 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Casual Conversations v2 Dataset
Mar 08, 2023



This paper introduces a new large consent-driven dataset aimed at assisting in the evaluation of algorithmic bias and robustness of computer vision and audio speech models in regards to 11 attributes that are self-provided or labeled by trained annotators. The dataset includes 26,467 videos of 5,567 unique paid participants, with an average of almost 5 videos per person, recorded in Brazil, India, Indonesia, Mexico, Vietnam, Philippines, and the USA, representing diverse demographic characteristics. The participants agreed for their data to be used in assessing fairness of AI models and provided self-reported age, gender, language/dialect, disability status, physical adornments, physical attributes and geo-location information, while trained annotators labeled apparent skin tone using the Fitzpatrick Skin Type and Monk Skin Tone scales, and voice timbre. Annotators also labeled for different recording setups and per-second activity annotations.
You Only Need a Good Embeddings Extractor to Fix Spurious Correlations
Dec 12, 2022Spurious correlations in training data often lead to robustness issues since models learn to use them as shortcuts. For example, when predicting whether an object is a cow, a model might learn to rely on its green background, so it would do poorly on a cow on a sandy background. A standard dataset for measuring state-of-the-art on methods mitigating this problem is Waterbirds. The best method (Group Distributionally Robust Optimization - GroupDRO) currently achieves 89\% worst group accuracy and standard training from scratch on raw images only gets 72\%. GroupDRO requires training a model in an end-to-end manner with subgroup labels. In this paper, we show that we can achieve up to 90\% accuracy without using any sub-group information in the training set by simply using embeddings from a large pre-trained vision model extractor and training a linear classifier on top of it. With experiments on a wide range of pre-trained models and pre-training datasets, we show that the capacity of the pre-training model and the size of the pre-training dataset matters. Our experiments reveal that high capacity vision transformers perform better compared to high capacity convolutional neural networks, and larger pre-training dataset leads to better worst-group accuracy on the spurious correlation dataset.
Casual Conversations v2: Designing a large consent-driven dataset to measure algorithmic bias and robustness
Nov 10, 2022



Developing robust and fair AI systems require datasets with comprehensive set of labels that can help ensure the validity and legitimacy of relevant measurements. Recent efforts, therefore, focus on collecting person-related datasets that have carefully selected labels, including sensitive characteristics, and consent forms in place to use those attributes for model testing and development. Responsible data collection involves several stages, including but not limited to determining use-case scenarios, selecting categories (annotations) such that the data are fit for the purpose of measuring algorithmic bias for subgroups and most importantly ensure that the selected categories/subcategories are robust to regional diversities and inclusive of as many subgroups as possible. Meta, in a continuation of our efforts to measure AI algorithmic bias and robustness (https://ai.facebook.com/blog/shedding-light-on-fairness-in-ai-with-a-new-data-set), is working on collecting a large consent-driven dataset with a comprehensive list of categories. This paper describes our proposed design of such categories and subcategories for Casual Conversations v2.
The Gender Gap in Face Recognition Accuracy Is a Hairy Problem
Jun 10, 2022

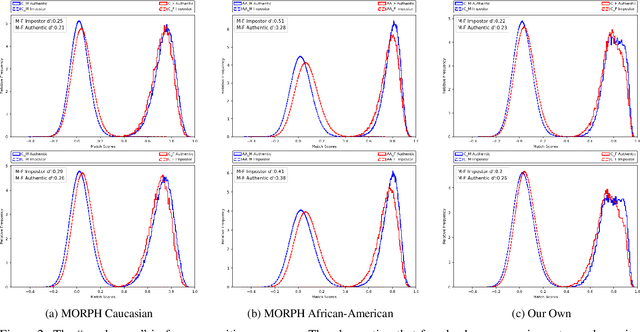
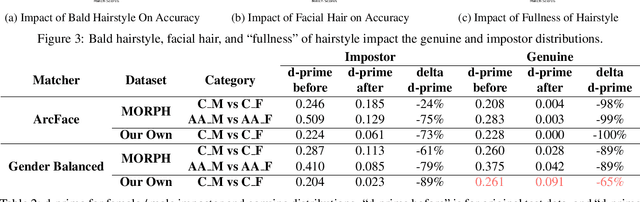
It is broadly accepted that there is a "gender gap" in face recognition accuracy, with females having higher false match and false non-match rates. However, relatively little is known about the cause(s) of this gender gap. Even the recent NIST report on demographic effects lists "analyze cause and effect" under "what we did not do". We first demonstrate that female and male hairstyles have important differences that impact face recognition accuracy. In particular, compared to females, male facial hair contributes to creating a greater average difference in appearance between different male faces. We then demonstrate that when the data used to estimate recognition accuracy is balanced across gender for how hairstyles occlude the face, the initially observed gender gap in accuracy largely disappears. We show this result for two different matchers, and analyzing images of Caucasians and of African-Americans. These results suggest that future research on demographic variation in accuracy should include a check for balanced quality of the test data as part of the problem formulation. To promote reproducible research, matchers, attribute classifiers, and datasets used in this research are/will be publicly available.
Face Recognition Accuracy Across Demographics: Shining a Light Into the Problem
Jun 04, 2022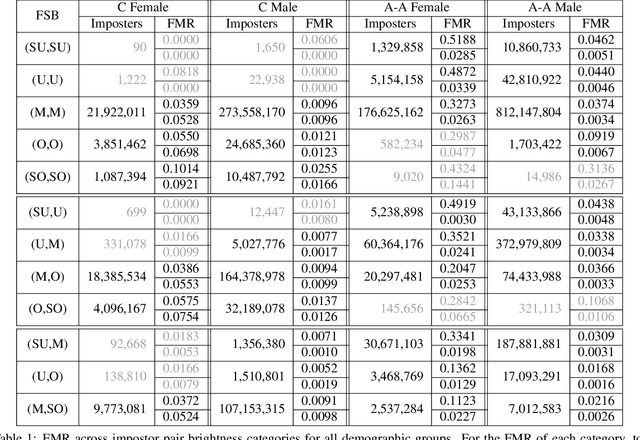

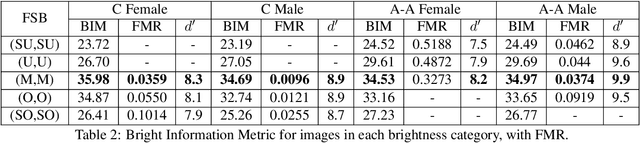
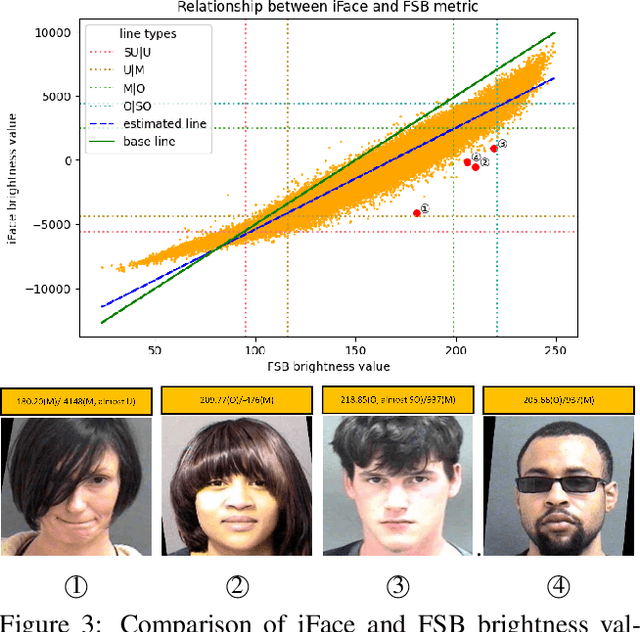
This is the first work that we are aware of to explore how the level of brightness of the skin region in a pair of face images impacts face recognition accuracy. Image pairs with both images having mean face skin brightness in an upper-middle range of brightness are found to have the highest matching accuracy across demographics and matchers. Image pairs with both images having mean face skin brightness that is too dark or too light are found to have an increased false match rate (FMR). Image pairs with strongly different face skin brightness are found to have decreased FMR and increased false non-match rate (FNMR). Using a brightness information metric that captures the variation in brightness in the face skin region, the variation in matching accuracy is shown to correlate with the level of information available in the face skin region. For operational scenarios where image acquisition is controlled, we propose acquiring images with lighting adjusted to yield face skin brightness in a narrow range.
Gendered Differences in Face Recognition Accuracy Explained by Hairstyles, Makeup, and Facial Morphology
Dec 29, 2021
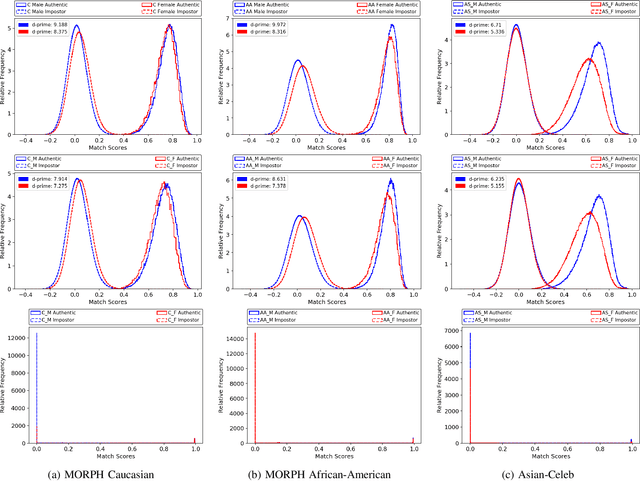
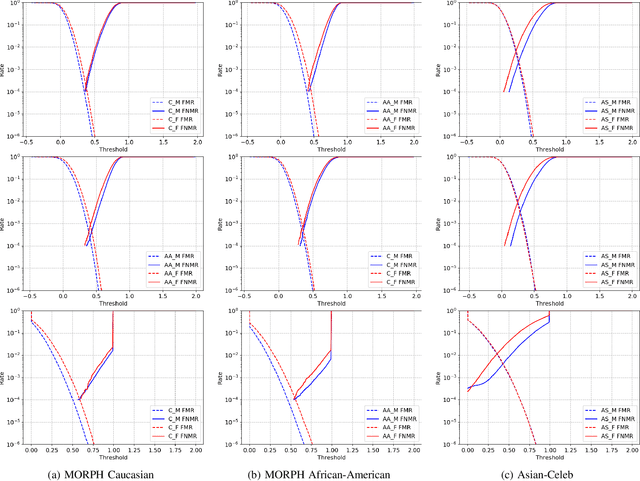
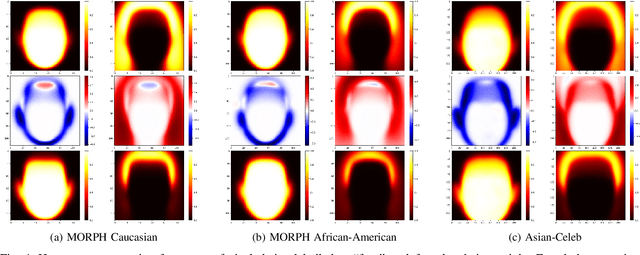
Media reports have accused face recognition of being ''biased'', ''sexist'' and ''racist''. There is consensus in the research literature that face recognition accuracy is lower for females, who often have both a higher false match rate and a higher false non-match rate. However, there is little published research aimed at identifying the cause of lower accuracy for females. For instance, the 2019 Face Recognition Vendor Test that documents lower female accuracy across a broad range of algorithms and datasets also lists ''Analyze cause and effect'' under the heading ''What we did not do''. We present the first experimental analysis to identify major causes of lower face recognition accuracy for females on datasets where previous research has observed this result. Controlling for equal amount of visible face in the test images mitigates the apparent higher false non-match rate for females. Additional analysis shows that makeup-balanced datasets further improves females to achieve lower false non-match rates. Finally, a clustering experiment suggests that images of two different females are inherently more similar than of two different males, potentially accounting for a difference in false match rates.
Does Face Recognition Error Echo Gender Classification Error?
Apr 28, 2021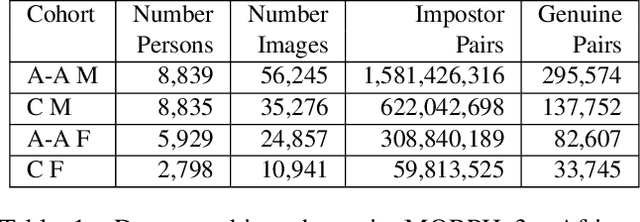

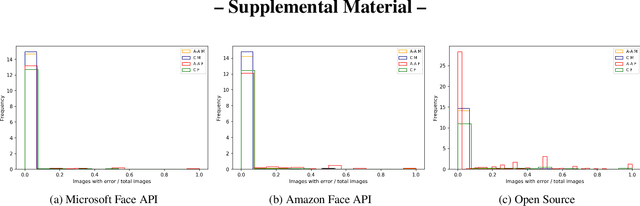
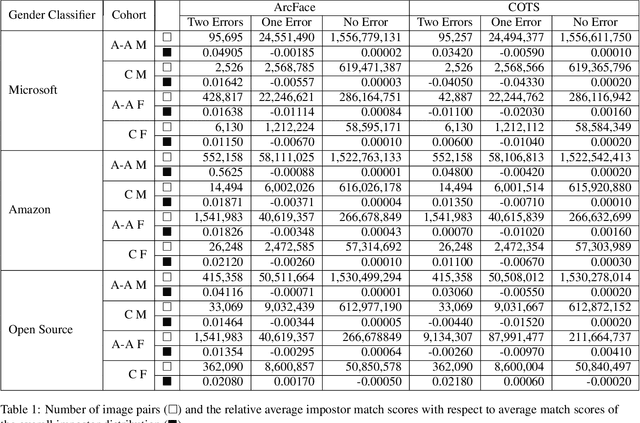
This paper is the first to explore the question of whether images that are classified incorrectly by a face analytics algorithm (e.g., gender classification) are any more or less likely to participate in an image pair that results in a face recognition error. We analyze results from three different gender classification algorithms (one open-source and two commercial), and two face recognition algorithms (one open-source and one commercial), on image sets representing four demographic groups (African-American female and male, Caucasian female and male). For impostor image pairs, our results show that pairs in which one image has a gender classification error have a better impostor distribution than pairs in which both images have correct gender classification, and so are less likely to generate a false match error. For genuine image pairs, our results show that individuals whose images have a mix of correct and incorrect gender classification have a worse genuine distribution (increased false non-match rate) compared to individuals whose images all have correct gender classification. Thus, compared to images that generate correct gender classification, images that generate gender classification errors do generate a different pattern of recognition errors, both better (false match) and worse (false non-match).
Is Face Recognition Sexist? No, Gendered Hairstyles and Biology Are
Aug 16, 2020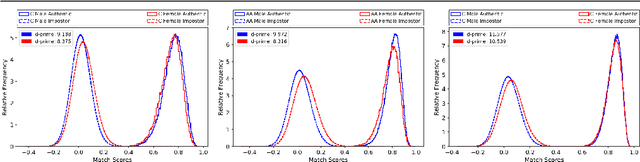

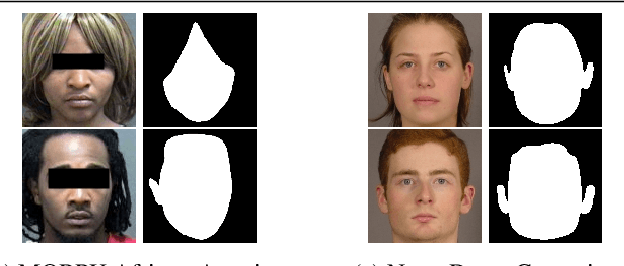
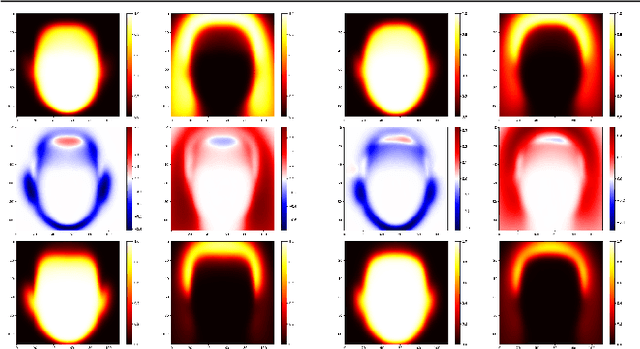
Recent news articles have accused face recognition of being "biased", "sexist" or "racist". There is consensus in the research literature that face recognition accuracy is lower for females, who often have both a higher false match rate and a higher false non-match rate. However, there is little published research aimed at identifying the cause of lower accuracy for females. For instance, the 2019 Face Recognition Vendor Test that documents lower female accuracy across a broad range of algorithms and datasets also lists "Analyze cause and effect" under the heading "What we did not do". We present the first experimental analysis to identify major causes of lower face recognition accuracy for females on datasets where previous research has observed this result. Controlling for equal amount of visible face in the test images reverses the apparent higher false non-match rate for females. Also, principal component analysis indicates that images of two different females are inherently more similar than of two different males, potentially accounting for a difference in false match rates.
A Method for Curation of Web-Scraped Face Image Datasets
Apr 07, 2020



Web-scraped, in-the-wild datasets have become the norm in face recognition research. The numbers of subjects and images acquired in web-scraped datasets are usually very large, with number of images on the millions scale. A variety of issues occur when collecting a dataset in-the-wild, including images with the wrong identity label, duplicate images, duplicate subjects and variation in quality. With the number of images being in the millions, a manual cleaning procedure is not feasible. But fully automated methods used to date result in a less-than-ideal level of clean dataset. We propose a semi-automated method, where the goal is to have a clean dataset for testing face recognition methods, with similar quality across men and women, to support comparison of accuracy across gender. Our approach removes near-duplicate images, merges duplicate subjects, corrects mislabeled images, and removes images outside a defined range of pose and quality. We conduct the curation on the Asian Face Dataset (AFD) and VGGFace2 test dataset. The experiments show that a state-of-the-art method achieves a much higher accuracy on the datasets after they are curated. Finally, we release our cleaned versions of both datasets to the research community.