 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of utterance duration and phonetic content on speaker identification using second-order statistical methods
Feb 26, 2024

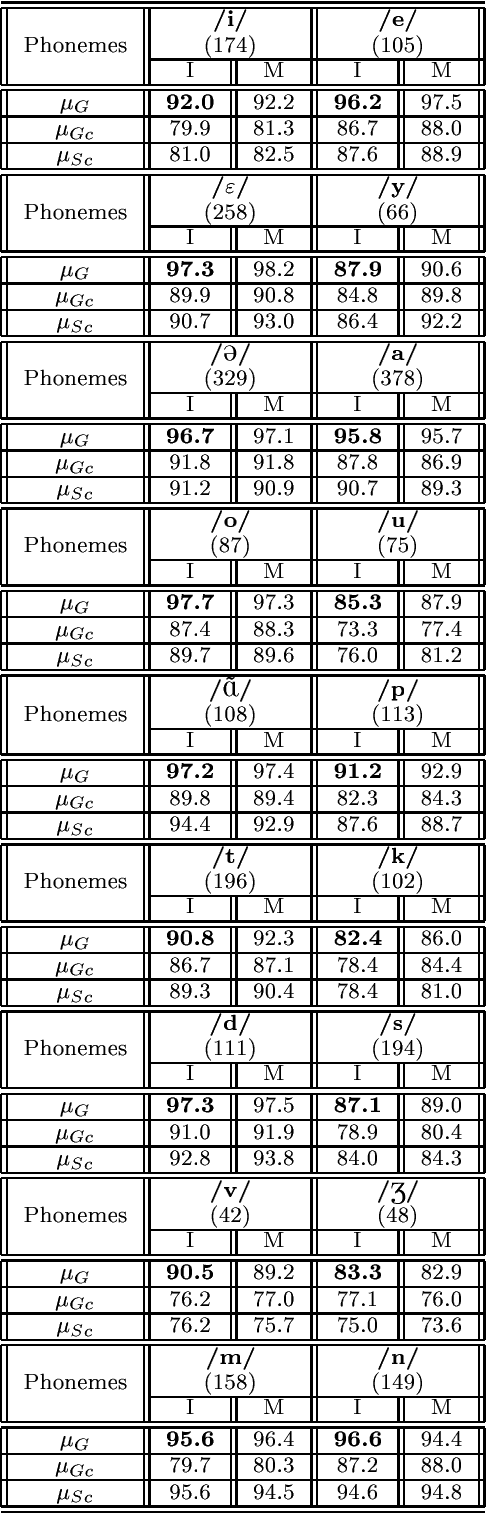
Second-order statistical methods show very good results for automatic speaker identification in controlled recording conditions. These approaches are generally used on the entire speech material available. In this paper, we study the influence of the content of the test speech material on the performances of such methods, i.e. under a more analytical approach. The goal is to investigate on the kind of information which is used by these methods, and where it is located in the speech signal. Liquids and glides together, vowels, and more particularly nasal vowels and nasal consonants, are found to be particularly speaker specific: test utterances of 1 second, composed in majority of acoustic material from one of these classes provide better speaker identification results than phonetically balanced test utterances, even though the training is done, in both cases, with 15 seconds of phonetically balanced speech. Nevertheless, results with other phoneme classes are never dramatically poor. These results tend to show that the speaker-dependent information captured by long-term second-order statistics is consistently common to all phonetic classes, and that the homogeneity of the test material may improve the quality of the estimates.
Barwise Music Structure Analysis with the Correlation Block-Matching Segmentation Algorithm
Nov 30, 2023



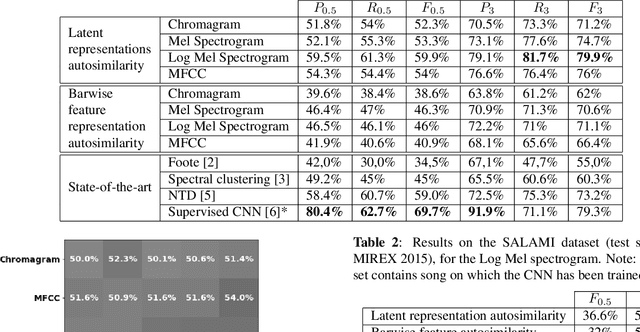
Music Structure Analysis (MSA) is a Music Information Retrieval task consisting of representing a song in a simplified, organized manner by breaking it down into sections typically corresponding to ``chorus'', ``verse'', ``solo'', etc. In this work, we extend an MSA algorithm called the Correlation Block-Matching (CBM) algorithm introduced by (Marmoret et al., 2020, 2022b). The CBM algorithm is a dynamic programming algorithm that segments self-similarity matrices, which are a standard description used in MSA and in numerous other applications. In this work, self-similarity matrices are computed from the feature representation of an audio signal and time is sampled at the bar-scale. This study examines three different standard similarity functions for the computation of self-similarity matrices. Results show that, in optimal conditions, the proposed algorithm achieves a level of performance which is competitive with supervised state-of-the-art methods while only requiring knowledge of bar positions. In addition, the algorithm is made open-source and is highly customizable.
* 19 pages, 13 figures, 11 tables, 1 algorithm, published in Transactions of the International Society for Music Information Retrieval
Polytopic Analysis of Music
Dec 22, 2022



Structural segmentation of music refers to the task of finding a symbolic representation of the organisation of a song, reducing the musical flow to a partition of non-overlapping segments. Under this definition, the musical structure may not be unique, and may even be ambiguous. One way to resolve that ambiguity is to see this task as a compression process, and to consider the musical structure as the optimization of a given compression criteria. In that viewpoint, C. Guichaoua developed a compression-driven model for retrieving the musical structure, based on the "System and Contrast" model, and on polytopes, which are extension of nhypercubes. We present this model, which we call "polytopic analysis of music", along with a new opensource dedicated toolbox called MusicOnPolytopes (in Python). This model is also extended to the use of the Tonnetz as a relation system. Structural segmentation experiments are conducted on the RWC Pop dataset. Results show improvements compared to the previous ones, presented by C. Guichaoua.
Convolutive Block-Matching Segmentation Algorithm with Application to Music Structure Analysis
Oct 27, 2022



Music Structure Analysis (MSA) consists of representing a song in sections (such as ``chorus'', ``verse'', ``solo'' etc), and can be seen as the retrieval of a simplified organization of the song. This work presents a new algorithm, called Convolutive Block-Matching (CBM) algorithm, devoted to MSA. In particular, the CBM algorithm is a dynamic programming algorithm, applying on autosimilarity matrices, a standard tool in MSA. In this work, autosimilarity matrices are computed from the feature representation of an audio signal, and time is sampled on the barscale. We study three different similarity functions for the computation of autosimilarity matrices. We report that the proposed algorithm achieves a level of performance competitive to that of supervised state-of-the-art methods on 3 among 4 metrics, while being fully unsupervised.
Barwise Compression Schemes for Audio-Based Music Structure Analysis
Feb 10, 2022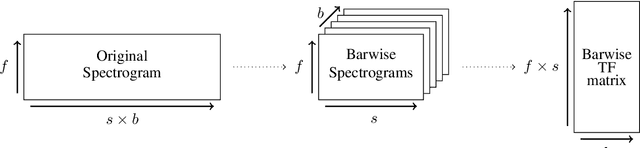
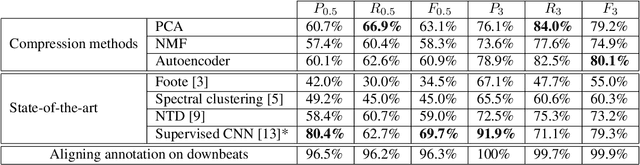
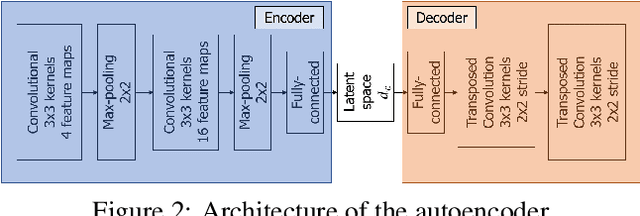
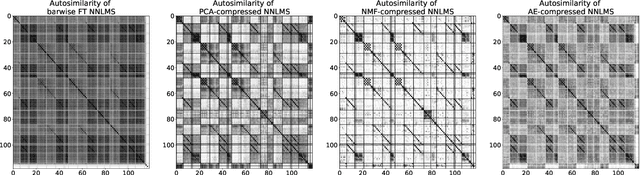
Music Structure Analysis (MSA) consists in segmenting a music piece in several distinct sections. We approach MSA within a compression framework, under the hypothesis that the structure is more easily revealed by a simplified representation of the original content of the song. More specifically, under the hypothesis that MSA is correlated with similarities occurring at the bar scale, linear and non-linear compression schemes can be applied to barwise audio signals. Compressed representations capture the most salient components of the different bars in the song and are then used to infer the song structure using a dynamic programming algorithm. This work explores both low-rank approximation models such as Principal Component Analysis or Nonnegative Matrix Factorization and "piece-specific" Auto-Encoding Neural Networks, with the objective to learn latent representations specific to a given song. Such approaches do not rely on supervision nor annotations, which are well-known to be tedious to collect and possibly ambiguous in MSA description. In our experiments, several unsupervised compression schemes achieve a level of performance comparable to that of state-of-the-art supervised methods (for 3s tolerance) on the RWC-Pop dataset, showcasing the importance of the barwise compression processing for MSA.
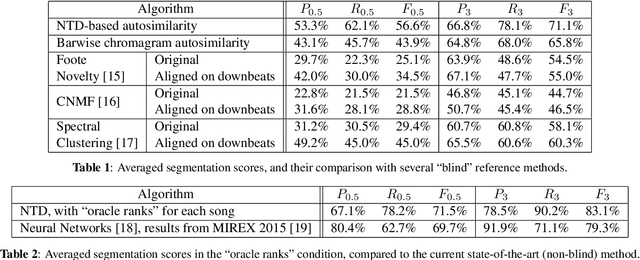
Nonnegative Tucker Decomposition with Beta-divergence for Music Structure Analysis of audio signals
Nov 04, 2021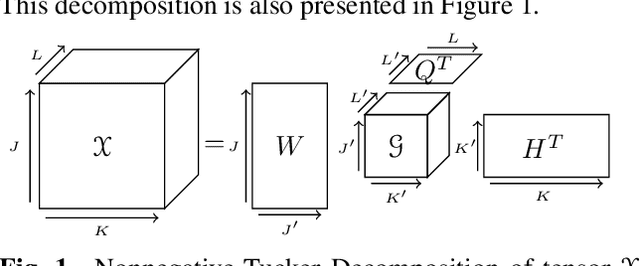
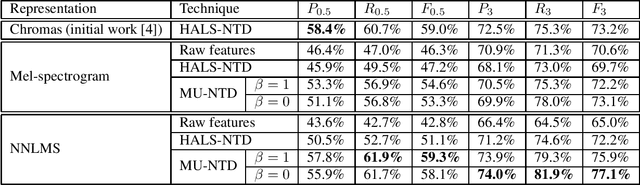

Nonnegative Tucker Decomposition (NTD), a tensor decomposition model, has received increased interest in the recent years because of its ability to blindly extract meaningful patterns in tensor data. Nevertheless, existing algorithms to compute NTD are mostly designed for the Euclidean loss. On the other hand, NTD has recently proven to be a powerful tool in Music Information Retrieval. This work proposes a Multiplicative Updates algorithm to compute NTD with the beta-divergence loss, often considered a better loss for audio processing. We notably show how to implement efficiently the multiplicative rules using tensor algebra, a naive approach being intractable. Finally, we show on a Music Structure Analysis task that unsupervised NTD fitted with beta-divergence loss outperforms earlier results obtained with the Euclidean loss.
Exploring single-song autoencoding schemes for audio-based music structure analysis
Oct 27, 2021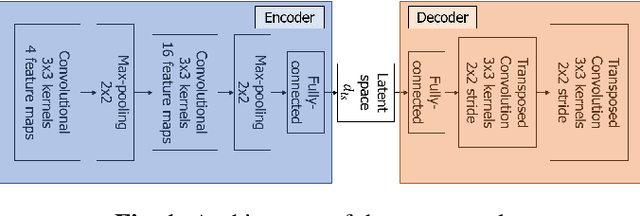
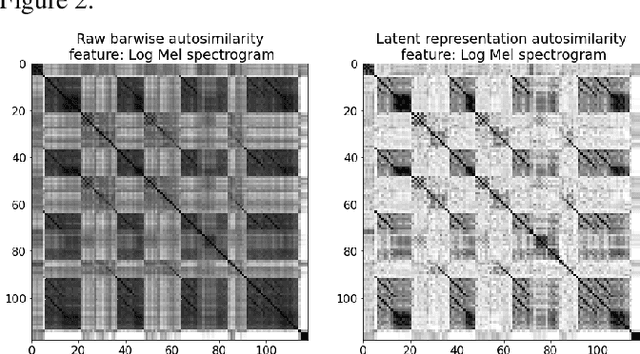

The ability of deep neural networks to learn complex data relations and representations is established nowadays, but it generally relies on large sets of training data. This work explores a "piece-specific" autoencoding scheme, in which a low-dimensional autoencoder is trained to learn a latent/compressed representation specific to a given song, which can then be used to infer the song structure. Such a model does not rely on supervision nor annotations, which are well-known to be tedious to collect and often ambiguous in Music Structure Analysis. We report that the proposed unsupervised auto-encoding scheme achieves the level of performance of supervised state-of-the-art methods with 3 seconds tolerance when using a Log Mel spectrogram representation on the RWC-Pop dataset.
Uncovering audio patterns in music with Nonnegative Tucker Decomposition for structural segmentation
Apr 17, 2021
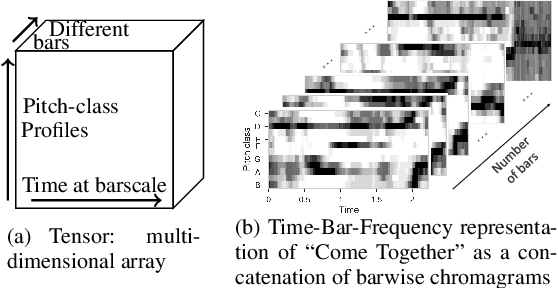
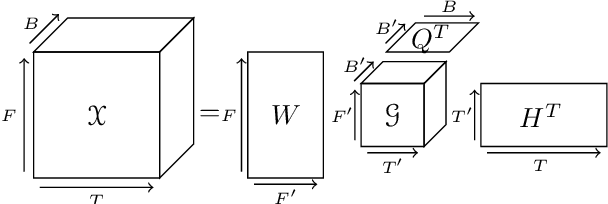
Recent work has proposed the use of tensor decomposition to model repetitions and to separate tracks in loop-based electronic music. The present work investigates further on the ability of Nonnegative Tucker Decompositon (NTD) to uncover musical patterns and structure in pop songs in their audio form. Exploiting the fact that NTD tends to express the content of bars as linear combinations of a few patterns, we illustrate the ability of the decomposition to capture and single out repeated motifs in the corresponding compressed space, which can be interpreted from a musical viewpoint. The resulting features also turn out to be efficient for structural segmentation, leading to experimental results on the RWC Pop data set which are potentially challenging state-of-the-art approaches that rely on extensive example-based learning schemes.
* 7 pages, 6 figures; Code and experiments details available at https://gitlab.inria.fr/amarmore/musicntd/-/tree/0.1.0; Experiments details available at https://ax-le.github.io/resources/ISMIR2020/Notebooks_mainpage.html
AI in the media and creative industries
May 10, 2019Thanks to the Big Data revolution and increasing computing capacities, Artificial Intelligence (AI) has made an impressive revival over the past few years and is now omnipresent in both research and industry. The creative sectors have always been early adopters of AI technologies and this continues to be the case. As a matter of fact, recent technological developments keep pushing the boundaries of intelligent systems in creative applications: the critically acclaimed movie "Sunspring", released in 2016, was entirely written by AI technology, and the first-ever Music Album, called "Hello World", produced using AI has been released this year. Simultaneously, the exploratory nature of the creative process is raising important technical challenges for AI such as the ability for AI-powered techniques to be accurate under limited data resources, as opposed to the conventional "Big Data" approach, or the ability to process, analyse and match data from multiple modalities (text, sound, images, etc.) at the same time. The purpose of this white paper is to understand future technological advances in AI and their growing impact on creative industries. This paper addresses the following questions: Where does AI operate in creative Industries? What is its operative role? How will AI transform creative industries in the next ten years? This white paper aims to provide a realistic perspective of the scope of AI actions in creative industries, proposes a vision of how this technology could contribute to research and development works in such context, and identifies research and development challenges.