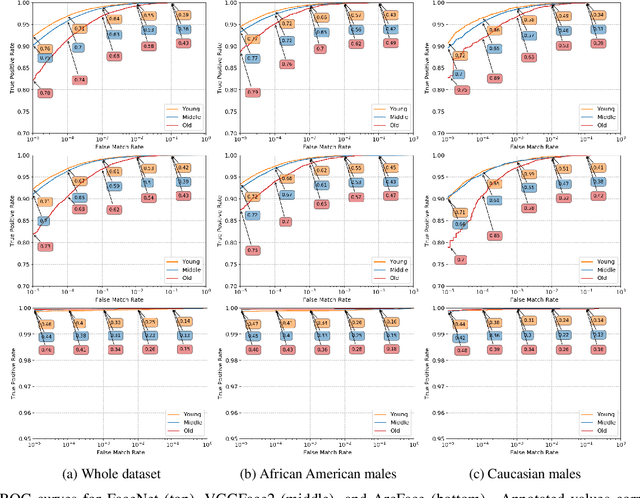

Previous studies generally agree that face recognition accuracy is higher for older persons than for younger persons. But most previous studies were before the wave of deep learning matchers, and most considered accuracy only in terms of the verification rate for genuine pairs. This paper investigates accuracy for age groups 16-29, 30-49 and 50-70, using three modern deep CNN matchers, and considers differences in the impostor and genuine distributions as well as verification rates and ROC curves. We find that accuracy is lower for older persons and higher for younger persons. In contrast, a pre deep learning matcher on the same dataset shows the traditional result of higher accuracy for older persons, although its overall accuracy is much lower than that of the deep learning matchers. Comparing the impostor and genuine distributions, we conclude that impostor scores have a larger effect than genuine scores in causing lower accuracy for the older age group. We also investigate the effects of training data across the age groups. Our results show that fine-tuning the deep CNN models on additional images of older persons actually lowers accuracy for the older age group. Also, we fine-tune and train from scratch two models using age-balanced training datasets, and these results also show lower accuracy for older age group. These results argue that the lower accuracy for the older age group is not due to imbalance in the original training data.
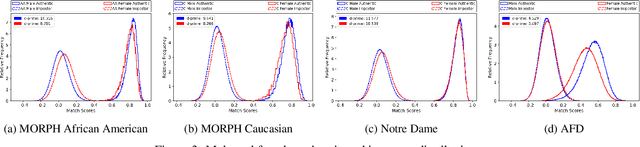
Characterizing the Variability in Face Recognition Accuracy Relative to Race
May 08, 2019
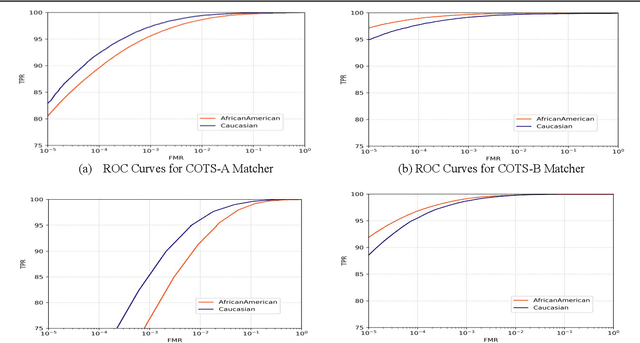
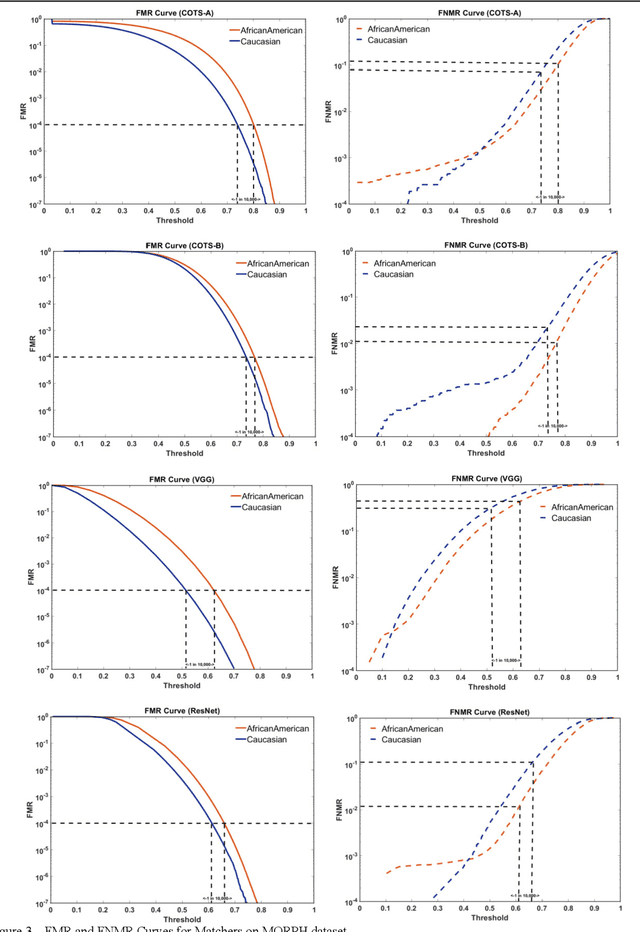
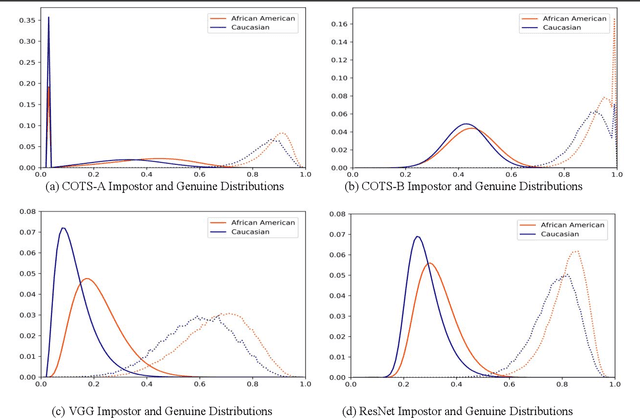
Many recent news headlines have labeled face recognition technology as biased or racist. We report on a methodical investigation into differences in face recognition accuracy between African-American and Caucasian image cohorts of the MORPH dataset. We find that, for all four matchers considered, the impostor and the genuine distributions are statistically significantly different between cohorts. For a fixed decision threshold, the African-American image cohort has a higher false match rate and a lower false non-match rate. ROC curves compare verification rates at the same false match rate, but the different cohorts achieve the same false match rate at different thresholds. This means that ROC comparisons are not relevant to operational scenarios that use a fixed decision threshold. We show that, for the ResNet matcher, the two cohorts have approximately equal separation of impostor and genuine distributions. Using ICAO compliance as a standard of image quality, we find that the initial image cohorts have unequal rates of good quality images. The ICAO-compliant subsets of the original image cohorts show improved accuracy, with the main effect being to reducing the low-similarity tail of the genuine distributions.