 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning Loss Functions for Deep Neural Networks
Jun 14, 2024Humans can often quickly and efficiently solve complex new learning tasks given only a small set of examples. In contrast, modern artificially intelligent systems often require thousands or millions of observations in order to solve even the most basic tasks. Meta-learning aims to resolve this issue by leveraging past experiences from similar learning tasks to embed the appropriate inductive biases into the learning system. Historically methods for meta-learning components such as optimizers, parameter initializations, and more have led to significant performance increases. This thesis aims to explore the concept of meta-learning to improve performance, through the often-overlooked component of the loss function. The loss function is a vital component of a learning system, as it represents the primary learning objective, where success is determined and quantified by the system's ability to optimize for that objective successfully.
Meta-Learning Neural Procedural Biases
Jun 12, 2024



The goal of few-shot learning is to generalize and achieve high performance on new unseen learning tasks, where each task has only a limited number of examples available. Gradient-based meta-learning attempts to address this challenging task by learning how to learn new tasks by embedding inductive biases informed by prior learning experiences into the components of the learning algorithm. In this work, we build upon prior research and propose Neural Procedural Bias Meta-Learning (NPBML), a novel framework designed to meta-learn task-adaptive procedural biases. Our approach aims to consolidate recent advancements in meta-learned initializations, optimizers, and loss functions by learning them simultaneously and making them adapt to each individual task to maximize the strength of the learned inductive biases. This imbues each learning task with a unique set of procedural biases which is specifically designed and selected to attain strong learning performance in only a few gradient steps. The experimental results show that by meta-learning the procedural biases of a neural network, we can induce strong inductive biases towards a distribution of learning tasks, enabling robust learning performance across many well-established few-shot learning benchmarks.
Fast and Efficient Local Search for Genetic Programming Based Loss Function Learning
Mar 01, 2024



In this paper, we develop upon the topic of loss function learning, an emergent meta-learning paradigm that aims to learn loss functions that significantly improve the performance of the models trained under them. Specifically, we propose a new meta-learning framework for task and model-agnostic loss function learning via a hybrid search approach. The framework first uses genetic programming to find a set of symbolic loss functions. Second, the set of learned loss functions is subsequently parameterized and optimized via unrolled differentiation. The versatility and performance of the proposed framework are empirically validated on a diverse set of supervised learning tasks. Results show that the learned loss functions bring improved convergence, sample efficiency, and inference performance on tabulated, computer vision, and natural language processing problems, using a variety of task-specific neural network architectures.
Online Loss Function Learning
Jan 30, 2023



Loss function learning is a new meta-learning paradigm that aims to automate the essential task of designing a loss function for a machine learning model. Existing techniques for loss function learning have shown promising results, often improving a model's training dynamics and final inference performance. However, a significant limitation of these techniques is that the loss functions are meta-learned in an offline fashion, where the meta-objective only considers the very first few steps of training, which is a significantly shorter time horizon than the one typically used for training deep neural networks. This causes significant bias towards loss functions that perform well at the very start of training but perform poorly at the end of training. To address this issue we propose a new loss function learning technique for adaptively updating the loss function online after each update to the base model parameters. The experimental results show that our proposed method consistently outperforms the cross-entropy loss and offline loss function learning techniques on a diverse range of neural network architectures and datasets.
Learning Symbolic Model-Agnostic Loss Functions via Meta-Learning
Sep 19, 2022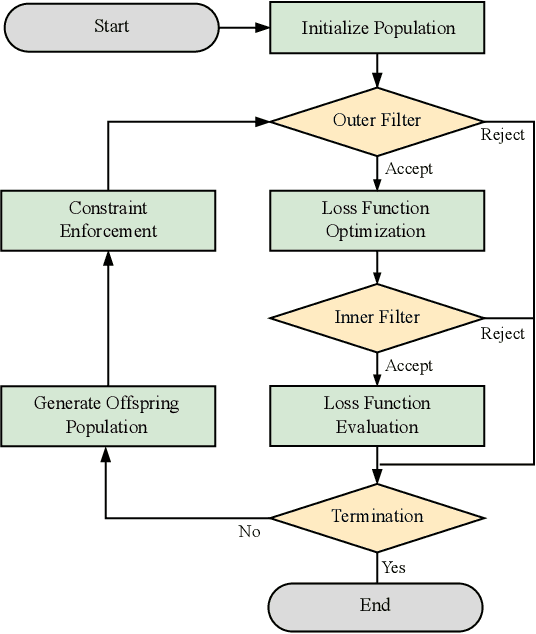
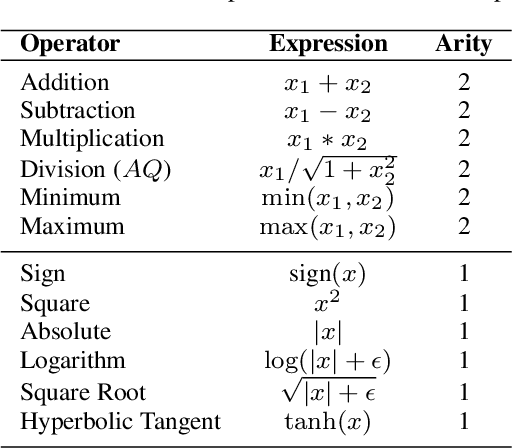
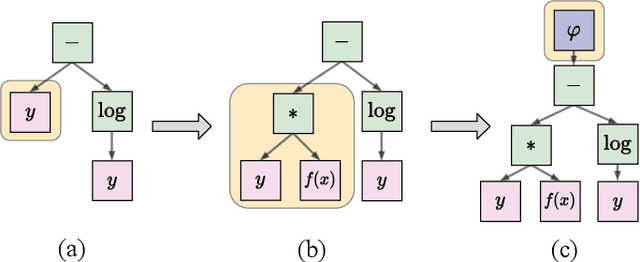

In this paper, we develop upon the emerging topic of loss function learning, which aims to learn loss functions that significantly improve the performance of the models trained under them. Specifically, we propose a new meta-learning framework for learning model-agnostic loss functions via a hybrid neuro-symbolic search approach. The framework first uses evolution-based methods to search the space of primitive mathematical operations to find a set of symbolic loss functions. Second, the set of learned loss functions are subsequently parameterized and optimized via an end-to-end gradient-based training procedure. The versatility of the proposed framework is empirically validated on a diverse set of supervised learning tasks. Results show that the meta-learned loss functions discovered by the newly proposed method outperform both the cross-entropy loss and state-of-the-art loss function learning methods on a diverse range of neural network architectures and datasets.
Dialogue history integration into end-to-end signal-to-concept spoken language understanding systems
Feb 14, 2020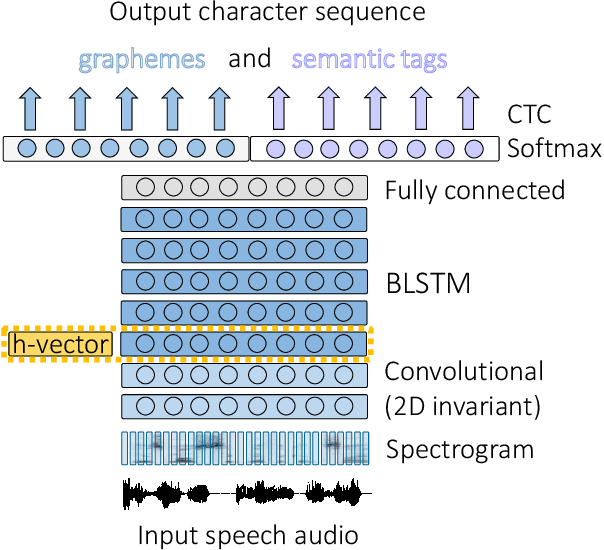
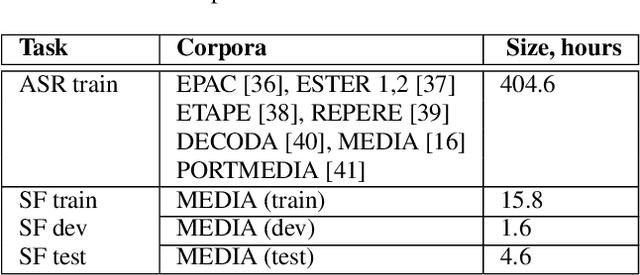


This work investigates the embeddings for representing dialog history in spoken language understanding (SLU) systems. We focus on the scenario when the semantic information is extracted directly from the speech signal by means of a single end-to-end neural network model. We proposed to integrate dialogue history into an end-to-end signal-to-concept SLU system. The dialog history is represented in the form of dialog history embedding vectors (so-called h-vectors) and is provided as an additional information to end-to-end SLU models in order to improve the system performance. Three following types of h-vectors are proposed and experimentally evaluated in this paper: (1) supervised-all embeddings predicting bag-of-concepts expected in the answer of the user from the last dialog system response; (2) supervised-freq embeddings focusing on predicting only a selected set of semantic concept (corresponding to the most frequent errors in our experiments); and (3) unsupervised embeddings. Experiments on the MEDIA corpus for the semantic slot filling task demonstrate that the proposed h-vectors improve the model performance.
One-Step Time-Dependent Future Video Frame Prediction with a Convolutional Encoder-Decoder Neural Network
Jul 24, 2017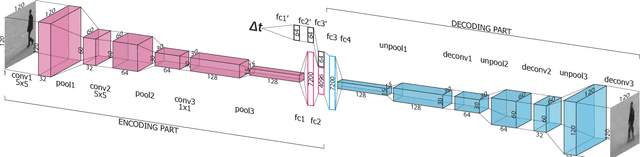
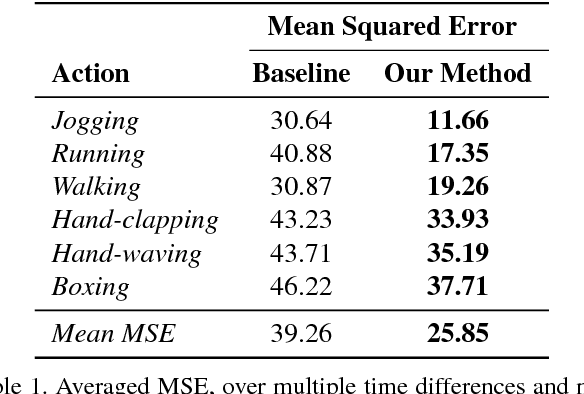


There is an inherent need for autonomous cars, drones, and other robots to have a notion of how their environment behaves and to anticipate changes in the near future. In this work, we focus on anticipating future appearance given the current frame of a video. Existing work focuses on either predicting the future appearance as the next frame of a video, or predicting future motion as optical flow or motion trajectories starting from a single video frame. This work stretches the ability of CNNs (Convolutional Neural Networks) to predict an anticipation of appearance at an arbitrarily given future time, not necessarily the next video frame. We condition our predicted future appearance on a continuous time variable that allows us to anticipate future frames at a given temporal distance, directly from the input video frame. We show that CNNs can learn an intrinsic representation of typical appearance changes over time and successfully generate realistic predictions at a deliberate time difference in the near future.