 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Building Efficient Zero-Shot Relation Extraction Models
Mar 04, 2026Zero-shot relation extraction aims to identify relations between entity mentions using textual descriptions of novel types (i.e., previously unseen) instead of labeled training examples. Previous works often rely on unrealistic assumptions: (1) pairs of mentions are often encoded directly in the input, which prevents offline pre-computation for large scale document database querying; (2) no rejection mechanism is introduced, biasing the evaluation when using these models in a retrieval scenario where some (and often most) inputs are irrelevant and must be ignored. In this work, we study the robustness of existing zero-shot relation extraction models when adapting them to a realistic extraction scenario. To this end, we introduce a typology of existing models, and propose several strategies to build single pass models and models with a rejection mechanism. We adapt several state-of-the-art tools, and compare them in this challenging setting, showing that no existing work is really robust to realistic assumptions, but overall AlignRE (Li et al., 2024) performs best along all criteria.
N-gram Injection into Transformers for Dynamic Language Model Adaptation in Handwritten Text Recognition
Mar 04, 2026Transformer-based encoder-decoder networks have recently achieved impressive results in handwritten text recognition, partly thanks to their auto-regressive decoder which implicitly learns a language model. However, such networks suffer from a large performance drop when evaluated on a target corpus whose language distribution is shifted from the source text seen during training. To retain recognition accuracy despite this language shift, we propose an external n-gram injection (NGI) for dynamic adaptation of the network's language modeling at inference time. Our method allows switching to an n-gram language model estimated on a corpus close to the target distribution, therefore mitigating bias without any extra training on target image-text pairs. We opt for an early injection of the n-gram into the transformer decoder so that the network learns to fully leverage text-only data at the low additional cost of n-gram inference. Experiments on three handwritten datasets demonstrate that the proposed NGI significantly reduces the performance gap between source and target corpora.
HYBRINFOX at CheckThat! 2024 -- Task 1: Enhancing Language Models with Structured Information for Check-Worthiness Estimation
Jul 04, 2024


This paper summarizes the experiments and results of the HYBRINFOX team for the CheckThat! 2024 - Task 1 competition. We propose an approach enriching Language Models such as RoBERTa with embeddings produced by triples (subject ; predicate ; object) extracted from the text sentences. Our analysis of the developmental data shows that this method improves the performance of Language Models alone. On the evaluation data, its best performance was in English, where it achieved an F1 score of 71.1 and ranked 12th out of 27 candidates. On the other languages (Dutch and Arabic), it obtained more mixed results. Future research tracks are identified toward adapting this processing pipeline to more recent Large Language Models.
HYBRINFOX at CheckThat! 2024 -- Task 2: Enriching BERT Models with the Expert System VAGO for Subjectivity Detection
Jul 04, 2024

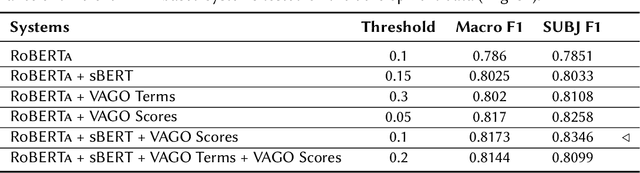

This paper presents the HYBRINFOX method used to solve Task 2 of Subjectivity detection of the CLEF 2024 CheckThat! competition. The specificity of the method is to use a hybrid system, combining a RoBERTa model, fine-tuned for subjectivity detection, a frozen sentence-BERT (sBERT) model to capture semantics, and several scores calculated by the English version of the expert system VAGO, developed independently of this task to measure vagueness and subjectivity in texts based on the lexicon. In English, the HYBRINFOX method ranked 1st with a macro F1 score of 0.7442 on the evaluation data. For the other languages, the method used a translation step into English, producing more mixed results (ranking 1st in Multilingual and 2nd in Italian over the baseline, but under the baseline in Bulgarian, German, and Arabic). We explain the principles of our hybrid approach, and outline ways in which the method could be improved for other languages besides English.
Exposing propaganda: an analysis of stylistic cues comparing human annotations and machine classification
Feb 07, 2024

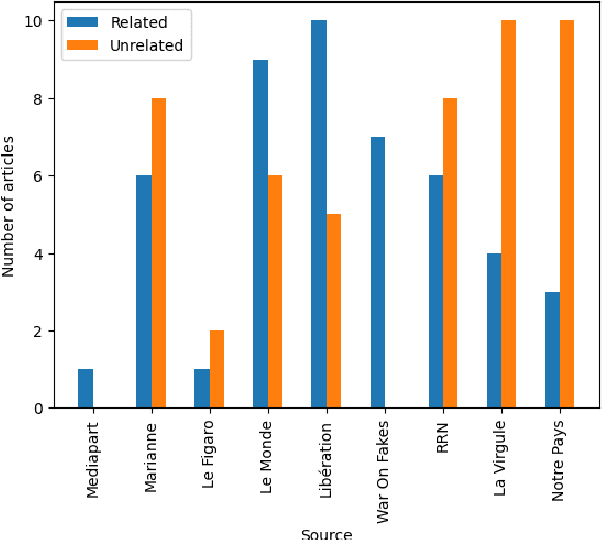
This paper investigates the language of propaganda and its stylistic features. It presents the PPN dataset, standing for Propagandist Pseudo-News, a multisource, multilingual, multimodal dataset composed of news articles extracted from websites identified as propaganda sources by expert agencies. A limited sample from this set was randomly mixed with papers from the regular French press, and their URL masked, to conduct an annotation-experiment by humans, using 11 distinct labels. The results show that human annotators were able to reliably discriminate between the two types of press across each of the labels. We propose different NLP techniques to identify the cues used by the annotators, and to compare them with machine classification. They include the analyzer VAGO to measure discourse vagueness and subjectivity, a TF-IDF to serve as a baseline, and four different classifiers: two RoBERTa-based models, CATS using syntax, and one XGBoost combining syntactic and semantic features.
Rethinking deep active learning: Using unlabeled data at model training
Nov 19, 2019
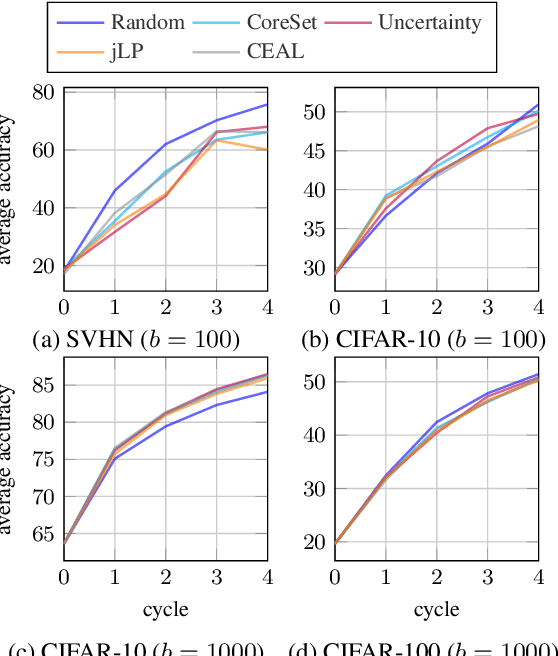
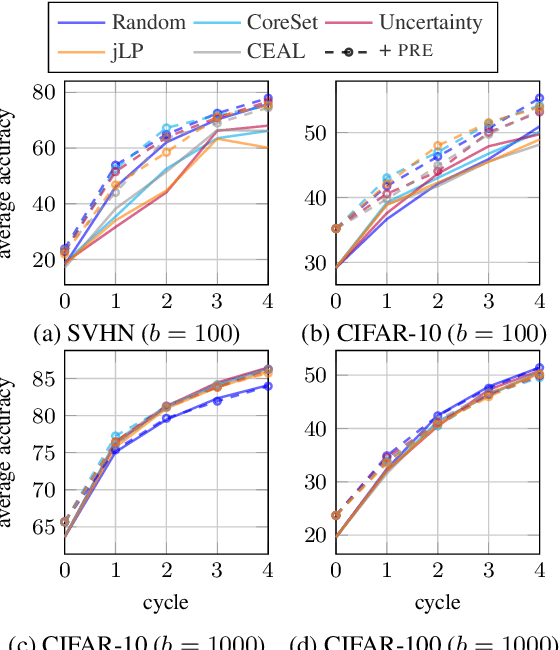
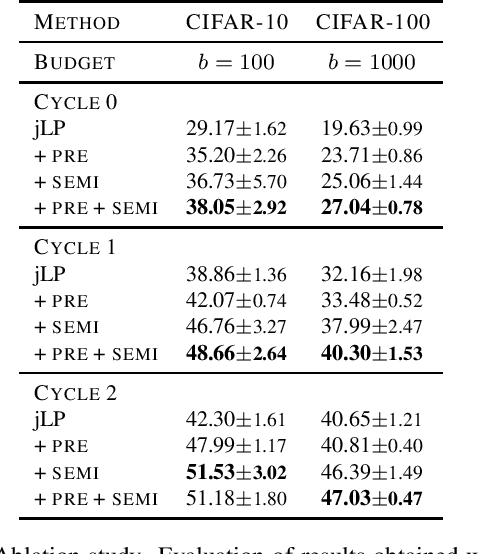
Active learning typically focuses on training a model on few labeled examples alone, while unlabeled ones are only used for acquisition. In this work we depart from this setting by using both labeled and unlabeled data during model training across active learning cycles. We do so by using unsupervised feature learning at the beginning of the active learning pipeline and semi-supervised learning at every active learning cycle, on all available data. The former has not been investigated before in active learning, while the study of latter in the context of deep learning is scarce and recent findings are not conclusive with respect to its benefit. Our idea is orthogonal to acquisition strategies by using more data, much like ensemble methods use more models. By systematically evaluating on a number of popular acquisition strategies and datasets, we find that the use of unlabeled data during model training brings a surprising accuracy improvement in image classification, compared to the differences between acquisition strategies. We thus explore smaller label budgets, even one label per class.
AI in the media and creative industries
May 10, 2019Thanks to the Big Data revolution and increasing computing capacities, Artificial Intelligence (AI) has made an impressive revival over the past few years and is now omnipresent in both research and industry. The creative sectors have always been early adopters of AI technologies and this continues to be the case. As a matter of fact, recent technological developments keep pushing the boundaries of intelligent systems in creative applications: the critically acclaimed movie "Sunspring", released in 2016, was entirely written by AI technology, and the first-ever Music Album, called "Hello World", produced using AI has been released this year. Simultaneously, the exploratory nature of the creative process is raising important technical challenges for AI such as the ability for AI-powered techniques to be accurate under limited data resources, as opposed to the conventional "Big Data" approach, or the ability to process, analyse and match data from multiple modalities (text, sound, images, etc.) at the same time. The purpose of this white paper is to understand future technological advances in AI and their growing impact on creative industries. This paper addresses the following questions: Where does AI operate in creative Industries? What is its operative role? How will AI transform creative industries in the next ten years? This white paper aims to provide a realistic perspective of the scope of AI actions in creative industries, proposes a vision of how this technology could contribute to research and development works in such context, and identifies research and development challenges.
One-Step Time-Dependent Future Video Frame Prediction with a Convolutional Encoder-Decoder Neural Network
Jul 24, 2017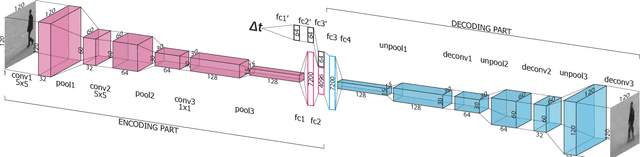
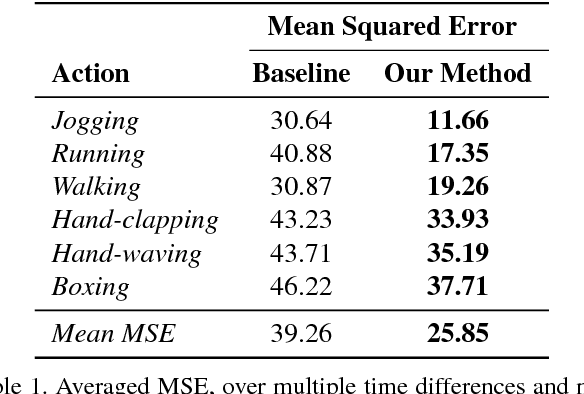


There is an inherent need for autonomous cars, drones, and other robots to have a notion of how their environment behaves and to anticipate changes in the near future. In this work, we focus on anticipating future appearance given the current frame of a video. Existing work focuses on either predicting the future appearance as the next frame of a video, or predicting future motion as optical flow or motion trajectories starting from a single video frame. This work stretches the ability of CNNs (Convolutional Neural Networks) to predict an anticipation of appearance at an arbitrarily given future time, not necessarily the next video frame. We condition our predicted future appearance on a continuous time variable that allows us to anticipate future frames at a given temporal distance, directly from the input video frame. We show that CNNs can learn an intrinsic representation of typical appearance changes over time and successfully generate realistic predictions at a deliberate time difference in the near future.
Utilisation de la linguistique en reconnaissance de la parole : un état de l'art
May 30, 2006To transcribe speech, automatic speech recognition systems use statistical methods, particularly hidden Markov model and N-gram models. Although these techniques perform well and lead to efficient systems, they approach their maximum possibilities. It seems thus necessary, in order to outperform current results, to use additional information, especially bound to language. However, introducing such knowledge must be realized taking into account specificities of spoken language (hesitations for example) and being robust to possible misrecognized words. This document presents a state of the art of these researches, evaluating the impact of the insertion of linguistic information on the quality of the transcription.