 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR Performance Prediction on Unseen Broadcast Programs using Convolutional Neural Networks
Apr 23, 2018
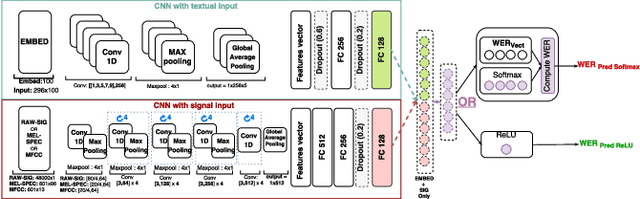
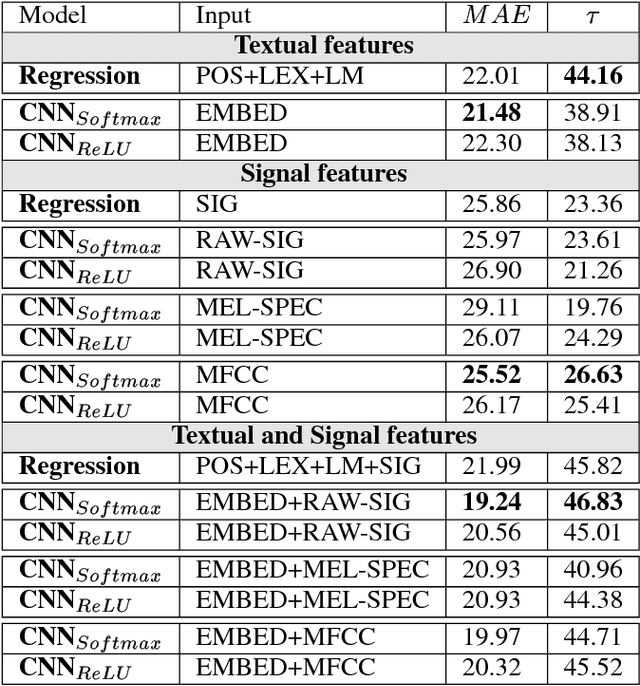
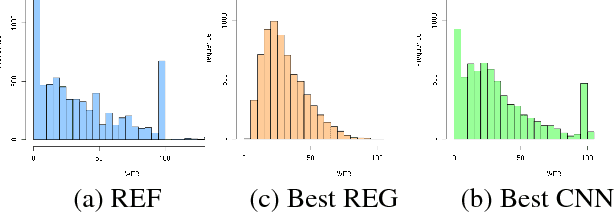
In this paper, we address a relatively new task: prediction of ASR performance on unseen broadcast programs. We first propose an heterogenous French corpus dedicated to this task. Two prediction approaches are compared: a state-of-the-art performance prediction based on regression (engineered features) and a new strategy based on convolutional neural networks (learnt features). We particularly focus on the combination of both textual (ASR transcription) and signal inputs. While the joint use of textual and signal features did not work for the regression baseline, the combination of inputs for CNNs leads to the best WER prediction performance. We also show that our CNN prediction remarkably predicts the WER distribution on a collection of speech recordings.