 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Reasoning Capability on Machine Translation in Large Language Models
Feb 16, 2026Reasoning-oriented large language models (RLMs) achieve strong gains on tasks such as mathematics and coding by generating explicit intermediate reasoning. However, their impact on machine translation (MT) remains underexplored. We systematically evaluate several open- and closed-weights RLMs on the WMT24++ benchmark and find that enabling explicit reasoning consistently degrades translation quality across languages and models. Analysis reveals that MT reasoning traces are highly linear, lacking revision, self-correction and exploration of alternative translations, which limits their usefulness. Furthermore, injecting higher-quality reasoning traces from stronger models does not reliably improve weaker models' performance. To address this mismatch, we propose a structured reasoning framework tailored to translation, based on multi-step drafting, adequacy refinement, fluency improvement, and selective iterative revision. We curate a synthetic dataset of dynamic structured reasoning traces and post-train a large reasoning model on this data. Experiments show significant improvements over standard translation fine-tuning and injected generic reasoning baselines. Our findings demonstrate that reasoning must be task-structured to benefit MT.
NAVER LABS Europe's Multilingual Speech Translation Systems for the IWSLT 2023 Low-Resource Track
Jun 13, 2023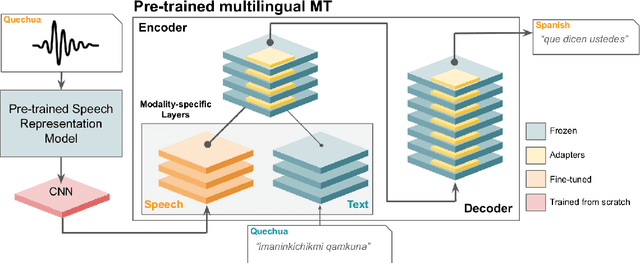
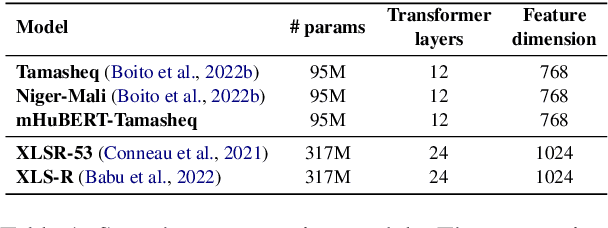
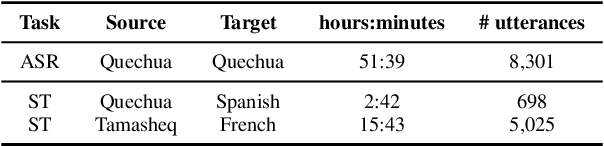
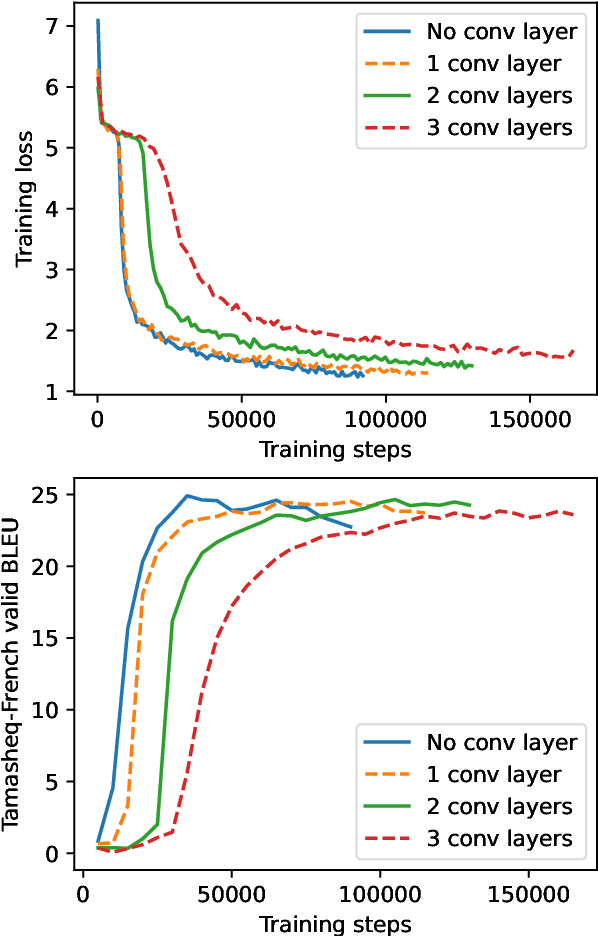
This paper presents NAVER LABS Europe's systems for Tamasheq-French and Quechua-Spanish speech translation in the IWSLT 2023 Low-Resource track. Our work attempts to maximize translation quality in low-resource settings using multilingual parameter-efficient solutions that leverage strong pre-trained models. Our primary submission for Tamasheq outperforms the previous state of the art by 7.5 BLEU points on the IWSLT 2022 test set, and achieves 23.6 BLEU on this year's test set, outperforming the second best participant by 7.7 points. For Quechua, we also rank first and achieve 17.7 BLEU, despite having only two hours of translation data. Finally, we show that our proposed multilingual architecture is also competitive for high-resource languages, outperforming the best unconstrained submission to the IWSLT 2021 Multilingual track, despite using much less training data and compute.
Memory-efficient NLLB-200: Language-specific Expert Pruning of a Massively Multilingual Machine Translation Model
Dec 19, 2022Compared to conventional bilingual translation systems, massively multilingual machine translation is appealing because a single model can translate into multiple languages and benefit from knowledge transfer for low resource languages. On the other hand, massively multilingual models suffer from the curse of multilinguality, unless scaling their size massively, which increases their training and inference costs. Sparse Mixture-of-Experts models are a way to drastically increase model capacity without the need for a proportional amount of computing. The recently released NLLB-200 is an example of such a model. It covers 202 languages but requires at least four 32GB GPUs just for inference. In this work, we propose a pruning method that allows the removal of up to 80\% of experts with a negligible loss in translation quality, which makes it feasible to run the model on a single 32GB GPU. Further analysis suggests that our pruning metrics allow to identify language-specific experts and prune non-relevant experts for a given language pair.
What Do Compressed Multilingual Machine Translation Models Forget?
May 22, 2022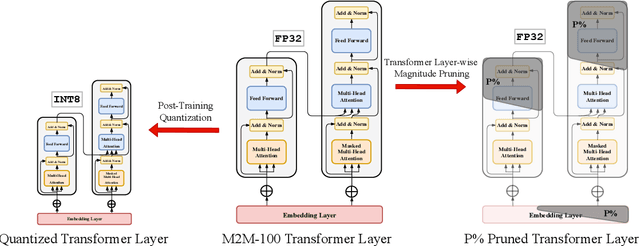

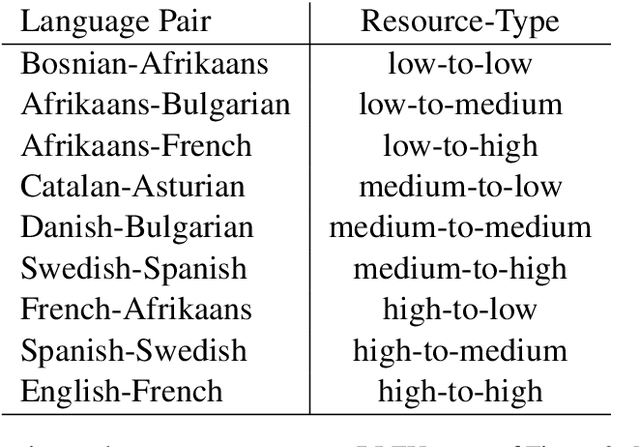
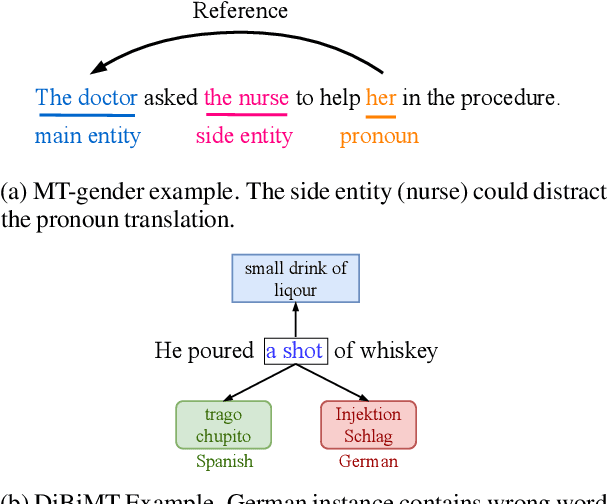
Recently, very large pre-trained models achieve state-of-the-art results in various natural language processing (NLP) tasks, but their size makes it more challenging to apply them in resource-constrained environments. Compression techniques allow to drastically reduce the size of the model and therefore its inference time with negligible impact on top-tier metrics. However, the general performance hides a drastic performance drop on under-represented features, which could result in the amplification of biases encoded by the model. In this work, we analyze the impacts of compression methods on Multilingual Neural Machine Translation models (MNMT) for various language groups and semantic features by extensive analysis of compressed models on different NMT benchmarks, e.g. FLORES-101, MT-Gender, and DiBiMT. Our experiments show that the performance of under-represented languages drops significantly, while the average BLEU metric slightly decreases. Interestingly, the removal of noisy memorization with the compression leads to a significant improvement for some medium-resource languages. Finally, we demonstrate that the compression amplifies intrinsic gender and semantic biases, even in high-resource languages.
Continual Learning in Multilingual NMT via Language-Specific Embeddings
Oct 20, 2021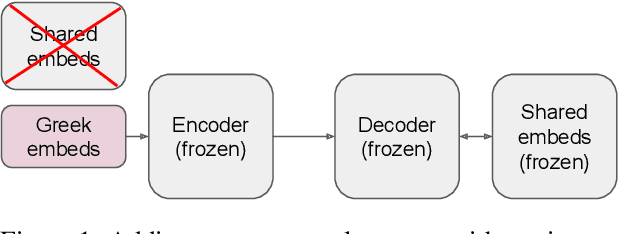
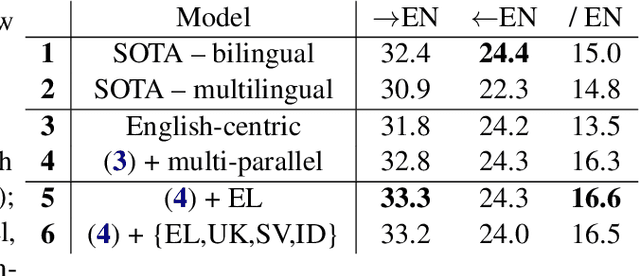
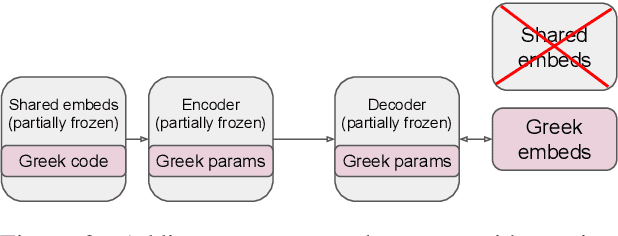
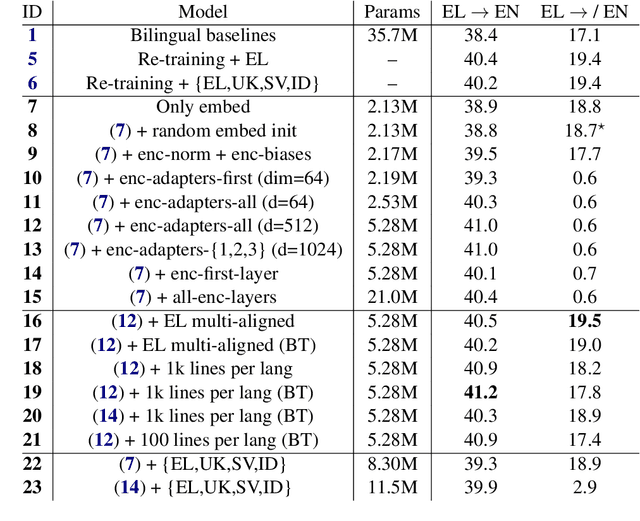
This paper proposes a technique for adding a new source or target language to an existing multilingual NMT model without re-training it on the initial set of languages. It consists in replacing the shared vocabulary with a small language-specific vocabulary and fine-tuning the new embeddings on the new language's parallel data. Some additional language-specific components may be trained to improve performance (e.g., Transformer layers or adapter modules). Because the parameters of the original model are not modified, its performance on the initial languages does not degrade. We show on two sets of experiments (small-scale on TED Talks, and large-scale on ParaCrawl) that this approach performs as well or better as the more costly alternatives; and that it has excellent zero-shot performance: training on English-centric data is enough to translate between the new language and any of the initial languages.
Efficient Inference for Multilingual Neural Machine Translation
Sep 14, 2021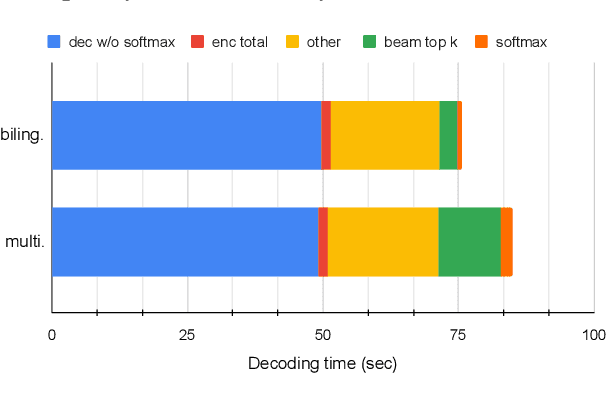
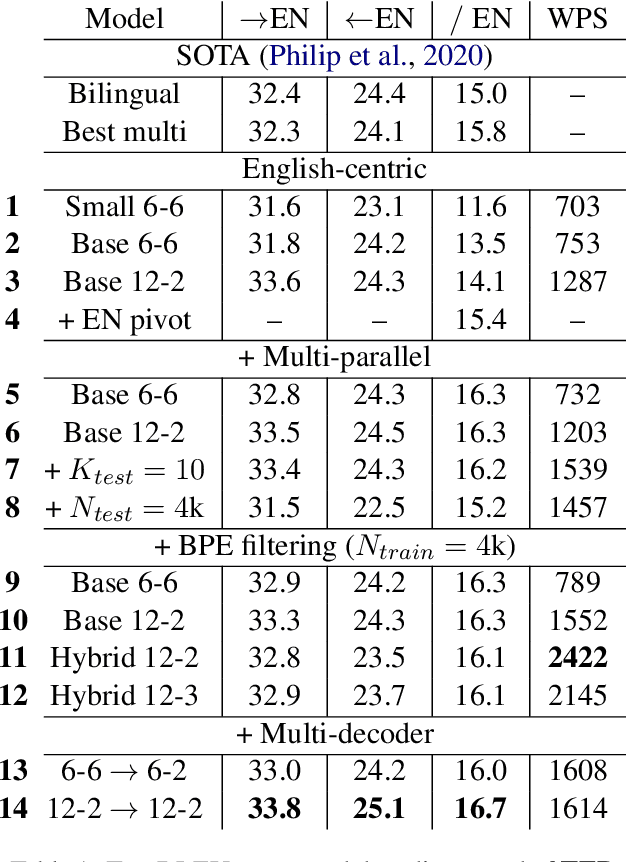
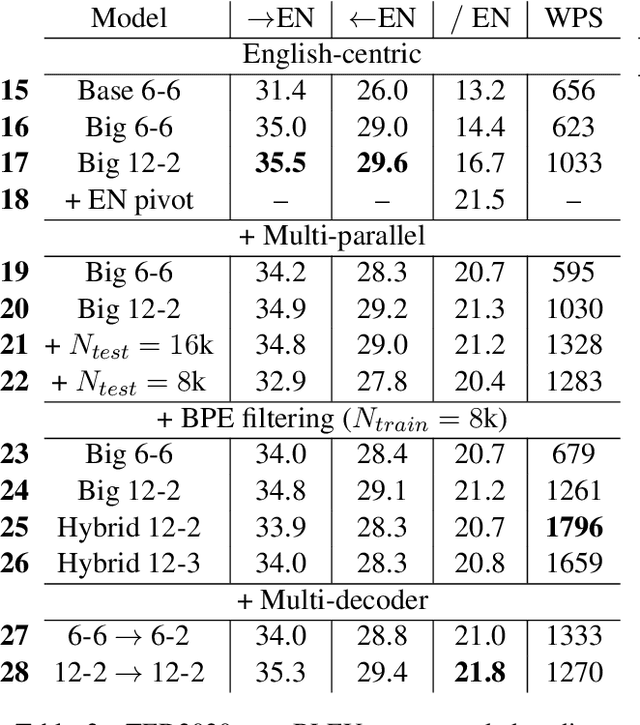
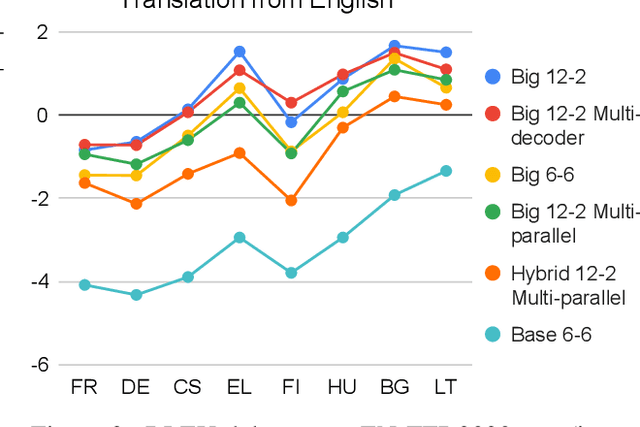
Multilingual NMT has become an attractive solution for MT deployment in production. But to match bilingual quality, it comes at the cost of larger and slower models. In this work, we consider several ways to make multilingual NMT faster at inference without degrading its quality. We experiment with several "light decoder" architectures in two 20-language multi-parallel settings: small-scale on TED Talks and large-scale on ParaCrawl. Our experiments demonstrate that combining a shallow decoder with vocabulary filtering leads to more than twice faster inference with no loss in translation quality. We validate our findings with BLEU and chrF (on 380 language pairs), robustness evaluation and human evaluation.
Unsupervised Word Segmentation from Speech with Attention
Jun 18, 2018

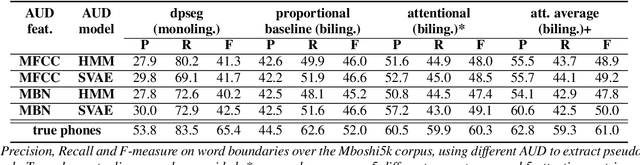
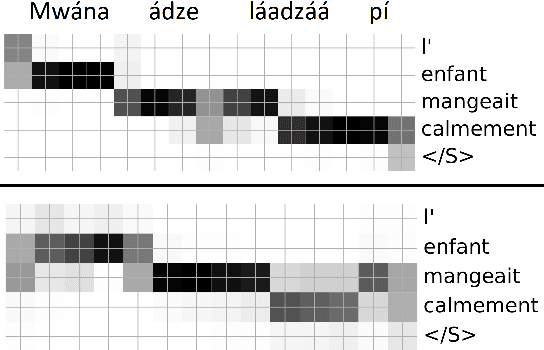
We present a first attempt to perform attentional word segmentation directly from the speech signal, with the final goal to automatically identify lexical units in a low-resource, unwritten language (UL). Our methodology assumes a pairing between recordings in the UL with translations in a well-resourced language. It uses Acoustic Unit Discovery (AUD) to convert speech into a sequence of pseudo-phones that is segmented using neural soft-alignments produced by a neural machine translation model. Evaluation uses an actual Bantu UL, Mboshi; comparisons to monolingual and bilingual baselines illustrate the potential of attentional word segmentation for language documentation.
Unwritten Languages Demand Attention Too! Word Discovery with Encoder-Decoder Models
Sep 19, 2017
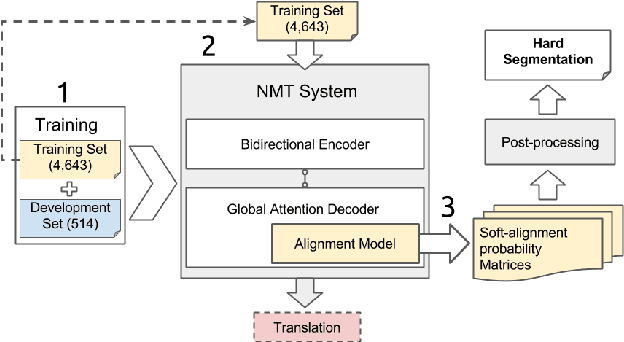
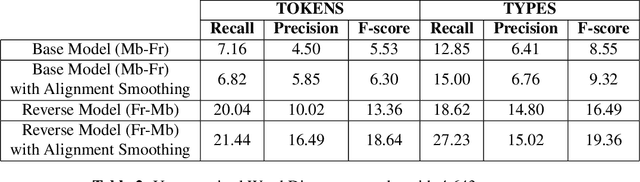

Word discovery is the task of extracting words from unsegmented text. In this paper we examine to what extent neural networks can be applied to this task in a realistic unwritten language scenario, where only small corpora and limited annotations are available. We investigate two scenarios: one with no supervision and another with limited supervision with access to the most frequent words. Obtained results show that it is possible to retrieve at least 27% of the gold standard vocabulary by training an encoder-decoder neural machine translation system with only 5,157 sentences. This result is close to those obtained with a task-specific Bayesian nonparametric model. Moreover, our approach has the advantage of generating translation alignments, which could be used to create a bilingual lexicon. As a future perspective, this approach is also well suited to work directly from speech.
LIG-CRIStAL System for the WMT17 Automatic Post-Editing Task
Jul 17, 2017

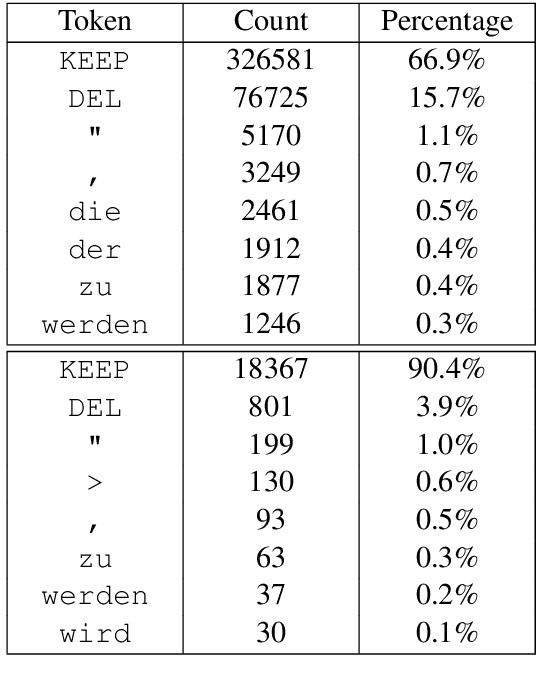

This paper presents the LIG-CRIStAL submission to the shared Automatic Post- Editing task of WMT 2017. We propose two neural post-editing models: a monosource model with a task-specific attention mechanism, which performs particularly well in a low-resource scenario; and a chained architecture which makes use of the source sentence to provide extra context. This latter architecture manages to slightly improve our results when more training data is available. We present and discuss our results on two datasets (en-de and de-en) that are made available for the task.
Listen and Translate: A Proof of Concept for End-to-End Speech-to-Text Translation
Dec 06, 2016



This paper proposes a first attempt to build an end-to-end speech-to-text translation system, which does not use source language transcription during learning or decoding. We propose a model for direct speech-to-text translation, which gives promising results on a small French-English synthetic corpus. Relaxing the need for source language transcription would drastically change the data collection methodology in speech translation, especially in under-resourced scenarios. For instance, in the former project DARPA TRANSTAC (speech translation from spoken Arabic dialects), a large effort was devoted to the collection of speech transcripts (and a prerequisite to obtain transcripts was often a detailed transcription guide for languages with little standardized spelling). Now, if end-to-end approaches for speech-to-text translation are successful, one might consider collecting data by asking bilingual speakers to directly utter speech in the source language from target language text utterances. Such an approach has the advantage to be applicable to any unwritten (source) language.