 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Tensor Network: Tubal Tensor Train and Its Applications
Mar 11, 2026We introduce the tubal tensor train (TTT) decomposition, a tensor-network model that combines the t-product algebra of the tensor singular value decomposition (T-SVD) with the low-order core structure of the tensor train (TT) format. For an order-$(N+1)$ tensor with a distinguished tube mode, the proposed representation consists of two third-order boundary cores and $N-2$ fourth-order interior cores linked through the t-product. As a result, for bounded tubal ranks, the storage scales linearly with the number of modes, in contrast to direct high-order extensions of T-SVD. We present two computational strategies: a sequential fixed-rank construction, called TTT-SVD, and a Fourier-slice alternating scheme based on the alternating two-cores update (ATCU). We also state a TT-SVD-type error bound for TTT-SVD and illustrate the practical performance of the proposed model on image compression, video compression, tensor completion, and hyperspectral imaging.
A Provably-Correct and Robust Convex Model for Smooth Separable NMF
Nov 10, 2025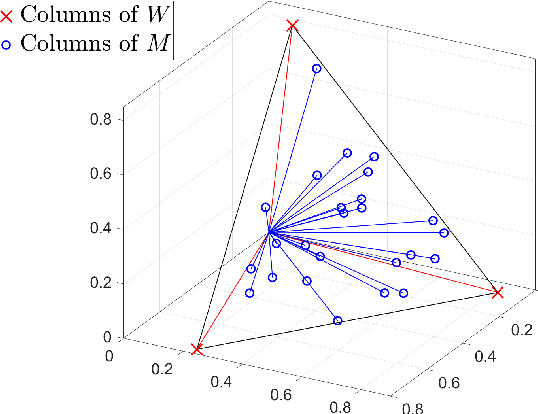
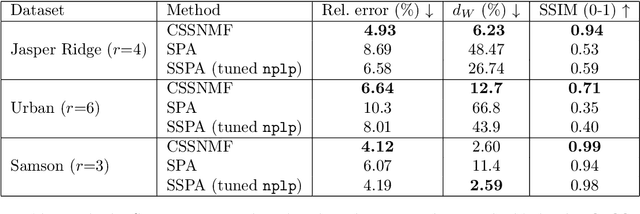
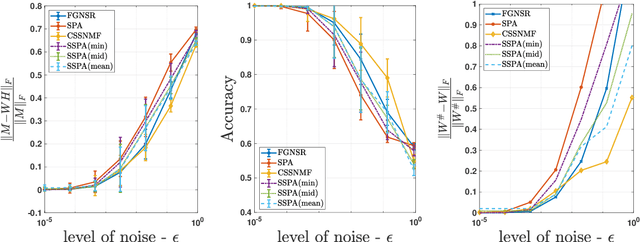
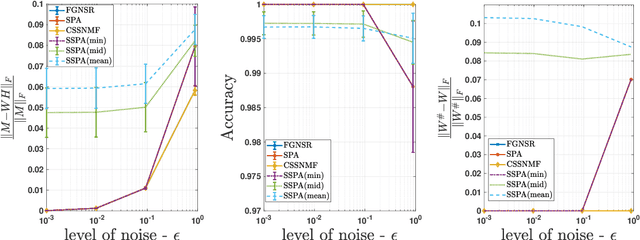
Nonnegative matrix factorization (NMF) is a linear dimensionality reduction technique for nonnegative data, with applications such as hyperspectral unmixing and topic modeling. NMF is a difficult problem in general (NP-hard), and its solutions are typically not unique. To address these two issues, additional constraints or assumptions are often used. In particular, separability assumes that the basis vectors in the NMF are equal to some columns of the input matrix. In that case, the problem is referred to as separable NMF (SNMF) and can be solved in polynomial-time with robustness guarantees, while identifying a unique solution. However, in real-world scenarios, due to noise or variability, multiple data points may lie near the basis vectors, which SNMF does not leverage. In this work, we rely on the smooth separability assumption, which assumes that each basis vector is close to multiple data points. We explore the properties of the corresponding problem, referred to as smooth SNMF (SSNMF), and examine how it relates to SNMF and orthogonal NMF. We then propose a convex model for SSNMF and show that it provably recovers the sought-after factors, even in the presence of noise. We finally adapt an existing fast gradient method to solve this convex model for SSNMF, and show that it compares favorably with state-of-the-art methods on both synthetic and hyperspectral datasets.
Efficient Algorithms for Regularized Nonnegative Scale-invariant Low-rank Approximation Models
Mar 27, 2024Regularized nonnegative low-rank approximations such as sparse Nonnegative Matrix Factorization or sparse Nonnegative Tucker Decomposition are an important branch of dimensionality reduction models with enhanced interpretability. However, from a practical perspective, the choice of regularizers and regularization coefficients, as well as the design of efficient algorithms, is challenging because of the multifactor nature of these models and the lack of theory to back these choices. This paper aims at improving upon these issues. By studying a more general model called the Homogeneous Regularized Scale-Invariant, we prove that the scale-invariance inherent to low-rank approximation models causes an implicit regularization with both unexpected beneficial and detrimental effects. This observation allows to better understand the effect of regularization functions in low-rank approximation models, to guide the choice of the regularization hyperparameters, and to design balancing strategies to enhance the convergence speed of dedicated optimization algorithms. Some of these results were already known but restricted to specific instances of regularized low-rank approximations. We also derive a generic Majorization Minimization algorithm that handles many regularized nonnegative low-rank approximations, with convergence guarantees. We showcase our contributions on sparse Nonnegative Matrix Factorization, ridge-regularized Canonical Polyadic decomposition and sparse Nonnegative Tucker Decomposition.
Block Majorization Minimization with Extrapolation and Application to $β$-NMF
Jan 12, 2024



We propose a Block Majorization Minimization method with Extrapolation (BMMe) for solving a class of multi-convex optimization problems. The extrapolation parameters of BMMe are updated using a novel adaptive update rule. By showing that block majorization minimization can be reformulated as a block mirror descent method, with the Bregman divergence adaptively updated at each iteration, we establish subsequential convergence for BMMe. We use this method to design efficient algorithms to tackle nonnegative matrix factorization problems with the $\beta$-divergences ($\beta$-NMF) for $\beta\in [1,2]$. These algorithms, which are multiplicative updates with extrapolation, benefit from our novel results that offer convergence guarantees. We also empirically illustrate the significant acceleration of BMMe for $\beta$-NMF through extensive experiments.
Deep Nonnegative Matrix Factorization with Beta Divergences
Sep 15, 2023Deep Nonnegative Matrix Factorization (deep NMF) has recently emerged as a valuable technique for extracting multiple layers of features across different scales. However, all existing deep NMF models and algorithms have primarily centered their evaluation on the least squares error, which may not be the most appropriate metric for assessing the quality of approximations on diverse datasets. For instance, when dealing with data types such as audio signals and documents, it is widely acknowledged that $\beta$-divergences offer a more suitable alternative. In this paper, we develop new models and algorithms for deep NMF using $\beta$-divergences. Subsequently, we apply these techniques to the extraction of facial features, the identification of topics within document collections, and the identification of materials within hyperspectral images.
NAG-GS: Semi-Implicit, Accelerated and Robust Stochastic Optimizers
Sep 29, 2022
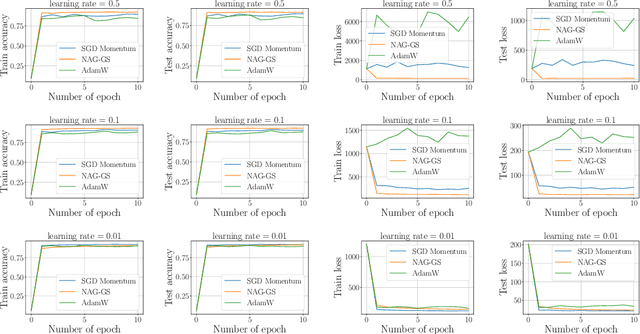
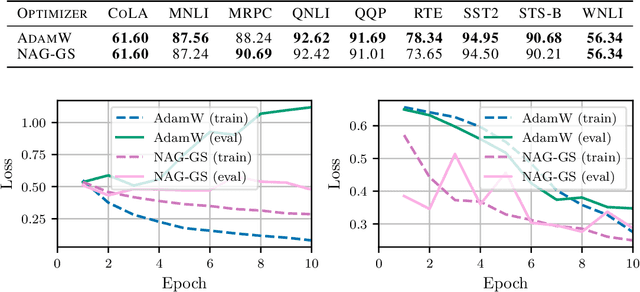
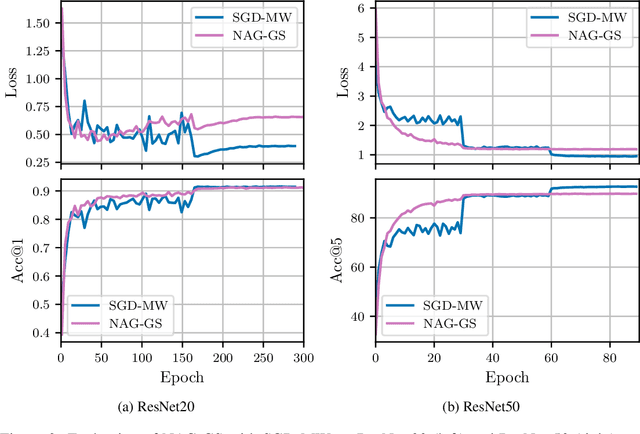
Classical machine learning models such as deep neural networks are usually trained by using Stochastic Gradient Descent-based (SGD) algorithms. The classical SGD can be interpreted as a discretization of the stochastic gradient flow. In this paper we propose a novel, robust and accelerated stochastic optimizer that relies on two key elements: (1) an accelerated Nesterov-like Stochastic Differential Equation (SDE) and (2) its semi-implicit Gauss-Seidel type discretization. The convergence and stability of the obtained method, referred to as NAG-GS, are first studied extensively in the case of the minimization of a quadratic function. This analysis allows us to come up with an optimal step size (or learning rate) in terms of rate of convergence while ensuring the stability of NAG-GS. This is achieved by the careful analysis of the spectral radius of the iteration matrix and the covariance matrix at stationarity with respect to all hyperparameters of our method. We show that NAG-GS is competitive with state-of-the-art methods such as momentum SGD with weight decay and AdamW for the training of machine learning models such as the logistic regression model, the residual networks models on standard computer vision datasets, and Transformers in the frame of the GLUE benchmark.
Nonnegative Tucker Decomposition with Beta-divergence for Music Structure Analysis of audio signals
Nov 04, 2021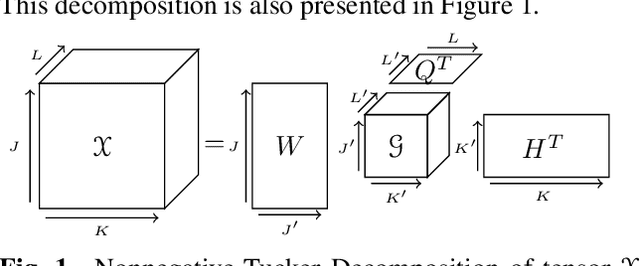
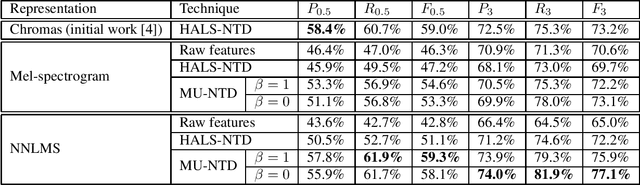

Nonnegative Tucker Decomposition (NTD), a tensor decomposition model, has received increased interest in the recent years because of its ability to blindly extract meaningful patterns in tensor data. Nevertheless, existing algorithms to compute NTD are mostly designed for the Euclidean loss. On the other hand, NTD has recently proven to be a powerful tool in Music Information Retrieval. This work proposes a Multiplicative Updates algorithm to compute NTD with the beta-divergence loss, often considered a better loss for audio processing. We notably show how to implement efficiently the multiplicative rules using tensor algebra, a naive approach being intractable. Finally, we show on a Music Structure Analysis task that unsupervised NTD fitted with beta-divergence loss outperforms earlier results obtained with the Euclidean loss.
Multiplicative Updates for NMF with $β$-Divergences under Disjoint Equality Constraints
Oct 30, 2020



Nonnegative matrix factorization (NMF) is the problem of approximating an input nonnegative matrix, $V$, as the product of two smaller nonnegative matrices, $W$ and $H$. In this paper, we introduce a general framework to design multiplicative updates (MU) for NMF based on $\beta$-divergences ($\beta$-NMF) with disjoint equality constraints, and with penalty terms in the objective function. By disjoint, we mean that each variable appears in at most one equality constraint. Our MU satisfy the set of constraints after each update of the variables during the optimization process, while guaranteeing that the objective function decreases monotonically. We showcase this framework on three NMF models, and show that it competes favorably the state of the art: (1)~$\beta$-NMF with sum-to-one constraints on the columns of $H$, (2) minimum-volume $\beta$-NMF with sum-to-one constraints on the columns of $W$, and (3) sparse $\beta$-NMF with $\ell_2$-norm constraints on the columns of $W$.
Blind Audio Source Separation with Minimum-Volume Beta-Divergence NMF
Jul 04, 2019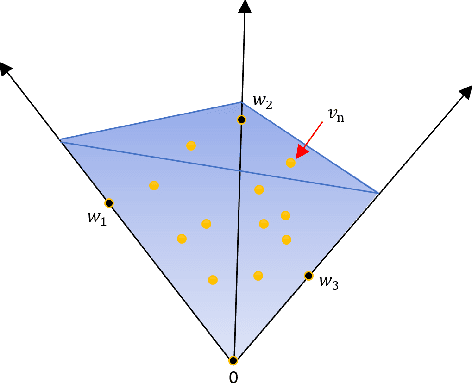
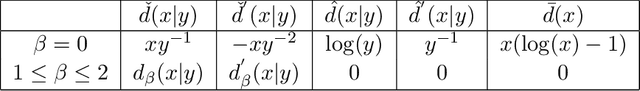
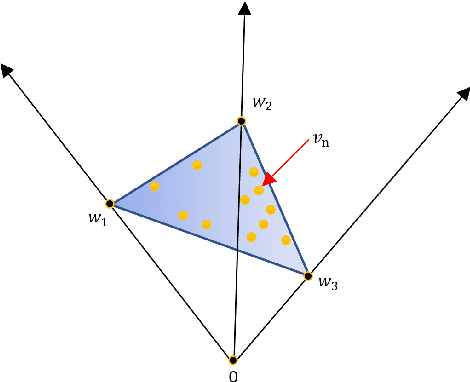
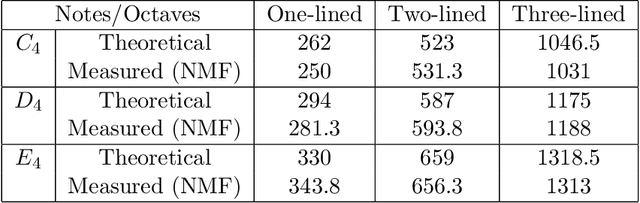
Considering a mixed signal composed of various audio sources and recorded with a single microphone, we consider on this paper the blind audio source separation problem which consists in isolating and extracting each of the sources. To perform this task, nonnegative matrix factorization (NMF) based on the Kullback-Leibler and Itakura-Saito $\beta$-divergences is a standard and state-of-the-art technique that uses the time-frequency representation of the signal. We present a new NMF model better suited for this task. It is based on the minimization of $\beta$-divergences along with a penalty term that promotes the columns of the dictionary matrix to have a small volume. Under some mild assumptions and in noiseless conditions, we prove that this model is provably able to identify the sources. In order to solve this problem, we propose multiplicative updates whose derivations are based on the standard majorization-minimization framework. We show on several numerical experiments that our new model is able to obtain more interpretable results than standard NMF models. Moreover, we show that it is able to recover the sources even when the number of sources present into the mixed signal is overestimated. In fact, our model automatically sets sources to zero in this situation, hence performs model order selection automatically.
Distributionally Robust and Multi-Objective Nonnegative Matrix Factorization
Jan 31, 2019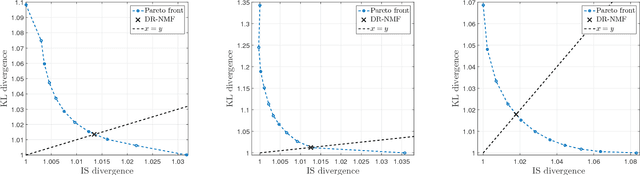
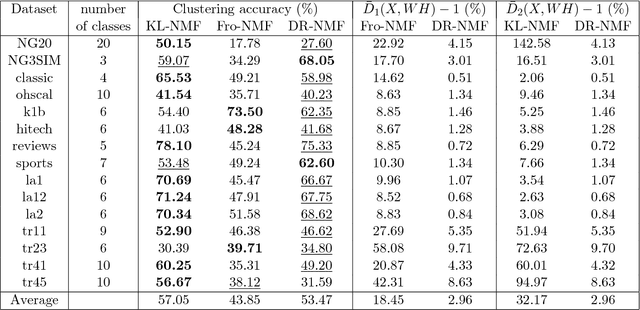
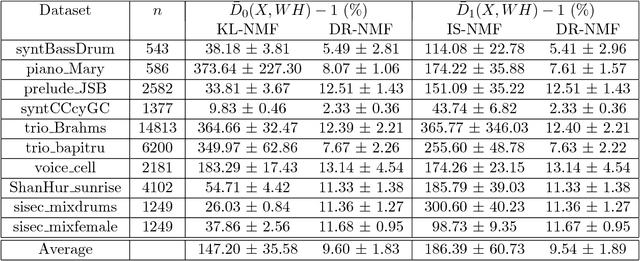
Nonnegative matrix factorization (NMF) is a linear dimensionality reduction technique for analyzing nonnegative data. A key aspect of NMF is the choice of the objective function that depends on the noise model (or statistics of the noise) assumed on the data. In many applications, the noise model is unknown and difficult to estimate. In this paper, we define a multi-objective NMF (MO-NMF) problem, where several objectives are combined within the same NMF model. We propose to use Lagrange duality to judiciously optimize for a set of weights to be used within the framework of the weighted-sum approach, that is, we minimize a single objective function which is a weighted sum of the all objective functions. We design a simple algorithm using multiplicative updates to minimize this weighted sum. We show how this can be used to find distributionally robust NMF (DR-NMF) solutions, that is, solutions that minimize the largest error among all objectives. We illustrate the effectiveness of this approach on synthetic, document and audio datasets. The results show that DR-NMF is robust to our incognizance of the noise model of the NMF problem.