 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Learned Representations of a Deep ASR Performance Prediction Model
Aug 28, 2018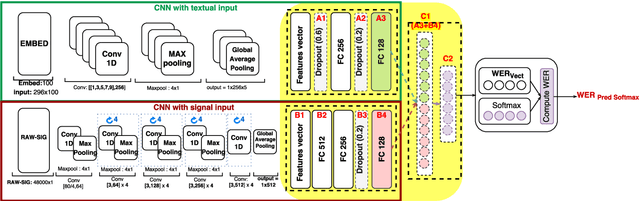
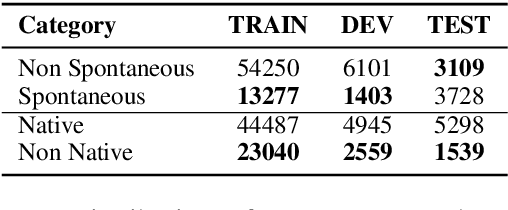
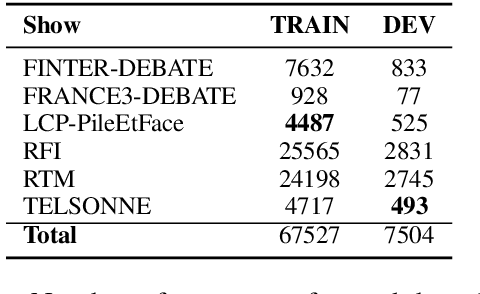
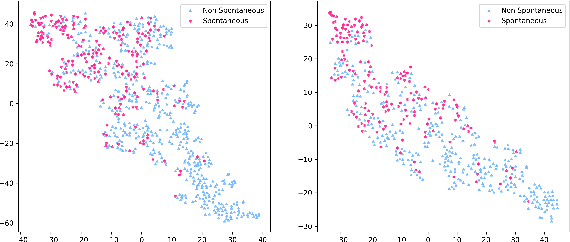
This paper addresses a relatively new task: prediction of ASR performance on unseen broadcast programs. In a previous paper, we presented an ASR performance prediction system using CNNs that encode both text (ASR transcript) and speech, in order to predict word error rate. This work is dedicated to the analysis of speech signal embeddings and text embeddings learnt by the CNN while training our prediction model. We try to better understand which information is captured by the deep model and its relation with different conditioning factors. It is shown that hidden layers convey a clear signal about speech style, accent and broadcast type. We then try to leverage these 3 types of information at training time through multi-task learning. Our experiments show that this allows to train slightly more efficient ASR performance prediction systems that - in addition - simultaneously tag the analyzed utterances according to their speech style, accent and broadcast program origin.
ASR Performance Prediction on Unseen Broadcast Programs using Convolutional Neural Networks
Apr 23, 2018
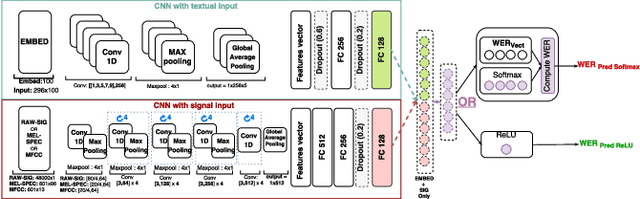
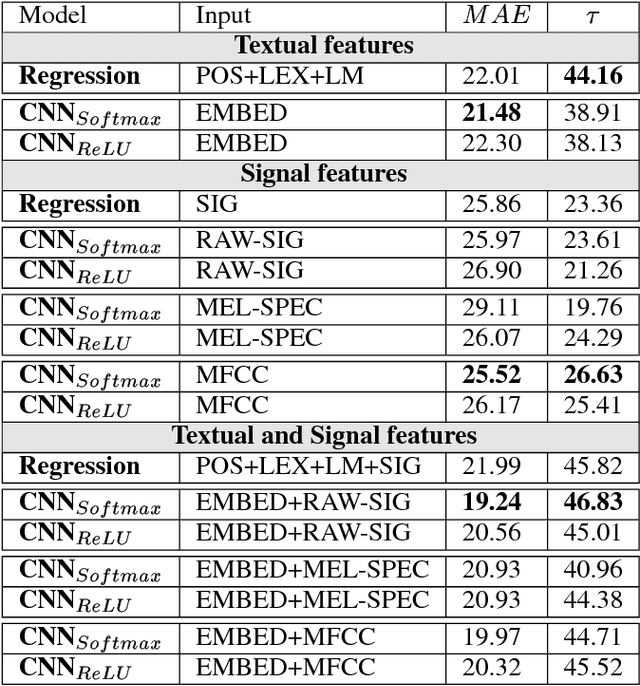
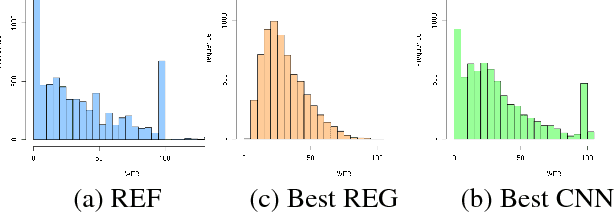
In this paper, we address a relatively new task: prediction of ASR performance on unseen broadcast programs. We first propose an heterogenous French corpus dedicated to this task. Two prediction approaches are compared: a state-of-the-art performance prediction based on regression (engineered features) and a new strategy based on convolutional neural networks (learnt features). We particularly focus on the combination of both textual (ASR transcription) and signal inputs. While the joint use of textual and signal features did not work for the regression baseline, the combination of inputs for CNNs leads to the best WER prediction performance. We also show that our CNN prediction remarkably predicts the WER distribution on a collection of speech recordings.
Word2Vec vs DBnary: Augmenting METEOR using Vector Representations or Lexical Resources?
Oct 05, 2016

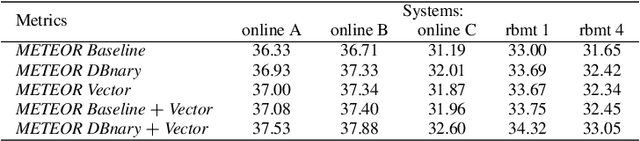
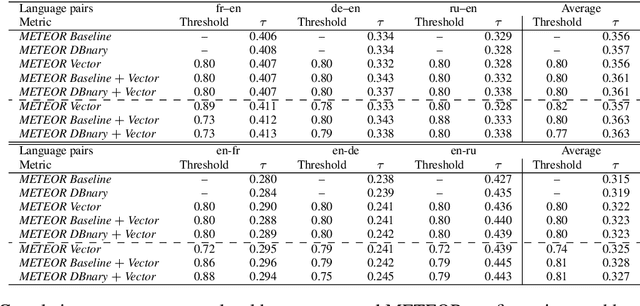
This paper presents an approach combining lexico-semantic resources and distributed representations of words applied to the evaluation in machine translation (MT). This study is made through the enrichment of a well-known MT evaluation metric: METEOR. This metric enables an approximate match (synonymy or morphological similarity) between an automatic and a reference translation. Our experiments are made in the framework of the Metrics task of WMT 2014. We show that distributed representations are a good alternative to lexico-semantic resources for MT evaluation and they can even bring interesting additional information. The augmented versions of METEOR, using vector representations, are made available on our Github page.