 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeepers & Pixels: Human Recognition Accuracy on Low Resolution Faces
Mar 25, 2025

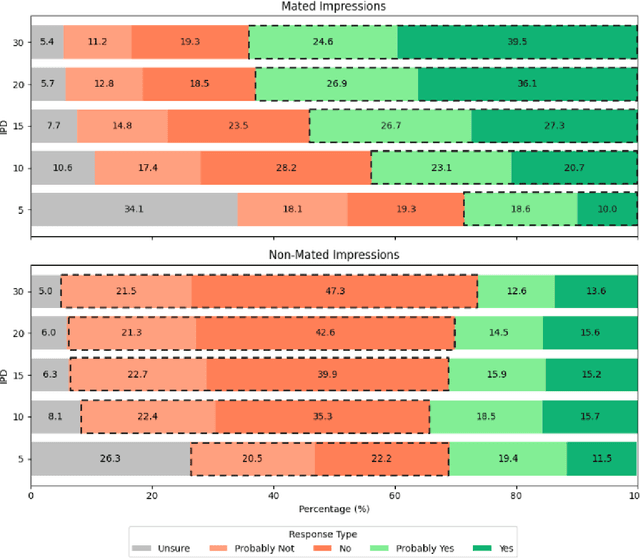
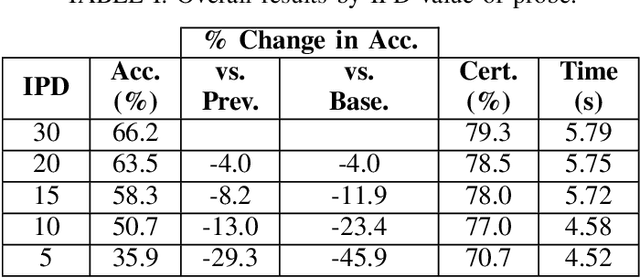
Automated one-to-many (1:N) face recognition is a powerful investigative tool commonly used by law enforcement agencies. In this context, potential matches resulting from automated 1:N recognition are reviewed by human examiners prior to possible use as investigative leads. While automated 1:N recognition can achieve near-perfect accuracy under ideal imaging conditions, operational scenarios may necessitate the use of surveillance imagery, which is often degraded in various quality dimensions. One important quality dimension is image resolution, typically quantified by the number of pixels on the face. The common metric for this is inter-pupillary distance (IPD), which measures the number of pixels between the pupils. Low IPD is known to degrade the accuracy of automated face recognition. However, the threshold IPD for reliability in human face recognition remains undefined. This study aims to explore the boundaries of human recognition accuracy by systematically testing accuracy across a range of IPD values. We find that at low IPDs (10px, 5px), human accuracy is at or below chance levels (50.7%, 35.9%), even as confidence in decision-making remains relatively high (77%, 70.7%). Our findings indicate that, for low IPD images, human recognition ability could be a limiting factor to overall system accuracy.
Lights, Camera, Matching: The Role of Image Illumination in Fair Face Recognition
Jan 15, 2025



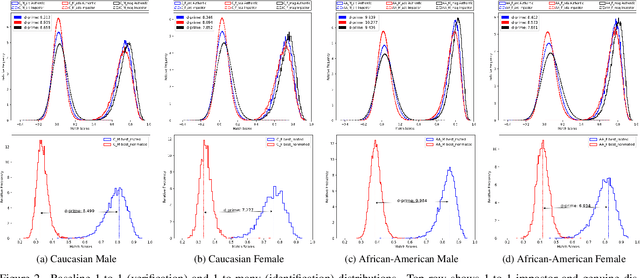
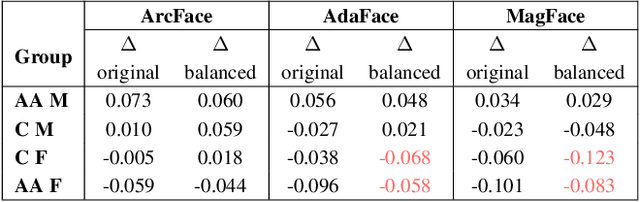
Facial brightness is a key image quality factor impacting face recognition accuracy differentials across demographic groups. In this work, we aim to decrease the accuracy gap between the similarity score distributions for Caucasian and African American female mated image pairs, as measured by d' between distributions. To balance brightness across demographic groups, we conduct three experiments, interpreting brightness in the face skin region either as median pixel value or as the distribution of pixel values. Balancing based on median brightness alone yields up to a 46.8% decrease in d', while balancing based on brightness distribution yields up to a 57.6% decrease. In all three cases, the similarity scores of the individual distributions improve, with mean scores maximally improving 5.9% for Caucasian females and 3.7% for African American females.
Demographic Disparities in 1-to-Many Facial Identification
Sep 08, 2023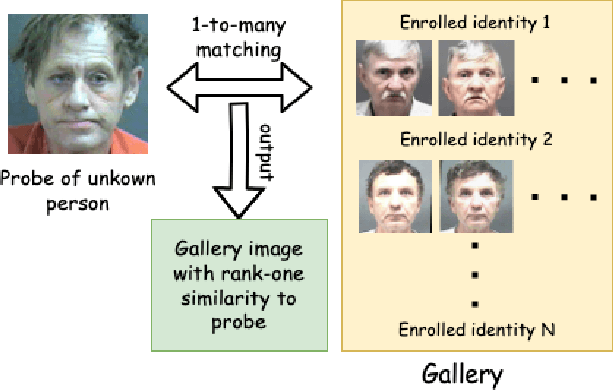
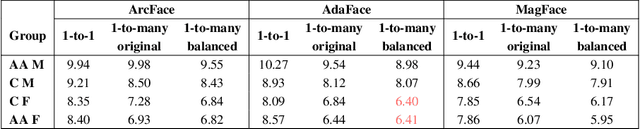
Most studies to date that have examined demographic variations in face recognition accuracy have analyzed 1-to-1 matching accuracy, using images that could be described as "government ID quality". This paper analyzes the accuracy of 1-to-many facial identification across demographic groups, and in the presence of blur and reduced resolution in the probe image as might occur in "surveillance camera quality" images. Cumulative match characteristic curves(CMC) are not appropriate for comparing propensity for rank-one recognition errors across demographics, and so we introduce three metrics for this: (1) d' metric between mated and non-mated score distributions, (2) absolute score difference between thresholds in the high-similarity tail of the non-mated and the low-similarity tail of the mated distribution, and (3) distribution of (mated - non-mated rank one scores) across the set of probe images. We find that demographic variation in 1-to-many accuracy does not entirely follow what has been observed in 1-to-1 matching accuracy. Also, different from 1-to-1 accuracy, demographic comparison of 1-to-many accuracy can be affected by different numbers of identities and images across demographics. Finally, we show that increased blur in the probe image, or reduced resolution of the face in the probe image, can significantly increase the false positive identification rate. And we show that the demographic variation in these high blur or low resolution conditions is much larger for male/ female than for African-American / Caucasian. The point that 1-to-many accuracy can potentially collapse in the context of processing "surveillance camera quality" probe images against a "government ID quality" gallery is an important one.
Analysis of Adversarial Image Manipulations
May 10, 2023



As virtual and physical identity grow increasingly intertwined, the importance of privacy and security in the online sphere becomes paramount. In recent years, multiple news stories have emerged of private companies scraping web content and doing research with or selling the data. Images uploaded online can be scraped without users' consent or knowledge. Users of social media platforms whose images are scraped may be at risk of being identified in other uploaded images or in real-world identification situations. This paper investigates how simple, accessible image manipulation techniques affect the accuracy of facial recognition software in identifying an individual's various face images based on one unique image.
Exploring Causes of Demographic Variations In Face Recognition Accuracy
Apr 14, 2023In recent years, media reports have called out bias and racism in face recognition technology. We review experimental results exploring several speculated causes for asymmetric cross-demographic performance. We consider accuracy differences as represented by variations in non-mated (impostor) and / or mated (genuine) distributions for 1-to-1 face matching. Possible causes explored include differences in skin tone, face size and shape, imbalance in number of identities and images in the training data, and amount of face visible in the test data ("face pixels"). We find that demographic differences in face pixel information of the test images appear to most directly impact the resultant differences in face recognition accuracy.