 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction100M: A Large-scale Video Action Dataset
Jan 15, 2026Inferring physical actions from visual observations is a fundamental capability for advancing machine intelligence in the physical world. Achieving this requires large-scale, open-vocabulary video action datasets that span broad domains. We introduce Action100M, a large-scale dataset constructed from 1.2M Internet instructional videos (14.6 years of duration), yielding O(100 million) temporally localized segments with open-vocabulary action supervision and rich captions. Action100M is generated by a fully automated pipeline that (i) performs hierarchical temporal segmentation using V-JEPA 2 embeddings, (ii) produces multi-level frame and segment captions organized as a Tree-of-Captions, and (iii) aggregates evidence with a reasoning model (GPT-OSS-120B) under a multi-round Self-Refine procedure to output structured annotations (brief/detailed action, actor, brief/detailed caption). Training VL-JEPA on Action100M demonstrates consistent data-scaling improvements and strong zero-shot performance across diverse action recognition benchmarks, establishing Action100M as a new foundation for scalable research in video understanding and world modeling.
VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
Dec 11, 2025We introduce VL-JEPA, a vision-language model built on a Joint Embedding Predictive Architecture (JEPA). Instead of autoregressively generating tokens as in classical VLMs, VL-JEPA predicts continuous embeddings of the target texts. By learning in an abstract representation space, the model focuses on task-relevant semantics while abstracting away surface-level linguistic variability. In a strictly controlled comparison against standard token-space VLM training with the same vision encoder and training data, VL-JEPA achieves stronger performance while having 50% fewer trainable parameters. At inference time, a lightweight text decoder is invoked only when needed to translate VL-JEPA predicted embeddings into text. We show that VL-JEPA natively supports selective decoding that reduces the number of decoding operations by 2.85x while maintaining similar performance compared to non-adaptive uniform decoding. Beyond generation, the VL-JEPA's embedding space naturally supports open-vocabulary classification, text-to-video retrieval, and discriminative VQA without any architecture modification. On eight video classification and eight video retrieval datasets, the average performance VL-JEPA surpasses that of CLIP, SigLIP2, and Perception Encoder. At the same time, the model achieves comparable performance as classical VLMs (InstructBLIP, QwenVL) on four VQA datasets: GQA, TallyQA, POPE and POPEv2, despite only having 1.6B parameters.
WorldPrediction: A Benchmark for High-level World Modeling and Long-horizon Procedural Planning
Jun 04, 2025Humans are known to have an internal "world model" that enables us to carry out action planning based on world states. AI agents need to have such a world model for action planning as well. It is not clear how current AI models, especially generative models, are able to learn such world models and carry out procedural planning in diverse environments. We introduce WorldPrediction, a video-based benchmark for evaluating world modeling and procedural planning capabilities of different AI models. In contrast to prior benchmarks that focus primarily on low-level world modeling and robotic motion planning, WorldPrediction is the first benchmark that emphasizes actions with temporal and semantic abstraction. Given initial and final world states, the task is to distinguish the proper action (WorldPrediction-WM) or the properly ordered sequence of actions (WorldPrediction-PP) from a set of counterfactual distractors. This discriminative task setup enable us to evaluate different types of world models and planners and realize a thorough comparison across different hypothesis. The benchmark represents states and actions using visual observations. In order to prevent models from exploiting low-level continuity cues in background scenes, we provide "action equivalents" - identical actions observed in different contexts - as candidates for selection. This benchmark is grounded in a formal framework of partially observable semi-MDP, ensuring better reliability and robustness of the evaluation. We conduct extensive human filtering and validation on our benchmark and show that current frontier models barely achieve 57% accuracy on WorldPrediction-WM and 38% on WorldPrediction-PP whereas humans are able to solve both tasks perfectly.
Contrastive Learning for Inference in Dialogue
Oct 19, 2023Inference, especially those derived from inductive processes, is a crucial component in our conversation to complement the information implicitly or explicitly conveyed by a speaker. While recent large language models show remarkable advances in inference tasks, their performance in inductive reasoning, where not all information is present in the context, is far behind deductive reasoning. In this paper, we analyze the behavior of the models based on the task difficulty defined by the semantic information gap -- which distinguishes inductive and deductive reasoning (Johnson-Laird, 1988, 1993). Our analysis reveals that the disparity in information between dialogue contexts and desired inferences poses a significant challenge to the inductive inference process. To mitigate this information gap, we investigate a contrastive learning approach by feeding negative samples. Our experiments suggest negative samples help models understand what is wrong and improve their inference generations.
InstructTODS: Large Language Models for End-to-End Task-Oriented Dialogue Systems
Oct 13, 2023Large language models (LLMs) have been used for diverse tasks in natural language processing (NLP), yet remain under-explored for task-oriented dialogue systems (TODS), especially for end-to-end TODS. We present InstructTODS, a novel off-the-shelf framework for zero-shot end-to-end task-oriented dialogue systems that can adapt to diverse domains without fine-tuning. By leveraging LLMs, InstructTODS generates a proxy belief state that seamlessly translates user intentions into dynamic queries for efficient interaction with any KB. Our extensive experiments demonstrate that InstructTODS achieves comparable performance to fully fine-tuned TODS in guiding dialogues to successful completion without prior knowledge or task-specific data. Furthermore, a rigorous human evaluation of end-to-end TODS shows that InstructTODS produces dialogue responses that notably outperform both the gold responses and the state-of-the-art TODS in terms of helpfulness, informativeness, and humanness. Moreover, the effectiveness of LLMs in TODS is further supported by our comprehensive evaluations on TODS subtasks: dialogue state tracking, intent classification, and response generation. Code and implementations could be found here https://github.com/WillyHC22/InstructTODS/
PICK: Polished & Informed Candidate Scoring for Knowledge-Grounded Dialogue Systems
Sep 19, 2023Grounding dialogue response generation on external knowledge is proposed to produce informative and engaging responses. However, current knowledge-grounded dialogue (KGD) systems often fail to align the generated responses with human-preferred qualities due to several issues like hallucination and the lack of coherence. Upon analyzing multiple language model generations, we observe the presence of alternative generated responses within a single decoding process. These alternative responses are more faithful and exhibit a comparable or higher level of relevance to prior conversational turns compared to the optimal responses prioritized by the decoding processes. To address these challenges and driven by these observations, we propose Polished \& Informed Candidate Scoring (PICK), a generation re-scoring framework that empowers models to generate faithful and relevant responses without requiring additional labeled data or model tuning. Through comprehensive automatic and human evaluations, we demonstrate the effectiveness of PICK in generating responses that are more faithful while keeping them relevant to the dialogue history. Furthermore, PICK consistently improves the system's performance with both oracle and retrieved knowledge in all decoding strategies. We provide the detailed implementation in https://github.com/bryanwilie/pick .
Cross-Lingual Cross-Age Group Adaptation for Low-Resource Elderly Speech Emotion Recognition
Jun 26, 2023Speech emotion recognition plays a crucial role in human-computer interactions. However, most speech emotion recognition research is biased toward English-speaking adults, which hinders its applicability to other demographic groups in different languages and age groups. In this work, we analyze the transferability of emotion recognition across three different languages--English, Mandarin Chinese, and Cantonese; and 2 different age groups--adults and the elderly. To conduct the experiment, we develop an English-Mandarin speech emotion benchmark for adults and the elderly, BiMotion, and a Cantonese speech emotion dataset, YueMotion. This study concludes that different language and age groups require specific speech features, thus making cross-lingual inference an unsuitable method. However, cross-group data augmentation is still beneficial to regularize the model, with linguistic distance being a significant influence on cross-lingual transferability. We release publicly release our code at https://github.com/HLTCHKUST/elderly_ser.
Instruct-Align: Teaching Novel Languages with to LLMs through Alignment-based Cross-Lingual Instruction
May 23, 2023Instruction-tuned large language models (LLMs) have shown remarkable generalization capability over multiple tasks in multiple languages. Nevertheless, their generalization towards different languages varies especially to underrepresented languages or even to unseen languages. Prior works on adapting new languages to LLMs find that naively adapting new languages to instruction-tuned LLMs will result in catastrophic forgetting, which in turn causes the loss of multitasking ability in these LLMs. To tackle this, we propose the Instruct-Align a.k.a (IA)$^1$ framework, which enables instruction-tuned LLMs to learn cross-lingual alignment between unseen and previously learned languages via alignment-based cross-lingual instruction-tuning. Our preliminary result on BLOOMZ-560M shows that (IA)$^1$ is able to learn a new language effectively with only a limited amount of parallel data and at the same time prevent catastrophic forgetting by applying continual instruction-tuning through experience replay. Our work contributes to the progression of language adaptation methods for instruction-tuned LLMs and opens up the possibility of adapting underrepresented low-resource languages into existing instruction-tuned LLMs. Our code will be publicly released upon acceptance.
Learn What NOT to Learn: Towards Generative Safety in Chatbots
Apr 25, 2023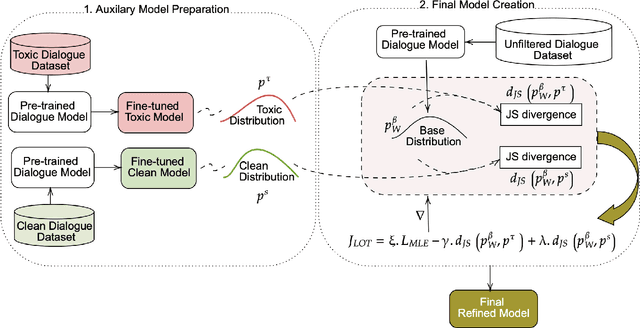



Conversational models that are generative and open-domain are particularly susceptible to generating unsafe content since they are trained on web-based social data. Prior approaches to mitigating this issue have drawbacks, such as disrupting the flow of conversation, limited generalization to unseen toxic input contexts, and sacrificing the quality of the dialogue for the sake of safety. In this paper, we present a novel framework, named "LOT" (Learn NOT to), that employs a contrastive loss to enhance generalization by learning from both positive and negative training signals. Our approach differs from the standard contrastive learning framework in that it automatically obtains positive and negative signals from the safe and unsafe language distributions that have been learned beforehand. The LOT framework utilizes divergence to steer the generations away from the unsafe subspace and towards the safe subspace while sustaining the flow of conversation. Our approach is memory and time-efficient during decoding and effectively reduces toxicity while preserving engagingness and fluency. Empirical results indicate that LOT reduces toxicity by up to four-fold while achieving four to six-fold higher rates of engagingness and fluency compared to baseline models. Our findings are further corroborated by human evaluation.
A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity
Feb 28, 2023



This paper proposes a framework for quantitatively evaluating interactive LLMs such as ChatGPT using publicly available data sets. We carry out an extensive technical evaluation of ChatGPT using 23 data sets covering 8 different common NLP application tasks. We evaluate the multitask, multilingual and multi-modal aspects of ChatGPT based on these data sets and a newly designed multimodal dataset. We find that ChatGPT outperforms LLMs with zero-shot learning on most tasks and even outperforms fine-tuned models on some tasks. We find that it is better at understanding non-Latin script languages than generating them. It is able to generate multimodal content from textual prompts, via an intermediate code generation step. Moreover, we find that ChatGPT is 63.41% accurate on average in 10 different reasoning categories under logical reasoning, non-textual reasoning, and commonsense reasoning, hence making it an unreliable reasoner. It is, for example, better at deductive than inductive reasoning. ChatGPT suffers from hallucination problems like other LLMs and it generates more extrinsic hallucinations from its parametric memory as it does not have access to an external knowledge base. Finally, the interactive feature of ChatGPT enables human collaboration with the underlying LLM to improve its performance, i.e, 8% ROUGE-1 on summarization and 2% ChrF++ on machine translation, in a multi-turn "prompt engineering" fashion. We also release codebase for evaluation set extraction.