 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold-based Algorithms for the Hadamard Decomposition
May 27, 2026Given a matrix $X$, and two ranks $r_1$ and $r_2$, the Hadamard decomposition (HD) looks for two low-rank matrices, $X_1$ of rank $r_1$ and $X_2$ of rank $r_2$, both of the same size as $X$, such that $X\approx X_1\circ X_2$, where $\circ$ is the Hadamard (element-wise) product. In most cases, HD is more expressive than standard low-rank approximations such as the truncated singular value decomposition (TSVD), as it can represent higher-rank matrices with the same number of parameters; this is because the rank of $X_1 \circ X_2$ is generically equal to $r_1 r_2$. In this paper, we first present some theoretical insights for HD, in particular a useful reformulation $X\approx WH^\top$ where $W$ and $H$ have $r_1 r_2$ columns and belong to certain manifolds. These allow us to develop three new algorithms for computing HD. The first one uses the representation $X\approx X_1\circ X_2$ and relies on the Manopt toolbox. The other two rely on the reformulation $X\approx WH^\top$: one is a block projected gradient method, and the other is a manifold-based gradient descent algorithm that does not require projection onto the feasible set. The last two algorithms are particularly effective for handling large sparse data. We also propose new initializations that allow us to improve the accuracy of the HD. We compare our algorithms and initialization strategies with the TSVD and with the state of the art. Numerical results show that the new methods are efficient and competitive on both synthetic and real data.
Supervised Deep Multimodal Matrix Factorization for Interpretable Brain Network Analysis
May 13, 2026We present Supervised Deep Multimodal Matrix Factorization (SD3MF), an interpretable framework for integrative brain network analysis that generalizes Symmetric Nonnegative Matrix Tri-Factorization (SNMTF) from unsupervised single-graph clustering to supervised prediction over populations of multimodal graphs. SD3MF learns deep hierarchical factorizations for each modality together with a shared latent representation that aligns subjects across views. An encoder-decoder formulation jointly optimizes graph reconstruction and supervised prediction, while adaptive weights enable data-driven multimodal fusion. By representing each subject through community-level interaction matrices, the model yields interpretable and discriminative features. Experiments on multimodal connectome datasets show that SD3MF consistently outperforms strong deep learning baselines such as CNNs and GNNs, while enabling biologically interpretable insights. Code for reproducibility is available at: https://github.com/amjadseyedi/SD3MF.
Nonnegative Matrix Factorization in the Component-Wise L1 Norm for Sparse Data
Mar 31, 2026Nonnegative matrix factorization (NMF) approximates a nonnegative matrix, $X$, by the product of two nonnegative factors, $WH$, where $W$ has $r$ columns and $H$ has $r$ rows. In this paper, we consider NMF using the component-wise L1 norm as the error measure (L1-NMF), which is suited for data corrupted by heavy-tailed noise, such as Laplace noise or salt and pepper noise, or in the presence of outliers. Our first contribution is an NP-hardness proof for L1-NMF, even when $r=1$, in contrast to the standard NMF that uses least squares. Our second contribution is to show that L1-NMF strongly enforces sparsity in the factors for sparse input matrices, thereby favoring interpretability. However, if the data is affected by false zeros, too sparse solutions might degrade the model. Our third contribution is a new, more general, L1-NMF model for sparse data, dubbed weighted L1-NMF (wL1-NMF), where the sparsity of the factorization is controlled by adding a penalization parameter to the entries of $WH$ associated with zeros in the data. The fourth contribution is a new coordinate descent (CD) approach for wL1-NMF, denoted as sparse CD (sCD), where each subproblem is solved by a weighted median algorithm. To the best of our knowledge, sCD is the first algorithm for L1-NMF whose complexity scales with the number of nonzero entries in the data, making it efficient in handling large-scale, sparse data. We perform extensive numerical experiments on synthetic and real-world data to show the effectiveness of our new proposed model (wL1-NMF) and algorithm (sCD).
Maximum-Volume Nonnegative Matrix Factorization
Feb 05, 2026Nonnegative matrix factorization (NMF) is a popular data embedding technique. Given a nonnegative data matrix $X$, it aims at finding two lower dimensional matrices, $W$ and $H$, such that $X\approx WH$, where the factors $W$ and $H$ are constrained to be element-wise nonnegative. The factor $W$ serves as a basis for the columns of $X$. In order to obtain more interpretable and unique solutions, minimum-volume NMF (MinVol NMF) minimizes the volume of $W$. In this paper, we consider the dual approach, where the volume of $H$ is maximized instead; this is referred to as maximum-volume NMF (MaxVol NMF). MaxVol NMF is identifiable under the same conditions as MinVol NMF in the noiseless case, but it behaves rather differently in the presence of noise. In practice, MaxVol NMF is much more effective to extract a sparse decomposition and does not generate rank-deficient solutions. In fact, we prove that the solutions of MaxVol NMF with the largest volume correspond to clustering the columns of $X$ in disjoint clusters, while the solutions of MinVol NMF with smallest volume are rank deficient. We propose two algorithms to solve MaxVol NMF. We also present a normalized variant of MaxVol NMF that exhibits better performance than MinVol NMF and MaxVol NMF, and can be interpreted as a continuum between standard NMF and orthogonal NMF. We illustrate our results in the context of hyperspectral unmixing.
Matrix Factorization Framework for Community Detection under the Degree-Corrected Block Model
Jan 09, 2026Community detection is a fundamental task in data analysis. Block models form a standard approach to partition nodes according to a graph model, facilitating the analysis and interpretation of the network structure. By grouping nodes with similar connection patterns, they enable the identification of a wide variety of underlying structures. The degree-corrected block model (DCBM) is an established model that accounts for the heterogeneity of node degrees. However, existing inference methods for the DCBM are heuristics that are highly sensitive to initialization, typically done randomly. In this work, we show that DCBM inference can be reformulated as a constrained nonnegative matrix factorization problem. Leveraging this insight, we propose a novel method for community detection and a theoretically well-grounded initialization strategy that provides an initial estimate of communities for inference algorithms. Our approach is agnostic to any specific network structure and applies to graphs with any structure representable by a DCBM, not only assortative ones. Experiments on synthetic and real benchmark networks show that our method detects communities comparable to those found by DCBM inference, while scaling linearly with the number of edges and communities; for instance, it processes a graph with 100,000 nodes and 2,000,000 edges in approximately 4 minutes. Moreover, the proposed initialization strategy significantly improves solution quality and reduces the number of iterations required by all tested inference algorithms. Overall, this work provides a scalable and robust framework for community detection and highlights the benefits of a matrix-factorization perspective for the DCBM.
A Provably-Correct and Robust Convex Model for Smooth Separable NMF
Nov 10, 2025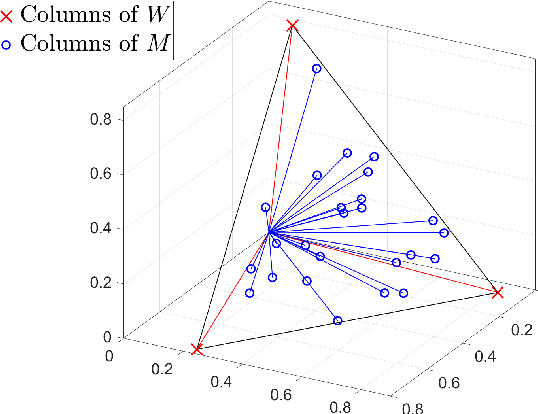
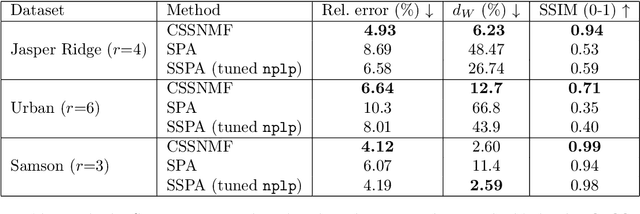
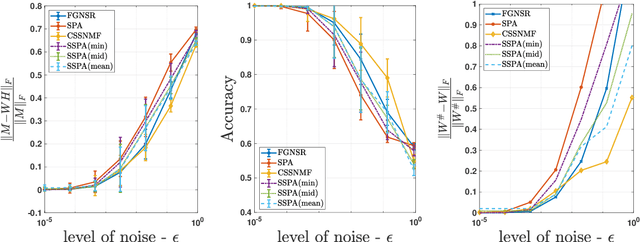
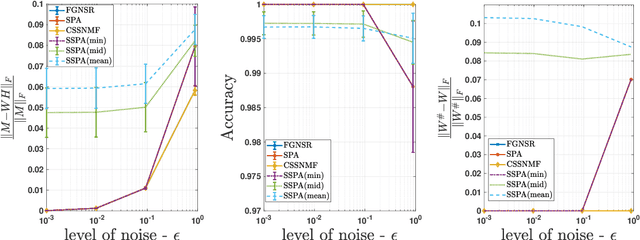
Nonnegative matrix factorization (NMF) is a linear dimensionality reduction technique for nonnegative data, with applications such as hyperspectral unmixing and topic modeling. NMF is a difficult problem in general (NP-hard), and its solutions are typically not unique. To address these two issues, additional constraints or assumptions are often used. In particular, separability assumes that the basis vectors in the NMF are equal to some columns of the input matrix. In that case, the problem is referred to as separable NMF (SNMF) and can be solved in polynomial-time with robustness guarantees, while identifying a unique solution. However, in real-world scenarios, due to noise or variability, multiple data points may lie near the basis vectors, which SNMF does not leverage. In this work, we rely on the smooth separability assumption, which assumes that each basis vector is close to multiple data points. We explore the properties of the corresponding problem, referred to as smooth SNMF (SSNMF), and examine how it relates to SNMF and orthogonal NMF. We then propose a convex model for SSNMF and show that it provably recovers the sought-after factors, even in the presence of noise. We finally adapt an existing fast gradient method to solve this convex model for SSNMF, and show that it compares favorably with state-of-the-art methods on both synthetic and hyperspectral datasets.
Robustness of Minimum-Volume Nonnegative Matrix Factorization under an Expanded Sufficiently Scattered Condition
Nov 06, 2025Minimum-volume nonnegative matrix factorization (min-vol NMF) has been used successfully in many applications, such as hyperspectral imaging, chemical kinetics, spectroscopy, topic modeling, and audio source separation. However, its robustness to noise has been a long-standing open problem. In this paper, we prove that min-vol NMF identifies the groundtruth factors in the presence of noise under a condition referred to as the expanded sufficiently scattered condition which requires the data points to be sufficiently well scattered in the latent simplex generated by the basis vectors.
Identifiability of Nonnegative Tucker Decompositions -- Part I: Theory
May 19, 2025


Tensor decompositions have become a central tool in data science, with applications in areas such as data analysis, signal processing, and machine learning. A key property of many tensor decompositions, such as the canonical polyadic decomposition, is identifiability: the factors are unique, up to trivial scaling and permutation ambiguities. This allows one to recover the groundtruth sources that generated the data. The Tucker decomposition (TD) is a central and widely used tensor decomposition model. However, it is in general not identifiable. In this paper, we study the identifiability of the nonnegative TD (nTD). By adapting and extending identifiability results of nonnegative matrix factorization (NMF), we provide uniqueness results for nTD. Our results require the nonnegative matrix factors to have some degree of sparsity (namely, satisfy the separability condition, or the sufficiently scattered condition), while the core tensor only needs to have some slices (or linear combinations of them) or unfoldings with full column rank (but does not need to be nonnegative). Under such conditions, we derive several procedures, using either unfoldings or slices of the input tensor, to obtain identifiable nTDs by minimizing the volume of unfoldings or slices of the core tensor.
Efficient algorithms for the Hadamard decomposition
Apr 22, 2025



The Hadamard decomposition is a powerful technique for data analysis and matrix compression, which decomposes a given matrix into the element-wise product of two or more low-rank matrices. In this paper, we develop an efficient algorithm to solve this problem, leveraging an alternating optimization approach that decomposes the global non-convex problem into a series of convex sub-problems. To improve performance, we explore advanced initialization strategies inspired by the singular value decomposition (SVD) and incorporate acceleration techniques by introducing momentum-based updates. Beyond optimizing the two-matrix case, we also extend the Hadamard decomposition framework to support more than two low-rank matrices, enabling approximations with higher effective ranks while preserving computational efficiency. Finally, we conduct extensive experiments to compare our method with the existing gradient descent-based approaches for the Hadamard decomposition and with traditional low-rank approximation techniques. The results highlight the effectiveness of our proposed method across diverse datasets.
An extrapolated and provably convergent algorithm for nonlinear matrix decomposition with the ReLU function
Mar 31, 2025
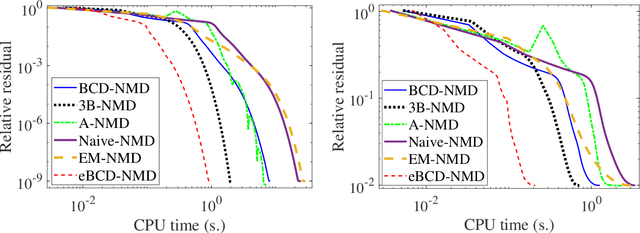


Nonlinear matrix decomposition (NMD) with the ReLU function, denoted ReLU-NMD, is the following problem: given a sparse, nonnegative matrix $X$ and a factorization rank $r$, identify a rank-$r$ matrix $\Theta$ such that $X\approx \max(0,\Theta)$. This decomposition finds application in data compression, matrix completion with entries missing not at random, and manifold learning. The standard ReLU-NMD model minimizes the least squares error, that is, $\|X - \max(0,\Theta)\|_F^2$. The corresponding optimization problem is nondifferentiable and highly nonconvex. This motivated Saul to propose an alternative model, Latent-ReLU-NMD, where a latent variable $Z$ is introduced and satisfies $\max(0,Z)=X$ while minimizing $\|Z - \Theta\|_F^2$ (``A nonlinear matrix decomposition for mining the zeros of sparse data'', SIAM J. Math. Data Sci., 2022). Our first contribution is to show that the two formulations may yield different low-rank solutions $\Theta$; in particular, we show that Latent-ReLU-NMD can be ill-posed when ReLU-NMD is not, meaning that there are instances in which the infimum of Latent-ReLU-NMD is not attained while that of ReLU-NMD is. We also consider another alternative model, called 3B-ReLU-NMD, which parameterizes $\Theta=WH$, where $W$ has $r$ columns and $H$ has $r$ rows, allowing one to get rid of the rank constraint in Latent-ReLU-NMD. Our second contribution is to prove the convergence of a block coordinate descent (BCD) applied to 3B-ReLU-NMD and referred to as BCD-NMD. Our third contribution is a novel extrapolated variant of BCD-NMD, dubbed eBCD-NMD, which we prove is also convergent under mild assumptions. We illustrate the significant acceleration effect of eBCD-NMD compared to BCD-NMD, and also show that eBCD-NMD performs well against the state of the art on synthetic and real-world data sets.