 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Speech-LLM Takes It All: A Truly Fully End-to-End Spoken Dialogue State Tracking Approach
Oct 10, 2025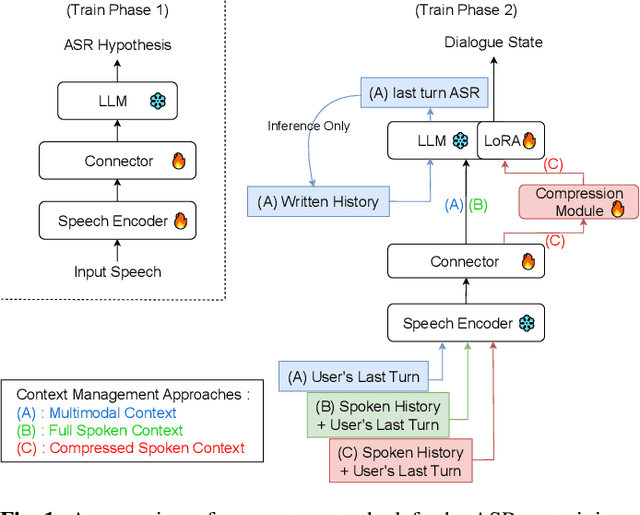

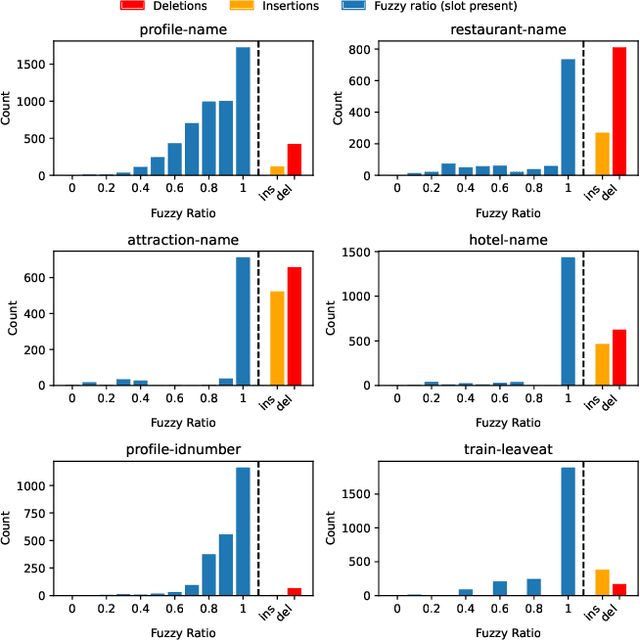
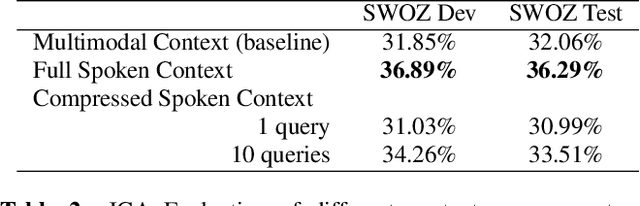
This paper presents a comparative study of context management strategies for end-to-end Spoken Dialog State Tracking using Speech-LLMs. We systematically evaluate traditional multimodal context (combining text history and spoken current turn), full spoken history, and compressed spoken history approaches. Our experiments on the SpokenWOZ corpus demonstrate that providing the full spoken conversation as input yields the highest performance among models of similar size, significantly surpassing prior methods. Furthermore, we show that attention-pooling-based compression of the spoken history offers a strong trade-off, maintaining competitive accuracy with reduced context size. Detailed analysis confirms that improvements stem from more effective context utilization.
Africa-Centric Self-Supervised Pre-Training for Multilingual Speech Representation in a Sub-Saharan Context
Apr 05, 2024

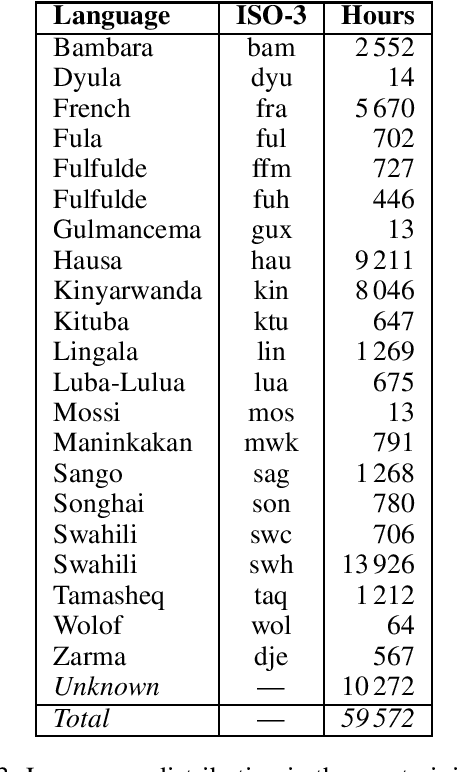
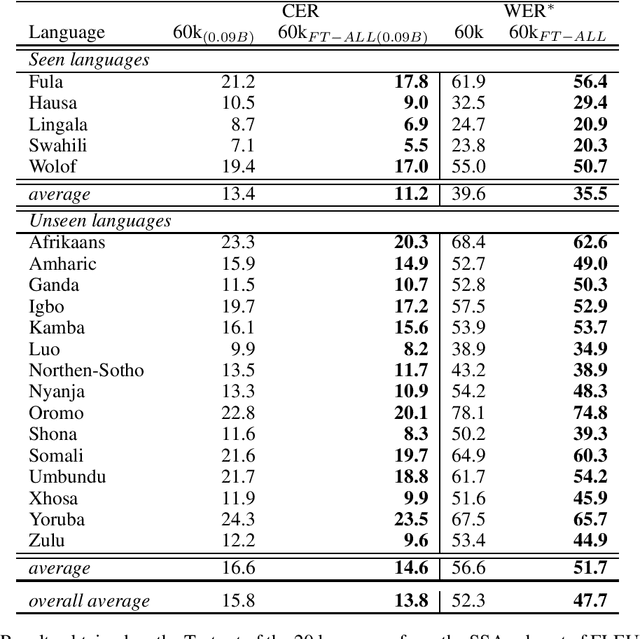
We present the first self-supervised multilingual speech model trained exclusively on African speech. The model learned from nearly 60 000 hours of unlabeled speech segments in 21 languages and dialects spoken in sub-Saharan Africa. On the SSA subset of the FLEURS-102 dataset, our approach based on a HuBERT$_{base}$ (0.09B) architecture shows competitive results, for ASR downstream task, compared to the w2v-bert-51 (0.6B) pre-trained model proposed in the FLEURS benchmark, while being more efficient by using 7x less data and 6x less parameters. Furthermore, in the context of a LID downstream task, our approach outperforms FLEURS baselines accuracy by over 22\%.
Where are we in semantic concept extraction for Spoken Language Understanding?
Jun 24, 2021


Spoken language understanding (SLU) topic has seen a lot of progress these last three years, with the emergence of end-to-end neural approaches. Spoken language understanding refers to natural language processing tasks related to semantic extraction from speech signal, like named entity recognition from speech or slot filling task in a context of human-machine dialogue. Classically, SLU tasks were processed through a cascade approach that consists in applying, firstly, an automatic speech recognition process, followed by a natural language processing module applied to the automatic transcriptions. These three last years, end-to-end neural approaches, based on deep neural networks, have been proposed in order to directly extract the semantics from speech signal, by using a single neural model. More recent works on self-supervised training with unlabeled data open new perspectives in term of performance for automatic speech recognition and natural language processing. In this paper, we present a brief overview of the recent advances on the French MEDIA benchmark dataset for SLU, with or without the use of additional data. We also present our last results that significantly outperform the current state-of-the-art with a Concept Error Rate (CER) of 11.2%, instead of 13.6% for the last state-of-the-art system presented this year.
End2End Acoustic to Semantic Transduction
Feb 01, 2021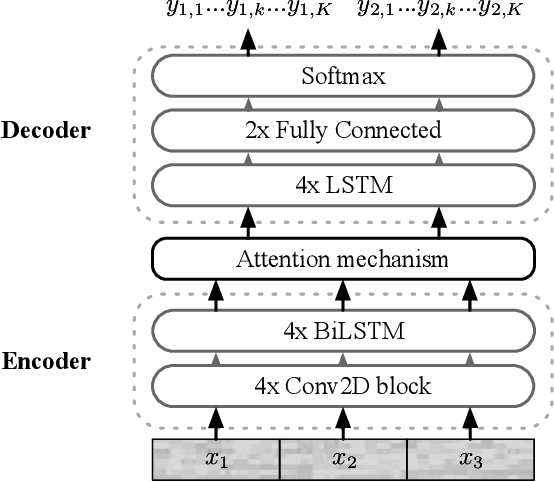

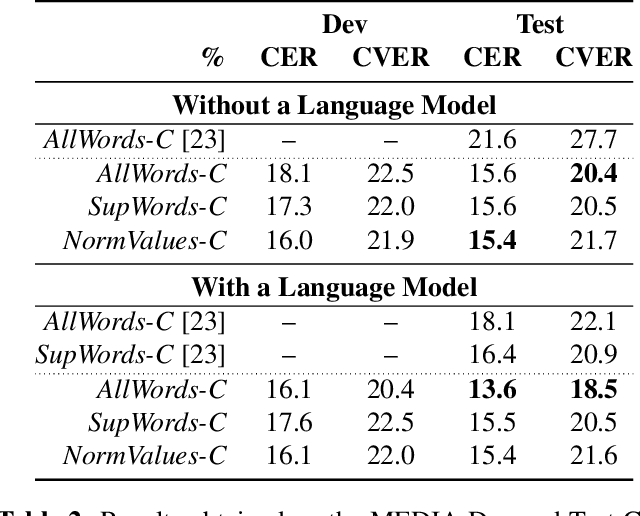
In this paper, we propose a novel end-to-end sequence-to-sequence spoken language understanding model using an attention mechanism. It reliably selects contextual acoustic features in order to hypothesize semantic contents. An initial architecture capable of extracting all pronounced words and concepts from acoustic spans is designed and tested. With a shallow fusion language model, this system reaches a 13.6 concept error rate (CER) and an 18.5 concept value error rate (CVER) on the French MEDIA corpus, achieving an absolute 2.8 points reduction compared to the state-of-the-art. Then, an original model is proposed for hypothesizing concepts and their values. This transduction reaches a 15.4 CER and a 21.6 CVER without any new type of context.
ON-TRAC Consortium for End-to-End and Simultaneous Speech Translation Challenge Tasks at IWSLT 2020
May 24, 2020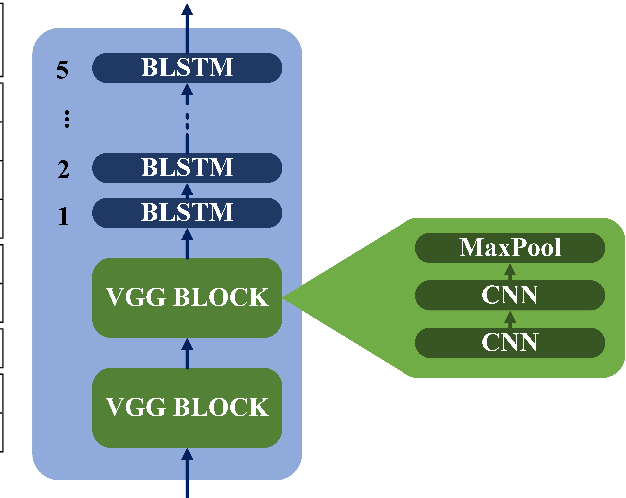
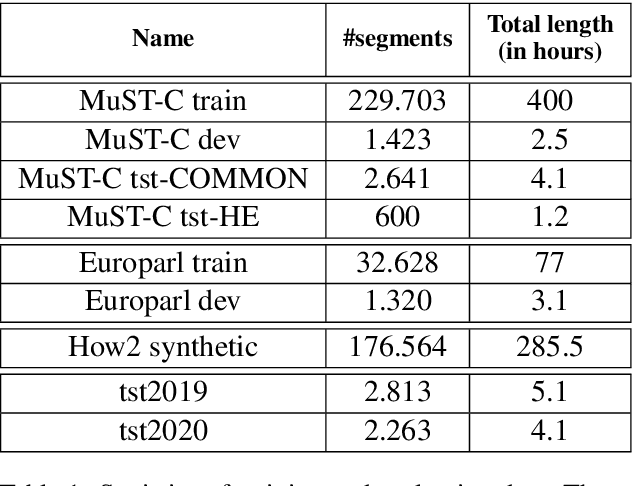
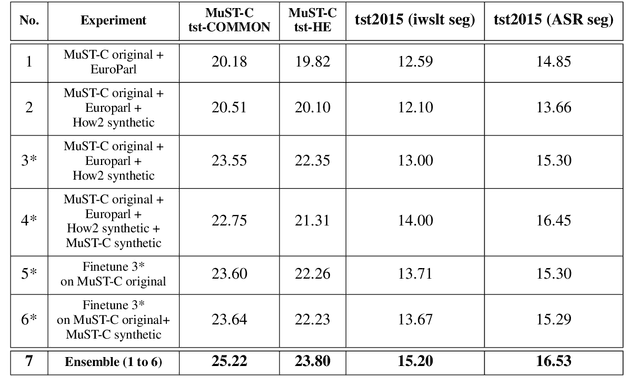
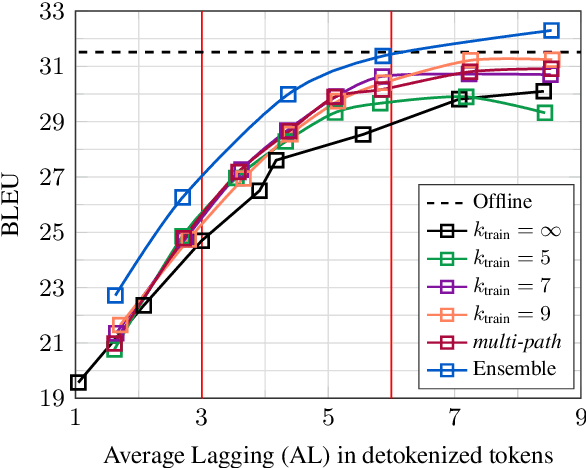
This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2020, offline speech translation and simultaneous speech translation. ON-TRAC Consortium is composed of researchers from three French academic laboratories: LIA (Avignon Universit\'e), LIG (Universit\'e Grenoble Alpes), and LIUM (Le Mans Universit\'e). Attention-based encoder-decoder models, trained end-to-end, were used for our submissions to the offline speech translation track. Our contributions focused on data augmentation and ensembling of multiple models. In the simultaneous speech translation track, we build on Transformer-based wait-k models for the text-to-text subtask. For speech-to-text simultaneous translation, we attach a wait-k MT system to a hybrid ASR system. We propose an algorithm to control the latency of the ASR+MT cascade and achieve a good latency-quality trade-off on both subtasks.
Curriculum-based transfer learning for an effective end-to-end spoken language understanding and domain portability
Jun 18, 2019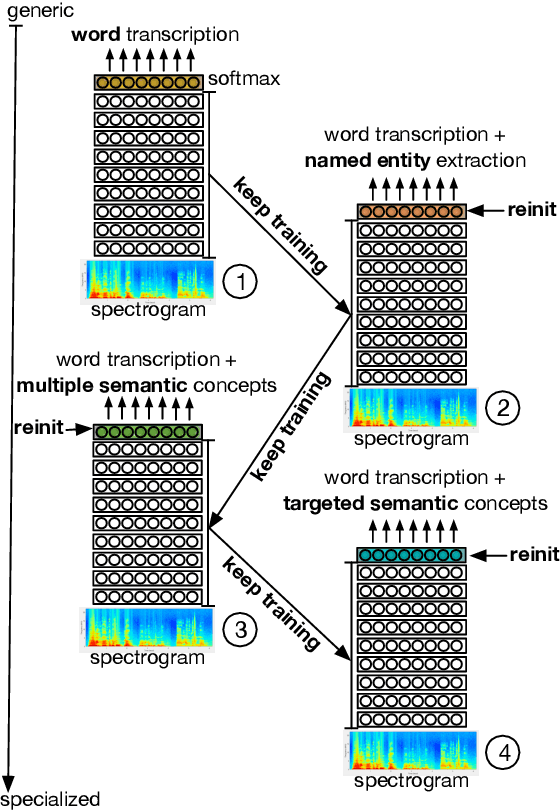


We present an end-to-end approach to extract semantic concepts directly from the speech audio signal. To overcome the lack of data available for this spoken language understanding approach, we investigate the use of a transfer learning strategy based on the principles of curriculum learning. This approach allows us to exploit out-of-domain data that can help to prepare a fully neural architecture. Experiments are carried out on the French MEDIA and PORTMEDIA corpora and show that this end-to-end SLU approach reaches the best results ever published on this task. We compare our approach to a classical pipeline approach that uses ASR, POS tagging, lemmatizer, chunker... and other NLP tools that aim to enrich ASR outputs that feed an SLU text to concepts system. Last, we explore the promising capacity of our end-to-end SLU approach to address the problem of domain portability.
End-to-end named entity extraction from speech
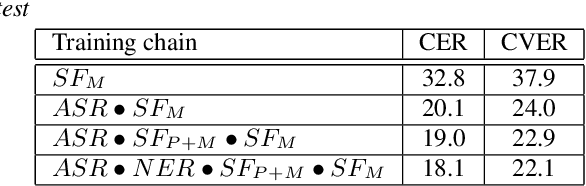
May 30, 2018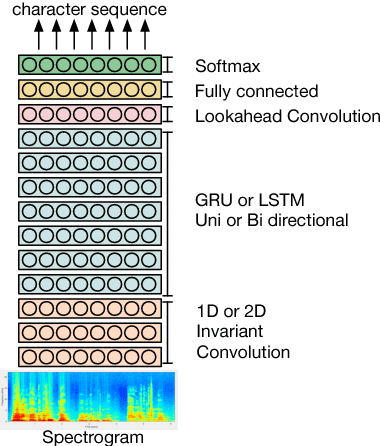
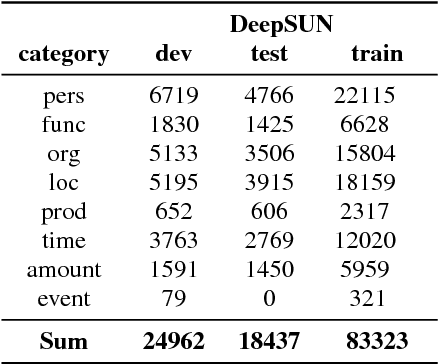

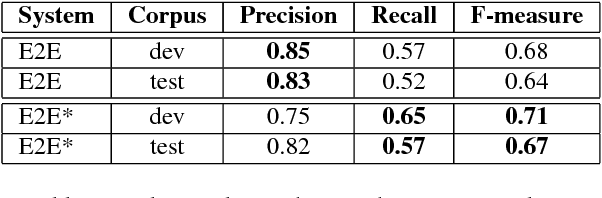
Named entity recognition (NER) is among SLU tasks that usually extract semantic information from textual documents. Until now, NER from speech is made through a pipeline process that consists in processing first an automatic speech recognition (ASR) on the audio and then processing a NER on the ASR outputs. Such approach has some disadvantages (error propagation, metric to tune ASR systems sub-optimal in regards to the final task, reduced space search at the ASR output level...) and it is known that more integrated approaches outperform sequential ones, when they can be applied. In this paper, we present a first study of end-to-end approach that directly extracts named entities from speech, though a unique neural architecture. On a such way, a joint optimization is able for both ASR and NER. Experiments are carried on French data easily accessible, composed of data distributed in several evaluation campaign. Experimental results show that this end-to-end approach provides better results (F-measure=0.69 on test data) than a classical pipeline approach to detect named entity categories (F-measure=0.65).