 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSense Vocabulary Compression through the Semantic Knowledge of WordNet for Neural Word Sense Disambiguation
Paper and Code
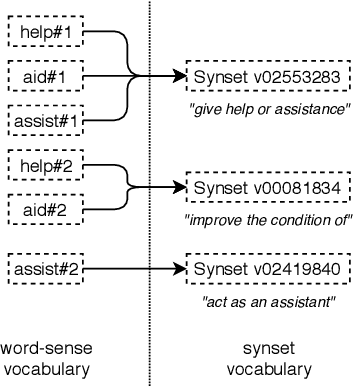
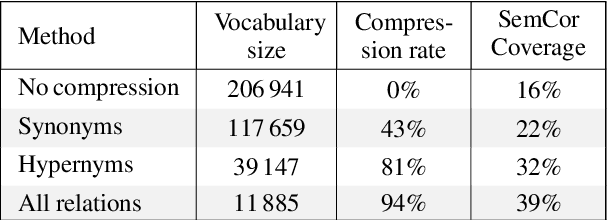
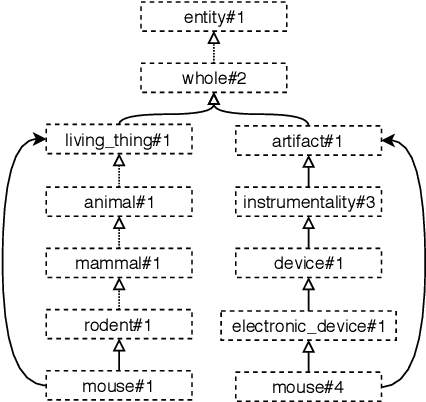
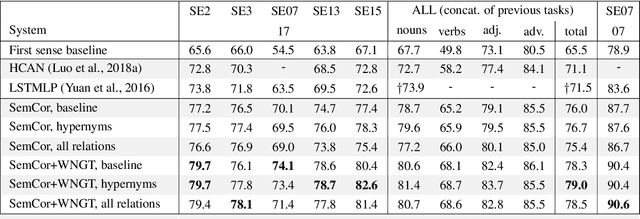
In this article, we tackle the issue of the limited quantity of manually sense annotated corpora for the task of word sense disambiguation, by exploiting the semantic relationships between senses such as synonymy, hypernymy and hyponymy, in order to compress the sense vocabulary of Princeton WordNet, and thus reduce the number of different sense tags that must be observed to disambiguate all words of the lexical database. We propose two different methods that greatly reduces the size of neural WSD models, with the benefit of improving their coverage without additional training data, and without impacting their precision. In addition to our method, we present a new WSD system which relies on pre-trained BERT word vectors in order to achieve results that significantly outperform the state of the art on all WSD evaluation tasks.