 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Verbal Uncertainty as a Linear Feature to Reduce Hallucinations
Mar 18, 2025



LLMs often adopt an assertive language style also when making false claims. Such ``overconfident hallucinations'' mislead users and erode trust. Achieving the ability to express in language the actual degree of uncertainty around a claim is therefore of great importance. We find that ``verbal uncertainty'' is governed by a single linear feature in the representation space of LLMs, and show that this has only moderate correlation with the actual ``semantic uncertainty'' of the model. We apply this insight and show that (1) the mismatch between semantic and verbal uncertainty is a better predictor of hallucinations than semantic uncertainty alone and (2) we can intervene on verbal uncertainty at inference time and reduce hallucinations on short-form answers, achieving an average relative reduction of 32%.
An Exploration of Conditioning Methods in Graph Neural Networks
May 03, 2023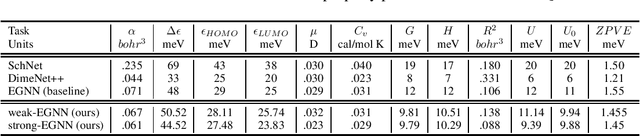

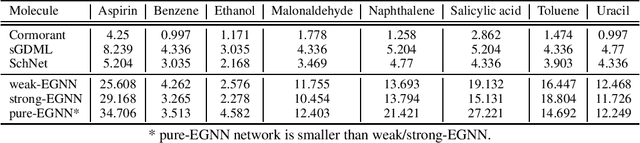
The flexibility and effectiveness of message passing based graph neural networks (GNNs) induced considerable advances in deep learning on graph-structured data. In such approaches, GNNs recursively update node representations based on their neighbors and they gain expressivity through the use of node and edge attribute vectors. E.g., in computational tasks such as physics and chemistry usage of edge attributes such as relative position or distance proved to be essential. In this work, we address not what kind of attributes to use, but how to condition on this information to improve model performance. We consider three types of conditioning; weak, strong, and pure, which respectively relate to concatenation-based conditioning, gating, and transformations that are causally dependent on the attributes. This categorization provides a unifying viewpoint on different classes of GNNs, from separable convolutions to various forms of message passing networks. We provide an empirical study on the effect of conditioning methods in several tasks in computational chemistry.
Reducing Over-smoothing in Graph Neural Networks Using Relational Embeddings
Jan 07, 2023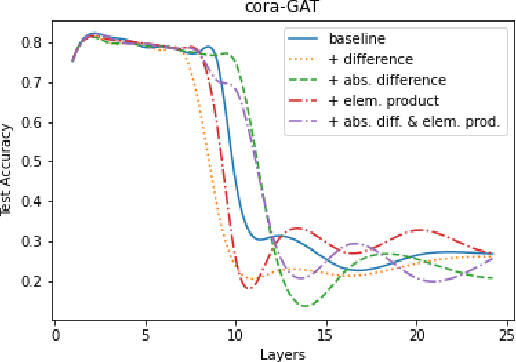
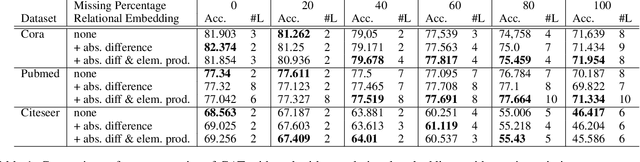
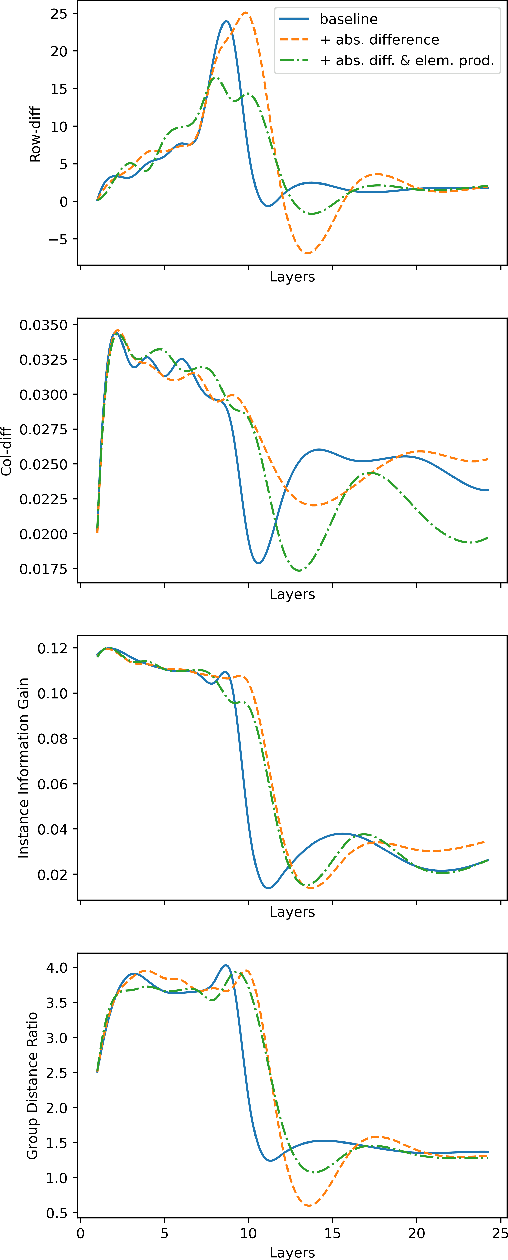

Graph Neural Networks (GNNs) have achieved a lot of success with graph-structured data. However, it is observed that the performance of GNNs does not improve (or even worsen) as the number of layers increases. This effect has known as over-smoothing, which means that the representations of the graph nodes of different classes would become indistinguishable when stacking multiple layers. In this work, we propose a new simple, and efficient method to alleviate the effect of the over-smoothing problem in GNNs by explicitly using relations between node embeddings. Experiments on real-world datasets demonstrate that utilizing node embedding relations makes GNN models such as Graph Attention Network more robust to over-smoothing and achieves better performance with deeper GNNs. Our method can be used in combination with other methods to give the best performance. GNN applications are endless and depend on the user's objective and the type of data that they possess. Solving over-smoothing issues can potentially improve the performance of models on all these tasks.
Memory-efficient NLLB-200: Language-specific Expert Pruning of a Massively Multilingual Machine Translation Model
Dec 19, 2022Compared to conventional bilingual translation systems, massively multilingual machine translation is appealing because a single model can translate into multiple languages and benefit from knowledge transfer for low resource languages. On the other hand, massively multilingual models suffer from the curse of multilinguality, unless scaling their size massively, which increases their training and inference costs. Sparse Mixture-of-Experts models are a way to drastically increase model capacity without the need for a proportional amount of computing. The recently released NLLB-200 is an example of such a model. It covers 202 languages but requires at least four 32GB GPUs just for inference. In this work, we propose a pruning method that allows the removal of up to 80\% of experts with a negligible loss in translation quality, which makes it feasible to run the model on a single 32GB GPU. Further analysis suggests that our pruning metrics allow to identify language-specific experts and prune non-relevant experts for a given language pair.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
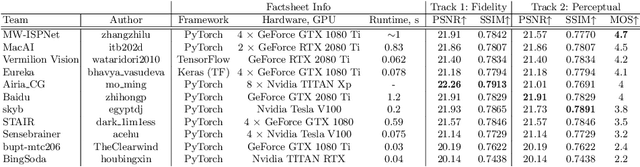
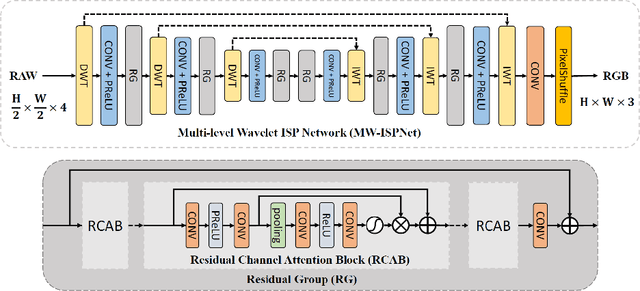
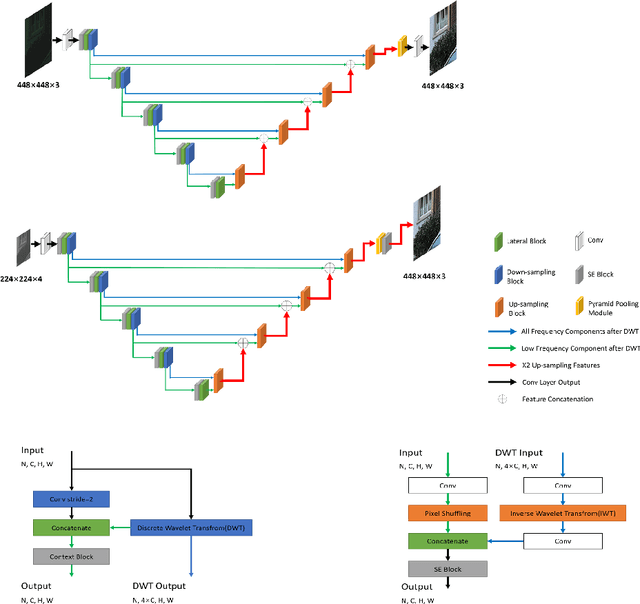
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.