 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlauBERT: Unsupervised Language Model Pre-training for French
Jan 09, 2020
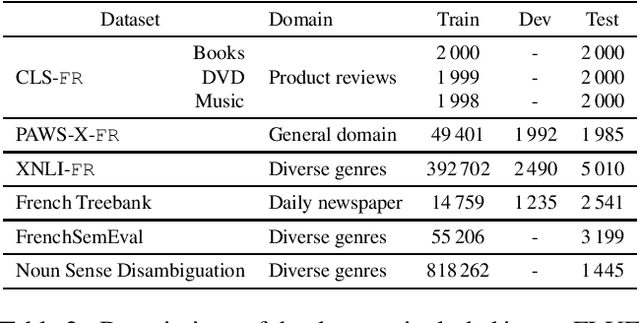
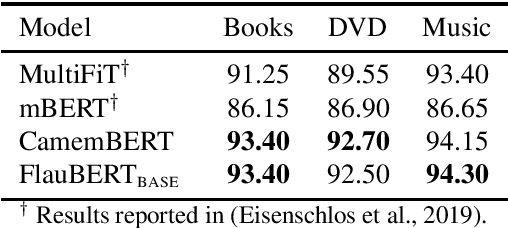

Language models have become a key step to achieve state-of-the art results in many different Natural Language Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their contextualization at the sentence level. This has been widely demonstrated for English using contextualized representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al., 2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the time they outperform other pre-training approaches. Different versions of FlauBERT as well as a unified evaluation protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research community for further reproducible experiments in French NLP.
The LIG system for the English-Czech Text Translation Task of IWSLT 2019
Nov 07, 2019
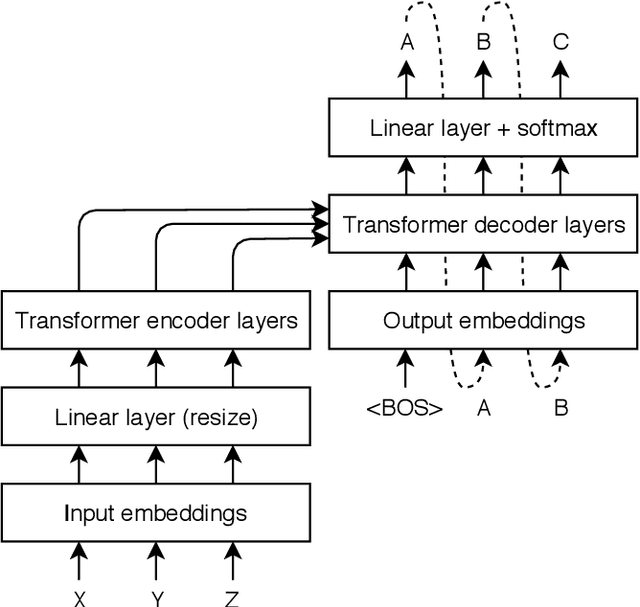
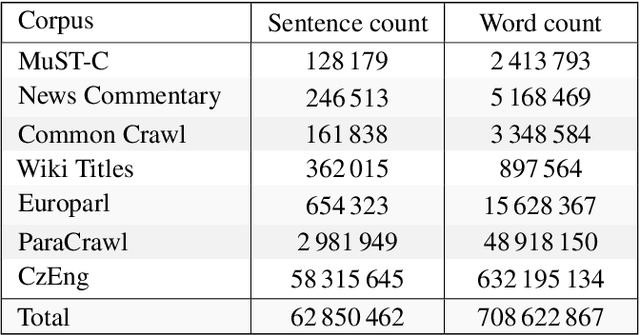

In this paper, we present our submission for the English to Czech Text Translation Task of IWSLT 2019. Our system aims to study how pre-trained language models, used as input embeddings, can improve a specialized machine translation system trained on few data. Therefore, we implemented a Transformer-based encoder-decoder neural system which is able to use the output of a pre-trained language model as input embeddings, and we compared its performance under three configurations: 1) without any pre-trained language model (constrained), 2) using a language model trained on the monolingual parts of the allowed English-Czech data (constrained), and 3) using a language model trained on a large quantity of external monolingual data (unconstrained). We used BERT as external pre-trained language model (configuration 3), and BERT architecture for training our own language model (configuration 2). Regarding the training data, we trained our MT system on a small quantity of parallel text: one set only consists of the provided MuST-C corpus, and the other set consists of the MuST-C corpus and the News Commentary corpus from WMT. We observed that using the external pre-trained BERT improves the scores of our system by +0.8 to +1.5 of BLEU on our development set, and +0.97 to +1.94 of BLEU on the test set. However, using our own language model trained only on the allowed parallel data seems to improve the machine translation performances only when the system is trained on the smallest dataset.
Sense Vocabulary Compression through the Semantic Knowledge of WordNet for Neural Word Sense Disambiguation
May 14, 2019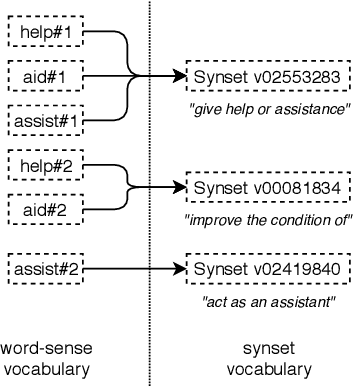
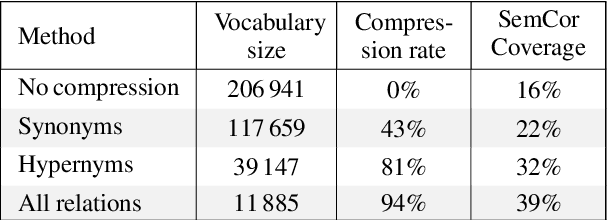
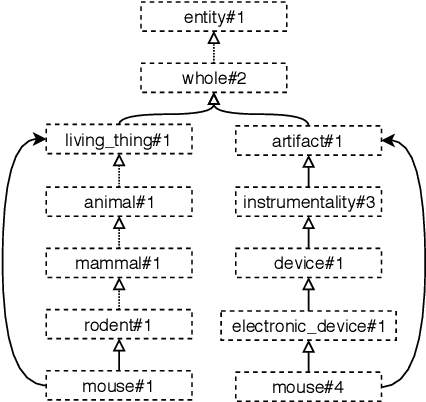
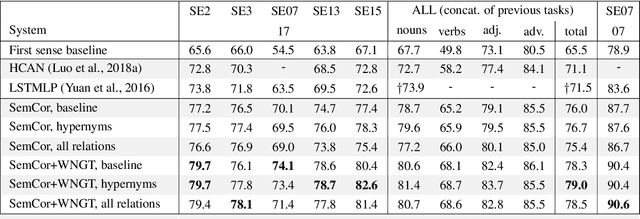
In this article, we tackle the issue of the limited quantity of manually sense annotated corpora for the task of word sense disambiguation, by exploiting the semantic relationships between senses such as synonymy, hypernymy and hyponymy, in order to compress the sense vocabulary of Princeton WordNet, and thus reduce the number of different sense tags that must be observed to disambiguate all words of the lexical database. We propose two different methods that greatly reduces the size of neural WSD models, with the benefit of improving their coverage without additional training data, and without impacting their precision. In addition to our method, we present a new WSD system which relies on pre-trained BERT word vectors in order to achieve results that significantly outperform the state of the art on all WSD evaluation tasks.
Improving the Coverage and the Generalization Ability of Neural Word Sense Disambiguation through Hypernymy and Hyponymy Relationships
Nov 02, 2018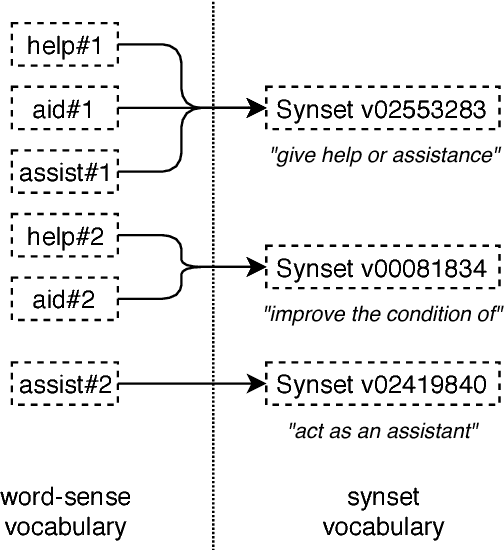

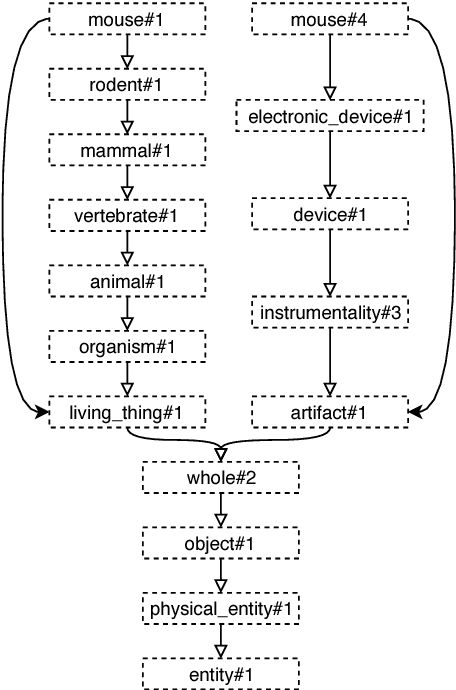
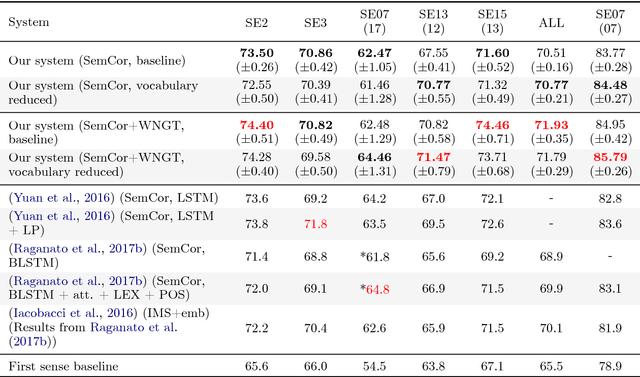
In Word Sense Disambiguation (WSD), the predominant approach generally involves a supervised system trained on sense annotated corpora. The limited quantity of such corpora however restricts the coverage and the performance of these systems. In this article, we propose a new method that solves these issues by taking advantage of the knowledge present in WordNet, and especially the hypernymy and hyponymy relationships between synsets, in order to reduce the number of different sense tags that are necessary to disambiguate all words of the lexical database. Our method leads to state of the art results on most WSD evaluation tasks, while improving the coverage of supervised systems, reducing the training time and the size of the models, without additional training data. In addition, we exhibit results that significantly outperform the state of the art when our method is combined with an ensembling technique and the addition of the WordNet Gloss Tagged as training corpus.
Comparison of Global Algorithms in Word Sense Disambiguation
Apr 07, 2017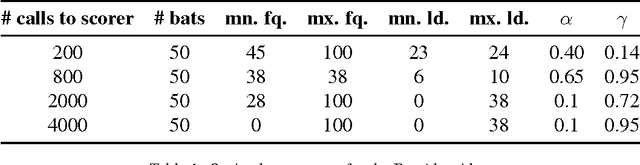
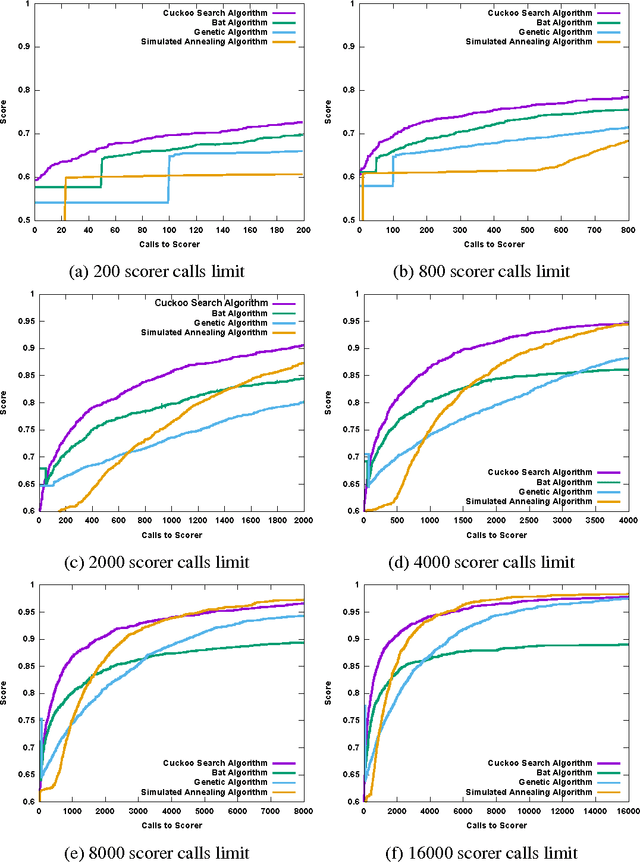

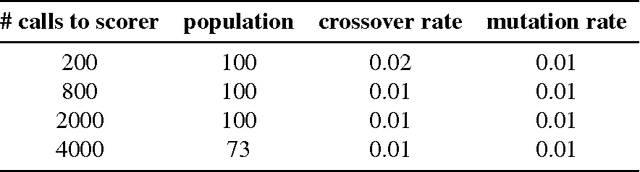
This article compares four probabilistic algorithms (global algorithms) for Word Sense Disambiguation (WSD) in terms of the number of scorer calls (local algo- rithm) and the F1 score as determined by a gold-standard scorer. Two algorithms come from the state of the art, a Simulated Annealing Algorithm (SAA) and a Genetic Algorithm (GA) as well as two algorithms that we first adapt from WSD that are state of the art probabilistic search algorithms, namely a Cuckoo search algorithm (CSA) and a Bat Search algorithm (BS). As WSD requires to evaluate exponentially many word sense combinations (with branching factors of up to 6 or more), probabilistic algorithms allow to find approximate solution in a tractable time by sampling the search space. We find that CSA, GA and SA all eventually converge to similar results (0.98 F1 score), but CSA gets there faster (in fewer scorer calls) and reaches up to 0.95 F1 before SA in fewer scorer calls. In BA a strict convergence criterion prevents it from reaching above 0.89 F1.