 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction100M: A Large-scale Video Action Dataset
Jan 15, 2026Inferring physical actions from visual observations is a fundamental capability for advancing machine intelligence in the physical world. Achieving this requires large-scale, open-vocabulary video action datasets that span broad domains. We introduce Action100M, a large-scale dataset constructed from 1.2M Internet instructional videos (14.6 years of duration), yielding O(100 million) temporally localized segments with open-vocabulary action supervision and rich captions. Action100M is generated by a fully automated pipeline that (i) performs hierarchical temporal segmentation using V-JEPA 2 embeddings, (ii) produces multi-level frame and segment captions organized as a Tree-of-Captions, and (iii) aggregates evidence with a reasoning model (GPT-OSS-120B) under a multi-round Self-Refine procedure to output structured annotations (brief/detailed action, actor, brief/detailed caption). Training VL-JEPA on Action100M demonstrates consistent data-scaling improvements and strong zero-shot performance across diverse action recognition benchmarks, establishing Action100M as a new foundation for scalable research in video understanding and world modeling.
WorldPrediction: A Benchmark for High-level World Modeling and Long-horizon Procedural Planning
Jun 04, 2025Humans are known to have an internal "world model" that enables us to carry out action planning based on world states. AI agents need to have such a world model for action planning as well. It is not clear how current AI models, especially generative models, are able to learn such world models and carry out procedural planning in diverse environments. We introduce WorldPrediction, a video-based benchmark for evaluating world modeling and procedural planning capabilities of different AI models. In contrast to prior benchmarks that focus primarily on low-level world modeling and robotic motion planning, WorldPrediction is the first benchmark that emphasizes actions with temporal and semantic abstraction. Given initial and final world states, the task is to distinguish the proper action (WorldPrediction-WM) or the properly ordered sequence of actions (WorldPrediction-PP) from a set of counterfactual distractors. This discriminative task setup enable us to evaluate different types of world models and planners and realize a thorough comparison across different hypothesis. The benchmark represents states and actions using visual observations. In order to prevent models from exploiting low-level continuity cues in background scenes, we provide "action equivalents" - identical actions observed in different contexts - as candidates for selection. This benchmark is grounded in a formal framework of partially observable semi-MDP, ensuring better reliability and robustness of the evaluation. We conduct extensive human filtering and validation on our benchmark and show that current frontier models barely achieve 57% accuracy on WorldPrediction-WM and 38% on WorldPrediction-PP whereas humans are able to solve both tasks perfectly.
HalluLens: LLM Hallucination Benchmark
Apr 24, 2025



Large language models (LLMs) often generate responses that deviate from user input or training data, a phenomenon known as "hallucination." These hallucinations undermine user trust and hinder the adoption of generative AI systems. Addressing hallucinations is essential for the advancement of LLMs. This paper introduces a comprehensive hallucination benchmark, incorporating both new extrinsic and existing intrinsic evaluation tasks, built upon clear taxonomy of hallucination. A major challenge in benchmarking hallucinations is the lack of a unified framework due to inconsistent definitions and categorizations. We disentangle LLM hallucination from "factuality," proposing a clear taxonomy that distinguishes between extrinsic and intrinsic hallucinations, to promote consistency and facilitate research. Extrinsic hallucinations, where the generated content is not consistent with the training data, are increasingly important as LLMs evolve. Our benchmark includes dynamic test set generation to mitigate data leakage and ensure robustness against such leakage. We also analyze existing benchmarks, highlighting their limitations and saturation. The work aims to: (1) establish a clear taxonomy of hallucinations, (2) introduce new extrinsic hallucination tasks, with data that can be dynamically regenerated to prevent saturation by leakage, (3) provide a comprehensive analysis of existing benchmarks, distinguishing them from factuality evaluations.
Calibrating Verbal Uncertainty as a Linear Feature to Reduce Hallucinations
Mar 18, 2025



LLMs often adopt an assertive language style also when making false claims. Such ``overconfident hallucinations'' mislead users and erode trust. Achieving the ability to express in language the actual degree of uncertainty around a claim is therefore of great importance. We find that ``verbal uncertainty'' is governed by a single linear feature in the representation space of LLMs, and show that this has only moderate correlation with the actual ``semantic uncertainty'' of the model. We apply this insight and show that (1) the mismatch between semantic and verbal uncertainty is a better predictor of hallucinations than semantic uncertainty alone and (2) we can intervene on verbal uncertainty at inference time and reduce hallucinations on short-form answers, achieving an average relative reduction of 32%.
LLM Internal States Reveal Hallucination Risk Faced With a Query
Jul 03, 2024The hallucination problem of Large Language Models (LLMs) significantly limits their reliability and trustworthiness. Humans have a self-awareness process that allows us to recognize what we don't know when faced with queries. Inspired by this, our paper investigates whether LLMs can estimate their own hallucination risk before response generation. We analyze the internal mechanisms of LLMs broadly both in terms of training data sources and across 15 diverse Natural Language Generation (NLG) tasks, spanning over 700 datasets. Our empirical analysis reveals two key insights: (1) LLM internal states indicate whether they have seen the query in training data or not; and (2) LLM internal states show they are likely to hallucinate or not regarding the query. Our study explores particular neurons, activation layers, and tokens that play a crucial role in the LLM perception of uncertainty and hallucination risk. By a probing estimator, we leverage LLM self-assessment, achieving an average hallucination estimation accuracy of 84.32\% at run time.
The Pyramid of Captions
May 01, 2024We introduce a formal information-theoretic framework for image captioning by regarding it as a representation learning task. Our framework defines three key objectives: task sufficiency, minimal redundancy, and human interpretability. Building upon this foundation, we propose a novel Pyramid of Captions (PoCa) method, which constructs caption pyramids by generating localized captions for zoomed-in image patches and integrating them with global caption information using large language models. This approach leverages intuition that the detailed examination of local patches can reduce error risks and address inaccuracies in global captions, either by correcting the hallucination or adding missing details. Based on our theoretical framework, we formalize this intuition and provide formal proof demonstrating the effectiveness of PoCa under certain assumptions. Empirical tests with various image captioning models and large language models show that PoCa consistently yields more informative and semantically aligned captions, maintaining brevity and interpretability.
High-Dimension Human Value Representation in Large Language Models
Apr 11, 2024



The widespread application of Large Language Models (LLMs) across various tasks and fields has necessitated the alignment of these models with human values and preferences. Given various approaches of human value alignment, ranging from Reinforcement Learning with Human Feedback (RLHF), to constitutional learning, etc. there is an urgent need to understand the scope and nature of human values injected into these models before their release. There is also a need for model alignment without a costly large scale human annotation effort. We propose UniVaR, a high-dimensional representation of human value distributions in LLMs, orthogonal to model architecture and training data. Trained from the value-relevant output of eight multilingual LLMs and tested on the output from four multilingual LLMs, namely LlaMA2, ChatGPT, JAIS and Yi, we show that UniVaR is a powerful tool to compare the distribution of human values embedded in different LLMs with different langauge sources. Through UniVaR, we explore how different LLMs prioritize various values in different languages and cultures, shedding light on the complex interplay between human values and language modeling.
Measuring Political Bias in Large Language Models: What Is Said and How It Is Said
Mar 27, 2024

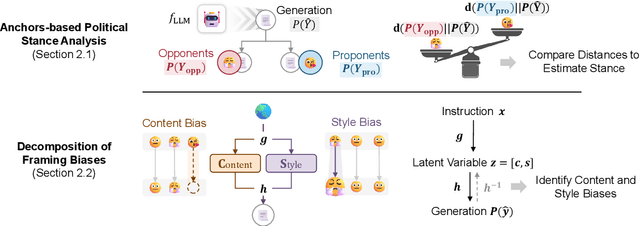

We propose to measure political bias in LLMs by analyzing both the content and style of their generated content regarding political issues. Existing benchmarks and measures focus on gender and racial biases. However, political bias exists in LLMs and can lead to polarization and other harms in downstream applications. In order to provide transparency to users, we advocate that there should be fine-grained and explainable measures of political biases generated by LLMs. Our proposed measure looks at different political issues such as reproductive rights and climate change, at both the content (the substance of the generation) and the style (the lexical polarity) of such bias. We measured the political bias in eleven open-sourced LLMs and showed that our proposed framework is easily scalable to other topics and is explainable.
Mitigating Framing Bias with Polarity Minimization Loss
Nov 03, 2023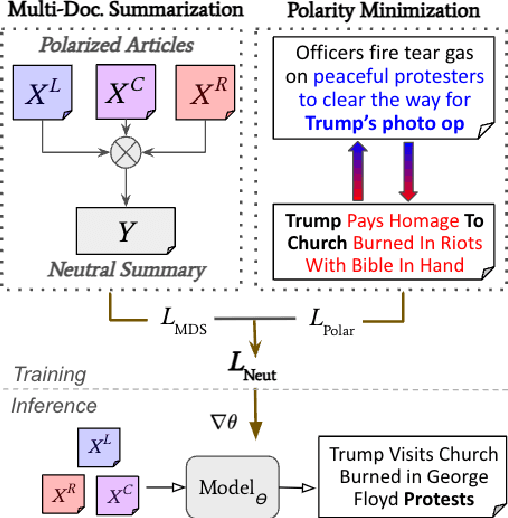
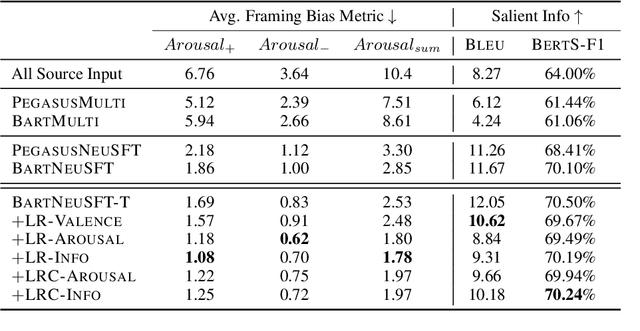

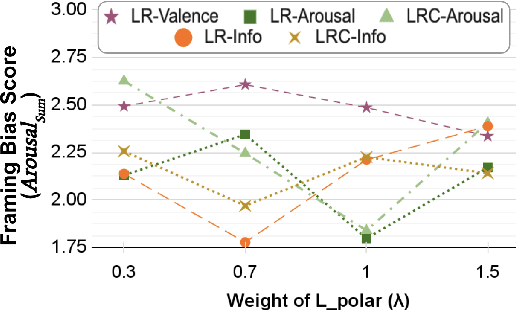
Framing bias plays a significant role in exacerbating political polarization by distorting the perception of actual events. Media outlets with divergent political stances often use polarized language in their reporting of the same event. We propose a new loss function that encourages the model to minimize the polarity difference between the polarized input articles to reduce framing bias. Specifically, our loss is designed to jointly optimize the model to map polarity ends bidirectionally. Our experimental results demonstrate that incorporating the proposed polarity minimization loss leads to a substantial reduction in framing bias when compared to a BART-based multi-document summarization model. Notably, we find that the effectiveness of this approach is most pronounced when the model is trained to minimize the polarity loss associated with informational framing bias (i.e., skewed selection of information to report).
Survey of Social Bias in Vision-Language Models
Sep 24, 2023In recent years, the rapid advancement of machine learning (ML) models, particularly transformer-based pre-trained models, has revolutionized Natural Language Processing (NLP) and Computer Vision (CV) fields. However, researchers have discovered that these models can inadvertently capture and reinforce social biases present in their training datasets, leading to potential social harms, such as uneven resource allocation and unfair representation of specific social groups. Addressing these biases and ensuring fairness in artificial intelligence (AI) systems has become a critical concern in the ML community. The recent introduction of pre-trained vision-and-language (VL) models in the emerging multimodal field demands attention to the potential social biases present in these models as well. Although VL models are susceptible to social bias, there is a limited understanding compared to the extensive discussions on bias in NLP and CV. This survey aims to provide researchers with a high-level insight into the similarities and differences of social bias studies in pre-trained models across NLP, CV, and VL. By examining these perspectives, the survey aims to offer valuable guidelines on how to approach and mitigate social bias in both unimodal and multimodal settings. The findings and recommendations presented here can benefit the ML community, fostering the development of fairer and non-biased AI models in various applications and research endeavors.