 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
Growing Trees on Sounds: Assessing Strategies for End-to-End Dependency Parsing of Speech
Jun 18, 2024



Direct dependency parsing of the speech signal -- as opposed to parsing speech transcriptions -- has recently been proposed as a task (Pupier et al. 2022), as a way of incorporating prosodic information in the parsing system and bypassing the limitations of a pipeline approach that would consist of using first an Automatic Speech Recognition (ASR) system and then a syntactic parser. In this article, we report on a set of experiments aiming at assessing the performance of two parsing paradigms (graph-based parsing and sequence labeling based parsing) on speech parsing. We perform this evaluation on a large treebank of spoken French, featuring realistic spontaneous conversations. Our findings show that (i) the graph based approach obtain better results across the board (ii) parsing directly from speech outperforms a pipeline approach, despite having 30% fewer parameters.
What has LeBenchmark Learnt about French Syntax?
Mar 04, 2024



The paper reports on a series of experiments aiming at probing LeBenchmark, a pretrained acoustic model trained on 7k hours of spoken French, for syntactic information. Pretrained acoustic models are increasingly used for downstream speech tasks such as automatic speech recognition, speech translation, spoken language understanding or speech parsing. They are trained on very low level information (the raw speech signal), and do not have explicit lexical knowledge. Despite that, they obtained reasonable results on tasks that requires higher level linguistic knowledge. As a result, an emerging question is whether these models encode syntactic information. We probe each representation layer of LeBenchmark for syntax, using the Orf\'eo treebank, and observe that it has learnt some syntactic information. Our results show that syntactic information is more easily extractable from the middle layers of the network, after which a very sharp decrease is observed.
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
Pre-training for Speech Translation: CTC Meets Optimal Transport
Jan 27, 2023The gap between speech and text modalities is a major challenge in speech-to-text translation (ST). Different methods have been proposed for reducing this gap, but most of them require architectural changes in ST training. In this work, we propose to mitigate this issue at the pre-training stage, requiring no change in the ST model. First, we show that the connectionist temporal classification (CTC) loss can reduce the modality gap by design. We provide a quantitative comparison with the more common cross-entropy loss, showing that pre-training with CTC consistently achieves better final ST accuracy. Nevertheless, CTC is only a partial solution and thus, in our second contribution, we propose a novel pre-training method combining CTC and optimal transport to further reduce this gap. Our method pre-trains a Siamese-like model composed of two encoders, one for acoustic inputs and the other for textual inputs, such that they produce representations that are close to each other in the Wasserstein space. Extensive experiments on the standard CoVoST-2 and MuST-C datasets show that our pre-training method applied to the vanilla encoder-decoder Transformer achieves state-of-the-art performance under the no-external-data setting, and performs on par with recent strong multi-task learning systems trained with external data. Finally, our method can also be applied on top of these multi-task systems, leading to further improvements for these models.
LeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech
Apr 23, 2021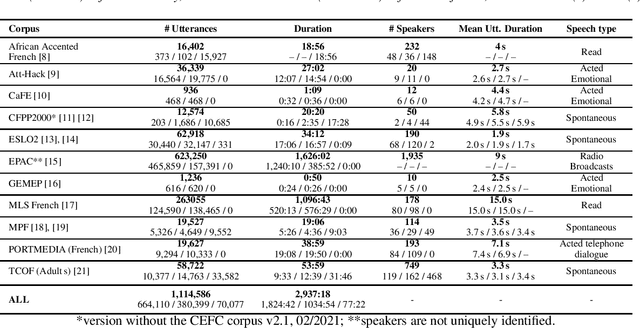
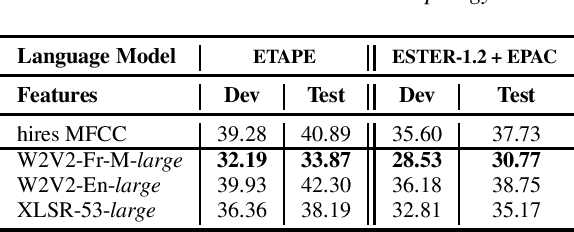
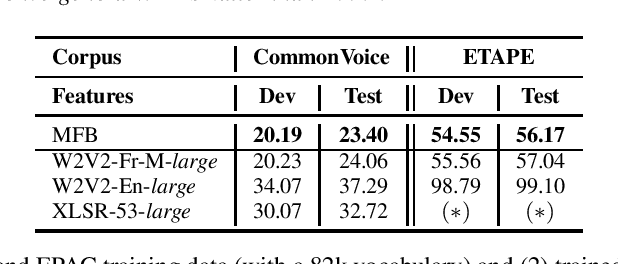
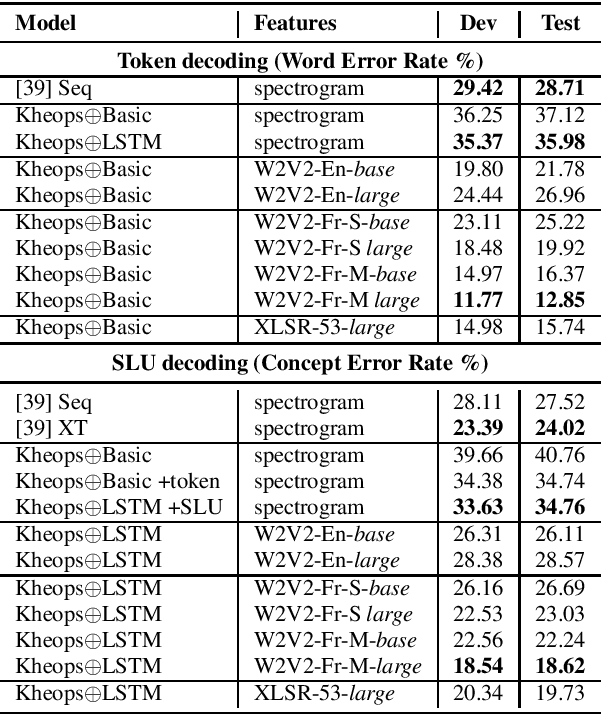
Self-Supervised Learning (SSL) using huge unlabeled data has been successfully explored for image and natural language processing. Recent works also investigated SSL from speech. They were notably successful to improve performance on downstream tasks such as automatic speech recognition (ASR). While these works suggest it is possible to reduce dependence on labeled data for building efficient speech systems, their evaluation was mostly made on ASR and using multiple and heterogeneous experimental settings (most of them for English). This renders difficult the objective comparison between SSL approaches and the evaluation of their impact on building speech systems. In this paper, we propose LeBenchmark: a reproducible framework for assessing SSL from speech. It not only includes ASR (high and low resource) tasks but also spoken language understanding, speech translation and emotion recognition. We also target speech technologies in a language different than English: French. SSL models of different sizes are trained from carefully sourced and documented datasets. Experiments show that SSL is beneficial for most but not all tasks which confirms the need for exhaustive and reliable benchmarks to evaluate its real impact. LeBenchmark is shared with the scientific community for reproducible research in SSL from speech.
ON-TRAC Consortium for End-to-End and Simultaneous Speech Translation Challenge Tasks at IWSLT 2020
May 24, 2020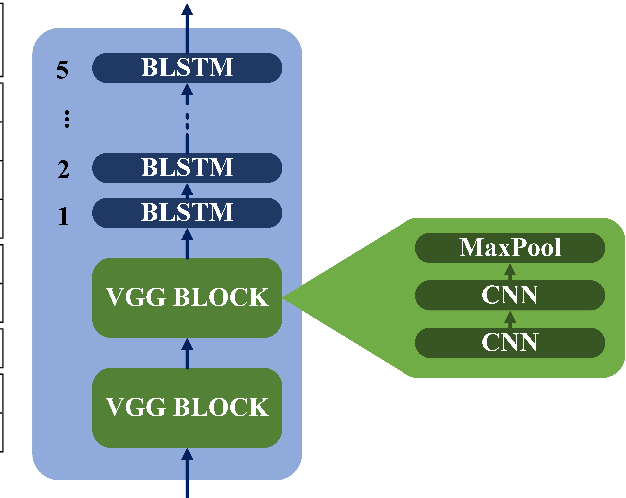
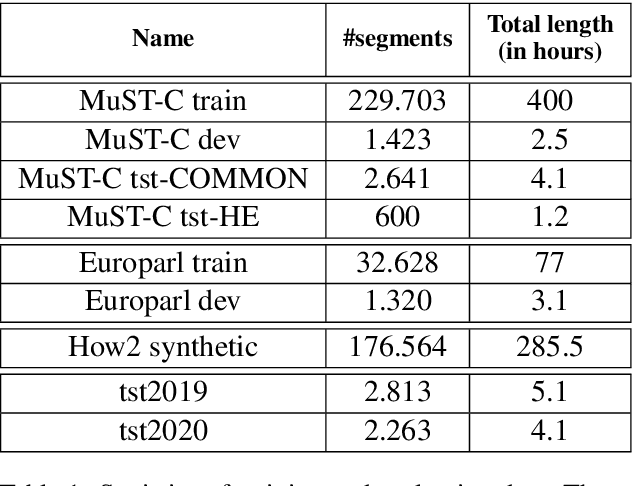
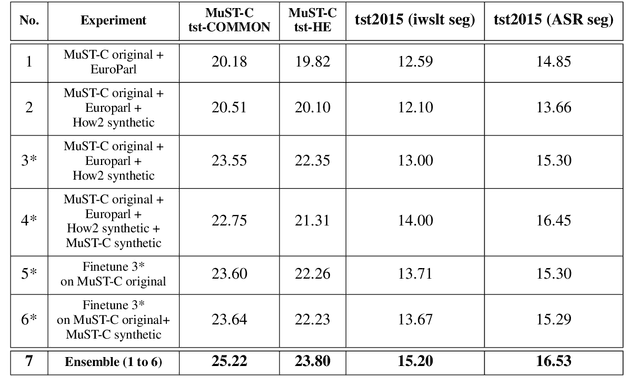
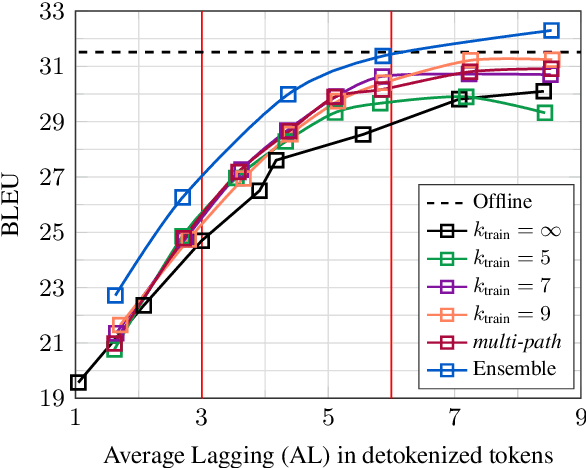
This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2020, offline speech translation and simultaneous speech translation. ON-TRAC Consortium is composed of researchers from three French academic laboratories: LIA (Avignon Universit\'e), LIG (Universit\'e Grenoble Alpes), and LIUM (Le Mans Universit\'e). Attention-based encoder-decoder models, trained end-to-end, were used for our submissions to the offline speech translation track. Our contributions focused on data augmentation and ensembling of multiple models. In the simultaneous speech translation track, we build on Transformer-based wait-k models for the text-to-text subtask. For speech-to-text simultaneous translation, we attach a wait-k MT system to a hybrid ASR system. We propose an algorithm to control the latency of the ASR+MT cascade and achieve a good latency-quality trade-off on both subtasks.
FlauBERT: Unsupervised Language Model Pre-training for French
Jan 09, 2020
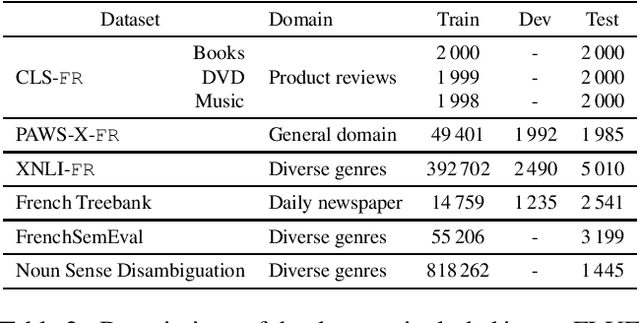
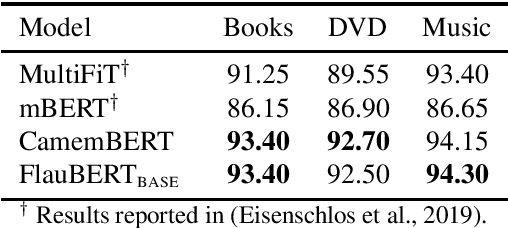

Language models have become a key step to achieve state-of-the art results in many different Natural Language Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their contextualization at the sentence level. This has been widely demonstrated for English using contextualized representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al., 2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the time they outperform other pre-training approaches. Different versions of FlauBERT as well as a unified evaluation protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research community for further reproducible experiments in French NLP.
The LIG system for the English-Czech Text Translation Task of IWSLT 2019
Nov 07, 2019
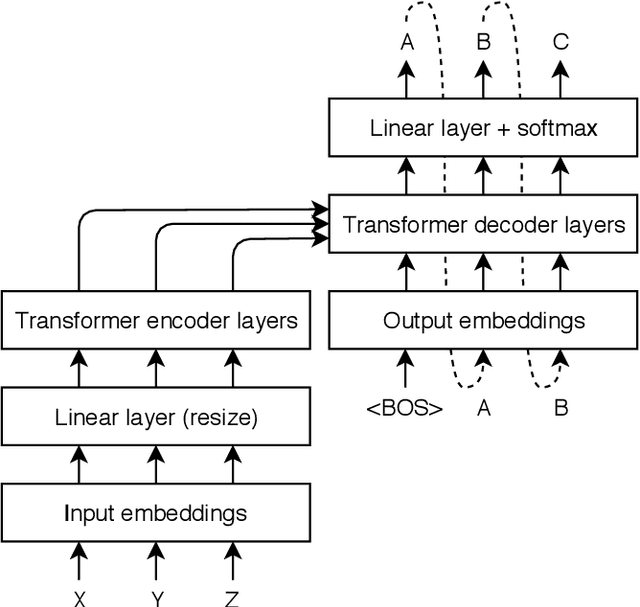
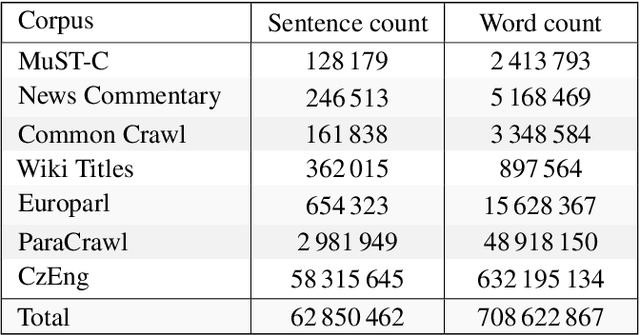

In this paper, we present our submission for the English to Czech Text Translation Task of IWSLT 2019. Our system aims to study how pre-trained language models, used as input embeddings, can improve a specialized machine translation system trained on few data. Therefore, we implemented a Transformer-based encoder-decoder neural system which is able to use the output of a pre-trained language model as input embeddings, and we compared its performance under three configurations: 1) without any pre-trained language model (constrained), 2) using a language model trained on the monolingual parts of the allowed English-Czech data (constrained), and 3) using a language model trained on a large quantity of external monolingual data (unconstrained). We used BERT as external pre-trained language model (configuration 3), and BERT architecture for training our own language model (configuration 2). Regarding the training data, we trained our MT system on a small quantity of parallel text: one set only consists of the provided MuST-C corpus, and the other set consists of the MuST-C corpus and the News Commentary corpus from WMT. We observed that using the external pre-trained BERT improves the scores of our system by +0.8 to +1.5 of BLEU on our development set, and +0.97 to +1.94 of BLEU on the test set. However, using our own language model trained only on the allowed parallel data seems to improve the machine translation performances only when the system is trained on the smallest dataset.
Sense Vocabulary Compression through the Semantic Knowledge of WordNet for Neural Word Sense Disambiguation
May 14, 2019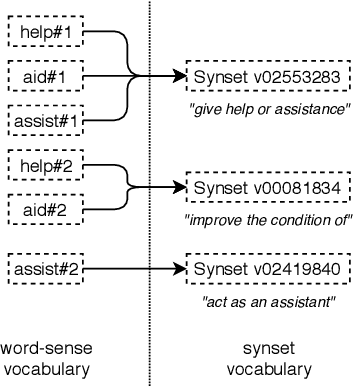
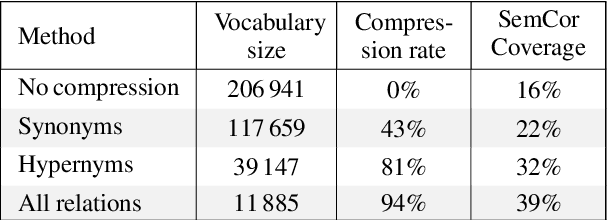
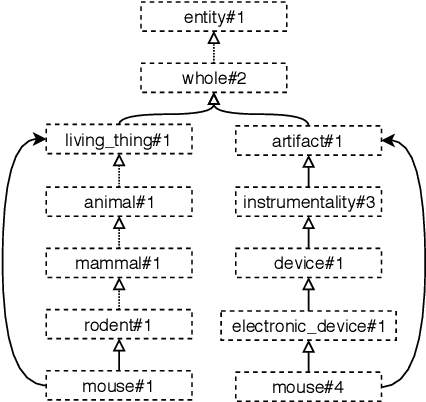
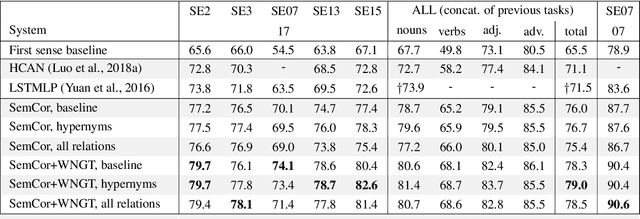
In this article, we tackle the issue of the limited quantity of manually sense annotated corpora for the task of word sense disambiguation, by exploiting the semantic relationships between senses such as synonymy, hypernymy and hyponymy, in order to compress the sense vocabulary of Princeton WordNet, and thus reduce the number of different sense tags that must be observed to disambiguate all words of the lexical database. We propose two different methods that greatly reduces the size of neural WSD models, with the benefit of improving their coverage without additional training data, and without impacting their precision. In addition to our method, we present a new WSD system which relies on pre-trained BERT word vectors in order to achieve results that significantly outperform the state of the art on all WSD evaluation tasks.