 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOur Deep CNN Face Matchers Have Developed Achromatopsia
Sep 11, 2023



Modern deep CNN face matchers are trained on datasets containing color images. We show that such matchers achieve essentially the same accuracy on the grayscale or the color version of a set of test images. We then consider possible causes for deep CNN face matchers ``not seeing color''. Popular web-scraped face datasets actually have 30 to 60\% of their identities with one or more grayscale images. We analyze whether this grayscale element in the training set impacts the accuracy achieved, and conclude that it does not. Further, we show that even with a 100\% grayscale training set, comparable accuracy is achieved on color or grayscale test images. Then we show that the skin region of an individual's images in a web-scraped training set exhibit significant variation in their mapping to color space. This suggests that color, at least for web-scraped, in-the-wild face datasets, carries limited identity-related information for training state-of-the-art matchers. Finally, we verify that comparable accuracy is achieved from training using single-channel grayscale images, implying that a larger dataset can be used within the same memory limit, with a less computationally intensive early layer.
Demographic Disparities in 1-to-Many Facial Identification
Sep 08, 2023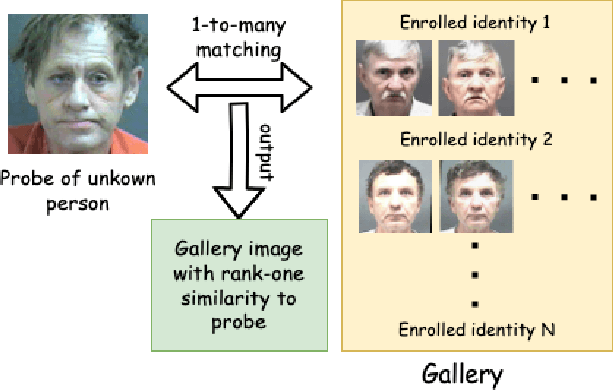
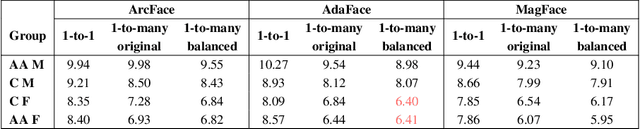
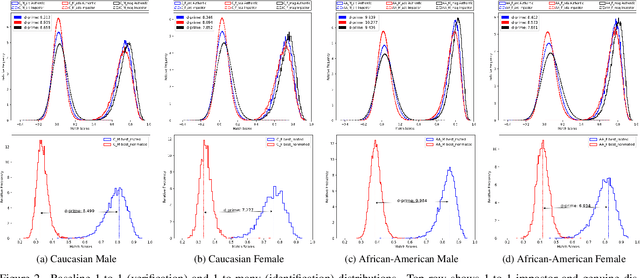
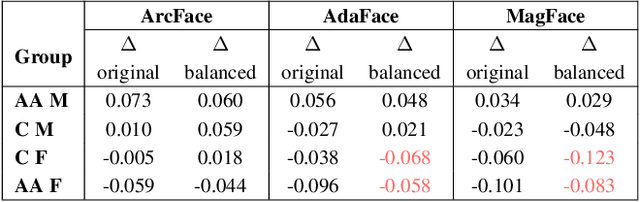
Most studies to date that have examined demographic variations in face recognition accuracy have analyzed 1-to-1 matching accuracy, using images that could be described as "government ID quality". This paper analyzes the accuracy of 1-to-many facial identification across demographic groups, and in the presence of blur and reduced resolution in the probe image as might occur in "surveillance camera quality" images. Cumulative match characteristic curves(CMC) are not appropriate for comparing propensity for rank-one recognition errors across demographics, and so we introduce three metrics for this: (1) d' metric between mated and non-mated score distributions, (2) absolute score difference between thresholds in the high-similarity tail of the non-mated and the low-similarity tail of the mated distribution, and (3) distribution of (mated - non-mated rank one scores) across the set of probe images. We find that demographic variation in 1-to-many accuracy does not entirely follow what has been observed in 1-to-1 matching accuracy. Also, different from 1-to-1 accuracy, demographic comparison of 1-to-many accuracy can be affected by different numbers of identities and images across demographics. Finally, we show that increased blur in the probe image, or reduced resolution of the face in the probe image, can significantly increase the false positive identification rate. And we show that the demographic variation in these high blur or low resolution conditions is much larger for male/ female than for African-American / Caucasian. The point that 1-to-many accuracy can potentially collapse in the context of processing "surveillance camera quality" probe images against a "government ID quality" gallery is an important one.