 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024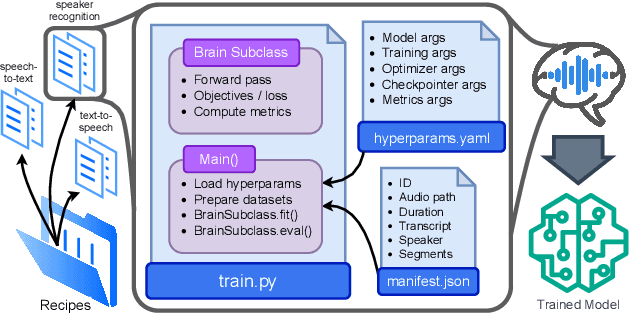

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021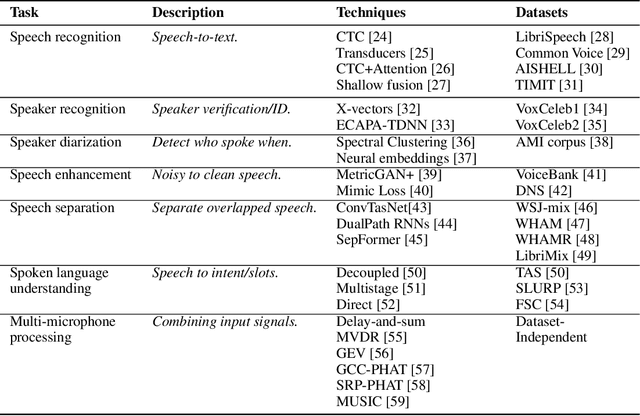
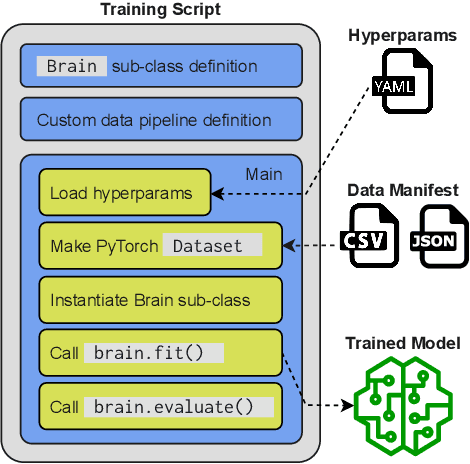

SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
End2End Acoustic to Semantic Transduction
Feb 01, 2021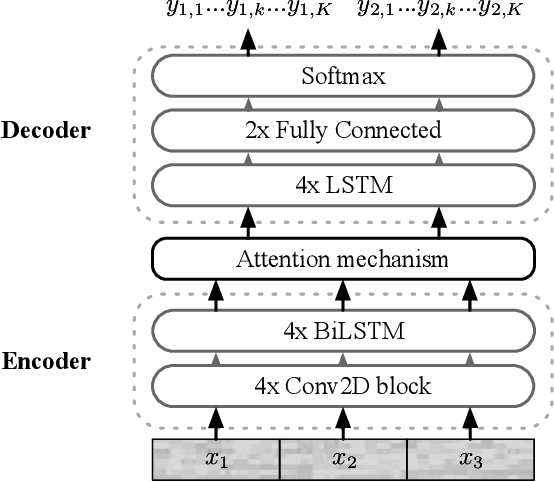

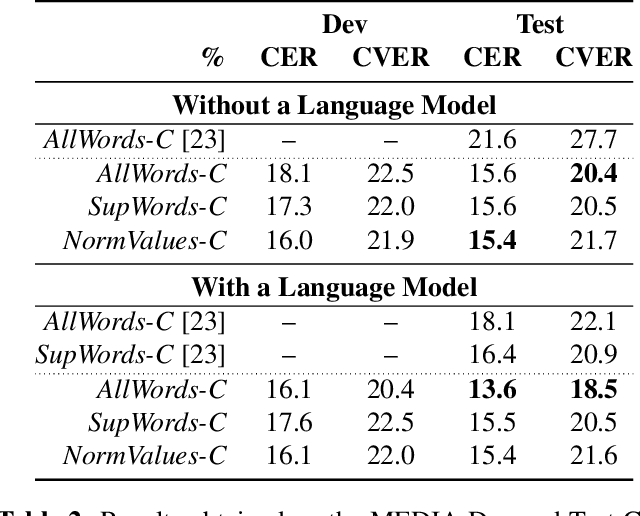
In this paper, we propose a novel end-to-end sequence-to-sequence spoken language understanding model using an attention mechanism. It reliably selects contextual acoustic features in order to hypothesize semantic contents. An initial architecture capable of extracting all pronounced words and concepts from acoustic spans is designed and tested. With a shallow fusion language model, this system reaches a 13.6 concept error rate (CER) and an 18.5 concept value error rate (CVER) on the French MEDIA corpus, achieving an absolute 2.8 points reduction compared to the state-of-the-art. Then, an original model is proposed for hypothesizing concepts and their values. This transduction reaches a 15.4 CER and a 21.6 CVER without any new type of context.
Dialogue history integration into end-to-end signal-to-concept spoken language understanding systems
Feb 14, 2020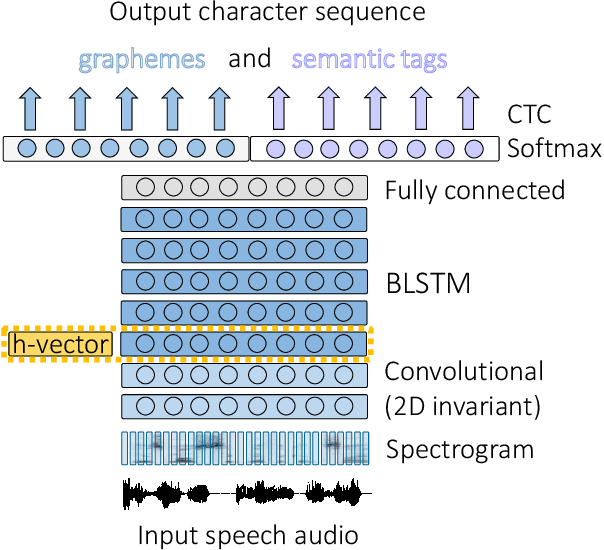


This work investigates the embeddings for representing dialog history in spoken language understanding (SLU) systems. We focus on the scenario when the semantic information is extracted directly from the speech signal by means of a single end-to-end neural network model. We proposed to integrate dialogue history into an end-to-end signal-to-concept SLU system. The dialog history is represented in the form of dialog history embedding vectors (so-called h-vectors) and is provided as an additional information to end-to-end SLU models in order to improve the system performance. Three following types of h-vectors are proposed and experimentally evaluated in this paper: (1) supervised-all embeddings predicting bag-of-concepts expected in the answer of the user from the last dialog system response; (2) supervised-freq embeddings focusing on predicting only a selected set of semantic concept (corresponding to the most frequent errors in our experiments); and (3) unsupervised embeddings. Experiments on the MEDIA corpus for the semantic slot filling task demonstrate that the proposed h-vectors improve the model performance.
Real to H-space Encoder for Speech Recognition
Jun 17, 2019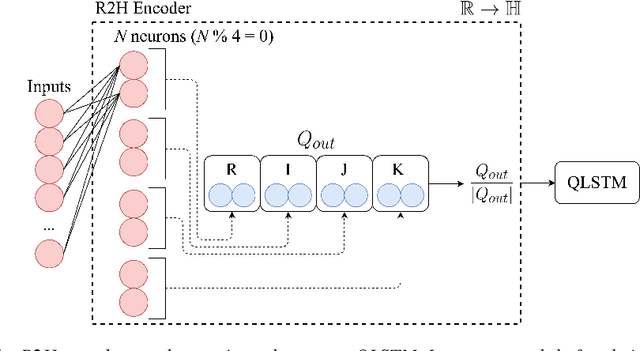
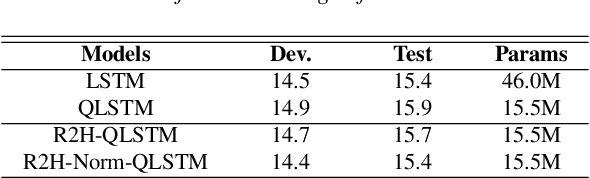
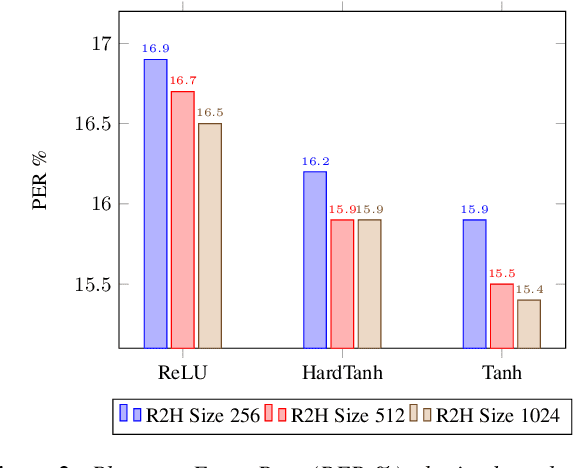
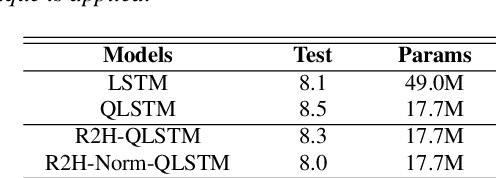
Deep neural networks (DNNs) and more precisely recurrent neural networks (RNNs) are at the core of modern automatic speech recognition systems, due to their efficiency to process input sequences. Recently, it has been shown that different input representations, based on multidimensional algebras, such as complex and quaternion numbers, are able to bring to neural networks a more natural, compressive and powerful representation of the input signal by outperforming common real-valued NNs. Indeed, quaternion-valued neural networks (QNNs) better learn both internal dependencies, such as the relation between the Mel-filter-bank value of a specific time frame and its time derivatives, and global dependencies, describing the relations that exist between time frames. Nonetheless, QNNs are limited to quaternion-valued input signals, and it is difficult to benefit from this powerful representation with real-valued input data. This paper proposes to tackle this weakness by introducing a real-to-quaternion encoder that allows QNNs to process any one dimensional input features, such as traditional Mel-filter-banks for automatic speech recognition.
Multiple topic identification in telephone conversations
Dec 29, 2018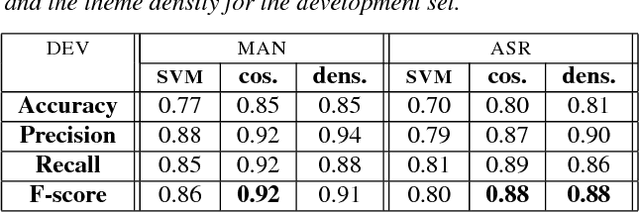
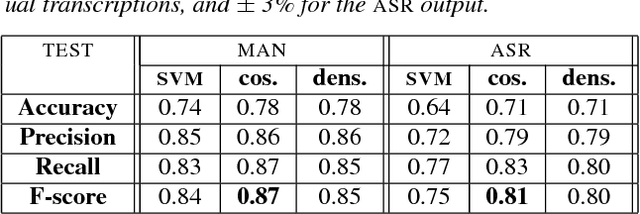
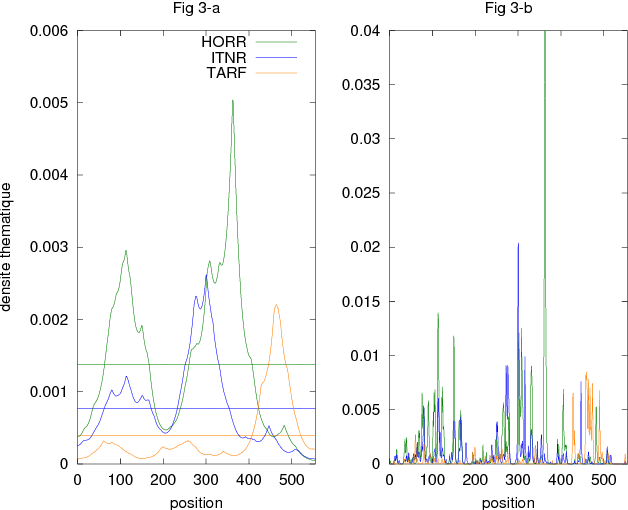
This paper deals with the automatic analysis of conversations between a customer and an agent in a call centre of a customer care service. The purpose of the analysis is to hypothesize themes about problems and complaints discussed in the conversation. Themes are defined by the application documentation topics. A conversation may contain mentions that are irrelevant for the application purpose and multiple themes whose mentions may be interleaved portions of a conversation that cannot be well defined. Two methods are proposed for multiple theme hypothesization. One of them is based on a cosine similarity measure using a bag of features extracted from the entire conversation. The other method introduces the concept of thematic density distributed around specific word positions in a conversation. In addition to automatically selected words, word bi-grams with possible gaps between successive words are also considered and selected. Experimental results show that the results obtained with the proposed methods outperform the results obtained with support vector machines on the same data. Furthermore, using the theme skeleton of a conversation from which thematic densities are derived, it will be possible to extract components of an automatic conversation report to be used for improving the service performance. Index Terms: multi-topic audio document classification, hu-man/human conversation analysis, speech analytics, distance bigrams
* arXiv admin note: text overlap with arXiv:1812.07207
Speech recognition with quaternion neural networks
Nov 21, 2018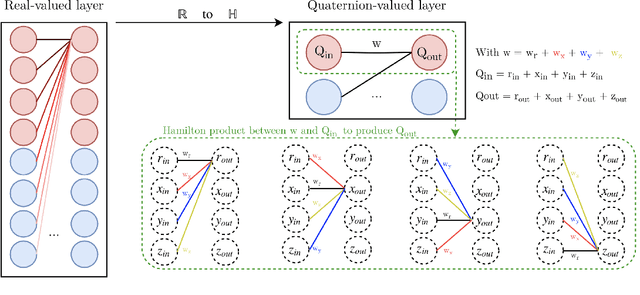
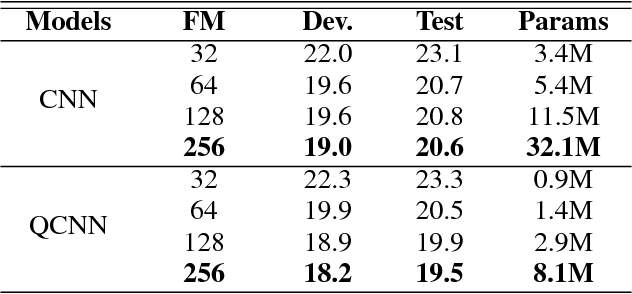
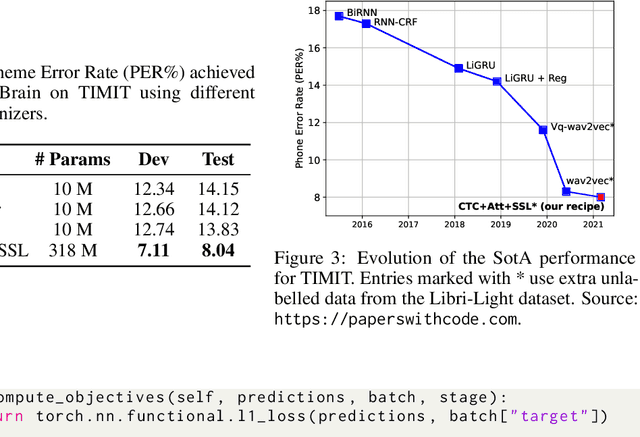
Neural network architectures are at the core of powerful automatic speech recognition systems (ASR). However, while recent researches focus on novel model architectures, the acoustic input features remain almost unchanged. Traditional ASR systems rely on multidimensional acoustic features such as the Mel filter bank energies alongside with the first, and second order derivatives to characterize time-frames that compose the signal sequence. Considering that these components describe three different views of the same element, neural networks have to learn both the internal relations that exist within these features, and external or global dependencies that exist between the time-frames. Quaternion-valued neural networks (QNN), recently received an important interest from researchers to process and learn such relations in multidimensional spaces. Indeed, quaternion numbers and QNNs have shown their efficiency to process multidimensional inputs as entities, to encode internal dependencies, and to solve many tasks with up to four times less learning parameters than real-valued models. We propose to investigate modern quaternion-valued models such as convolutional and recurrent quaternion neural networks in the context of speech recognition with the TIMIT dataset. The experiments show that QNNs always outperform real-valued equivalent models with way less free parameters, leading to a more efficient, compact, and expressive representation of the relevant information.
Bidirectional Quaternion Long-Short Term Memory Recurrent Neural Networks for Speech Recognition
Nov 06, 2018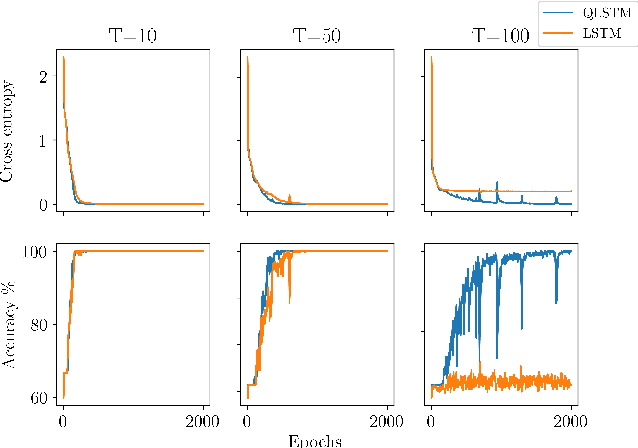
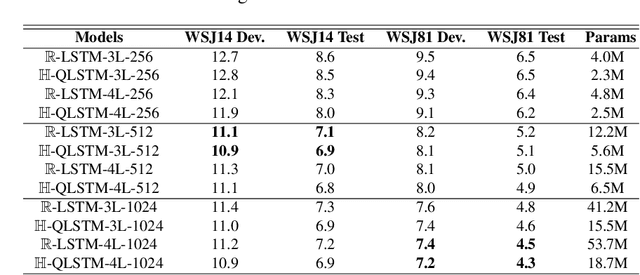
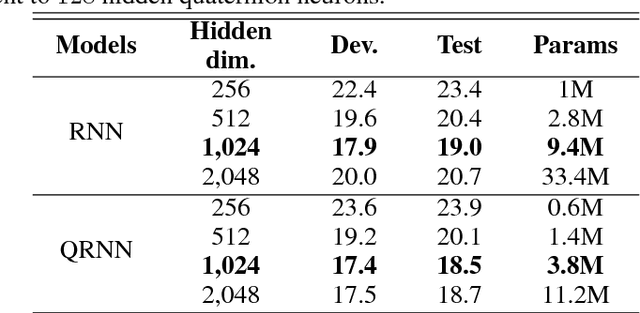
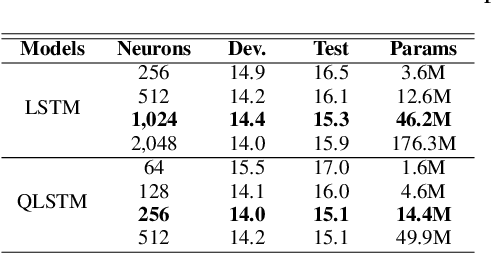
Recurrent neural networks (RNN) are at the core of modern automatic speech recognition (ASR) systems. In particular, long-short term memory (LSTM) recurrent neural networks have achieved state-of-the-art results in many speech recognition tasks, due to their efficient representation of long and short term dependencies in sequences of inter-dependent features. Nonetheless, internal dependencies within the element composing multidimensional features are weakly considered by traditional real-valued representations. We propose a novel quaternion long-short term memory (QLSTM) recurrent neural network that takes into account both the external relations between the features composing a sequence, and these internal latent structural dependencies with the quaternion algebra. QLSTMs are compared to LSTMs during a memory copy-task and a realistic application of speech recognition on the Wall Street Journal (WSJ) dataset. QLSTM reaches better performances during the two experiments with up to $2.8$ times less learning parameters, leading to a more expressive representation of the information.
Quaternion Recurrent Neural Networks
Jul 05, 2018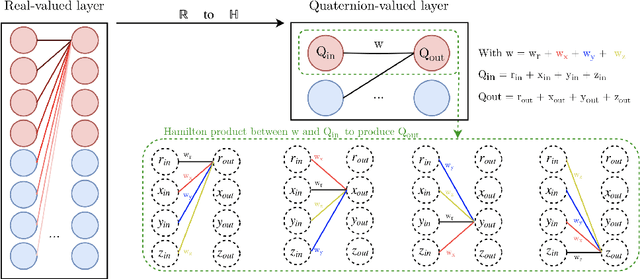
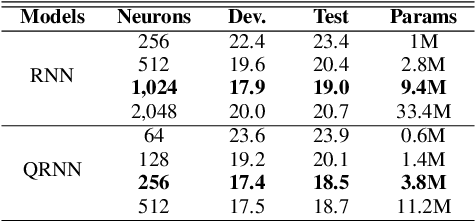

Recurrent neural networks (RNNs) are powerful architectures to model sequential data, due to their capability to learn short and long-term dependencies between the basic elements of a sequence. Nonetheless, popular tasks such as speech or images recognition, involve multi-dimensional input features that are characterized by strong internal dependencies between the dimensions of the input vector. We propose a novel quaternion recurrent neural network (QRNN) that takes into account both the external relations and these internal structural dependencies with the quaternion algebra. Similarly to capsules, quaternions allow the QRNN to code internal dependencies by composing and processing multidimensional features as single entities, while the recurrent operation reveals correlations between the elements composing the sequence. We show that the QRNN achieves better performances in both a synthetic memory copy task and in realistic applications of automatic speech recognition. Finally, we show that the QRNN reduces by a factor of 3x the number of free parameters needed, compared to RNNs to reach better results, leading to a more compact representation of the relevant information.
Quaternion Convolutional Neural Networks for End-to-End Automatic Speech Recognition
Jun 20, 2018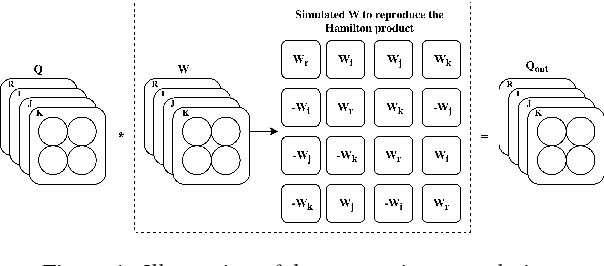
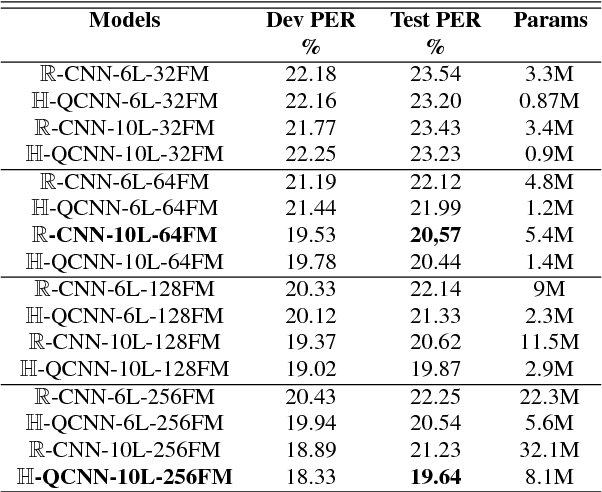
Recently, the connectionist temporal classification (CTC) model coupled with recurrent (RNN) or convolutional neural networks (CNN), made it easier to train speech recognition systems in an end-to-end fashion. However in real-valued models, time frame components such as mel-filter-bank energies and the cepstral coefficients obtained from them, together with their first and second order derivatives, are processed as individual elements, while a natural alternative is to process such components as composed entities. We propose to group such elements in the form of quaternions and to process these quaternions using the established quaternion algebra. Quaternion numbers and quaternion neural networks have shown their efficiency to process multidimensional inputs as entities, to encode internal dependencies, and to solve many tasks with less learning parameters than real-valued models. This paper proposes to integrate multiple feature views in quaternion-valued convolutional neural network (QCNN), to be used for sequence-to-sequence mapping with the CTC model. Promising results are reported using simple QCNNs in phoneme recognition experiments with the TIMIT corpus. More precisely, QCNNs obtain a lower phoneme error rate (PER) with less learning parameters than a competing model based on real-valued CNNs.