 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models as Interfaces, Not Oracles: A Hybrid LLM-ML System for Pediatric Appendicitis
Jun 17, 2026Large language models (LLMs) can make clinical decision support more accessible by interpreting free-text documentation, but their direct use as diagnostic engines is limited by sensitivity to prompts, information order, and plausible but incorrect outputs. Structured machine-learning models offer more stable risk prediction, yet they require tabular inputs that are difficult to integrate with narrative clinical workflows. We present ClaMPAPP (Clinical Language-assisted Machine-learning Pipeline for Appendicitis), a hybrid system that uses an LLM as an interface rather than as the final decision-maker. ClaMPAPP extracts schema-constrained clinical features from note-like narratives, applies deterministic plausibility checks, and passes validated features to an XGBoost classifier trained on clinical, laboratory, and ultrasound variables. We evaluated ClaMPAPP on two independent pediatric appendicitis cohorts from German hospitals and compared it with end-to-end LLM baselines, including open-source and proprietary models. To preserve ground truth while testing free-text input, narratives were generated from structured electronic health records through template rendering and constrained LLM rewriting, with additional sentence-order permutation to assess positional robustness. ClaMPAPP achieved the strongest overall diagnostic performance in both internal and external validation while minimizing missed appendicitis cases, the key safety concern in acute triage. End-to-end LLMs showed unstable sensitivity-specificity trade-offs and greater degradation under narrative reordering. These results support an LLM-as-interface, ML-as-predictor design that separates natural-language usability from predictive inference and provides a more auditable pathway for clinical decision support.
Trust, Don't Trust, or Flip: Robust Preference-Based Reinforcement Learning with Multi-Expert Feedback
Jan 26, 2026Preference-based reinforcement learning (PBRL) offers a promising alternative to explicit reward engineering by learning from pairwise trajectory comparisons. However, real-world preference data often comes from heterogeneous annotators with varying reliability; some accurate, some noisy, and some systematically adversarial. Existing PBRL methods either treat all feedback equally or attempt to filter out unreliable sources, but both approaches fail when faced with adversarial annotators who systematically provide incorrect preferences. We introduce TriTrust-PBRL (TTP), a unified framework that jointly learns a shared reward model and expert-specific trust parameters from multi-expert preference feedback. The key insight is that trust parameters naturally evolve during gradient-based optimization to be positive (trust), near zero (ignore), or negative (flip), enabling the model to automatically invert adversarial preferences and recover useful signal rather than merely discarding corrupted feedback. We provide theoretical analysis establishing identifiability guarantees and detailed gradient analysis that explains how expert separation emerges naturally during training without explicit supervision. Empirically, we evaluate TTP on four diverse domains spanning manipulation tasks (MetaWorld) and locomotion (DM Control) under various corruption scenarios. TTP achieves state-of-the-art robustness, maintaining near-oracle performance under adversarial corruption while standard PBRL methods fail catastrophically. Notably, TTP outperforms existing baselines by successfully learning from mixed expert pools containing both reliable and adversarial annotators, all while requiring no expert features beyond identification indices and integrating seamlessly with existing PBRL pipelines.
Dual Simplex Volume Maximization for Simplex-Structured Matrix Factorization
Mar 29, 2024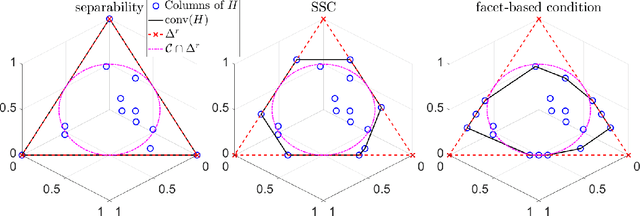
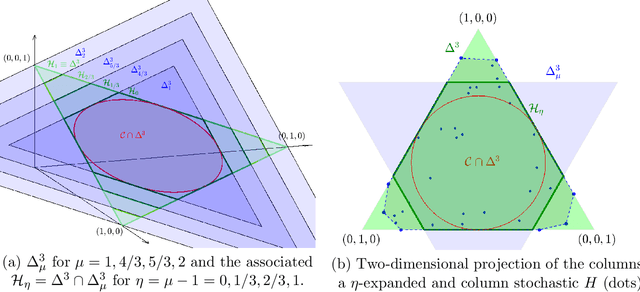
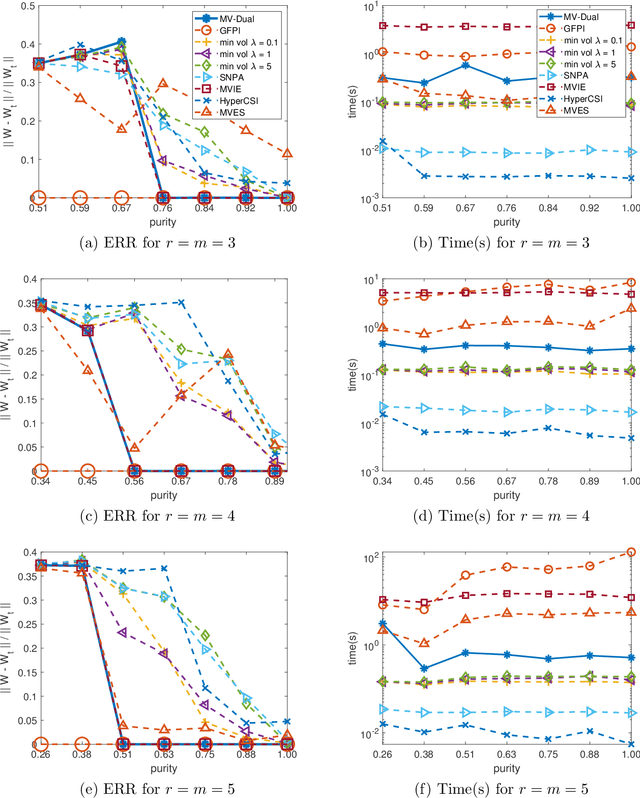
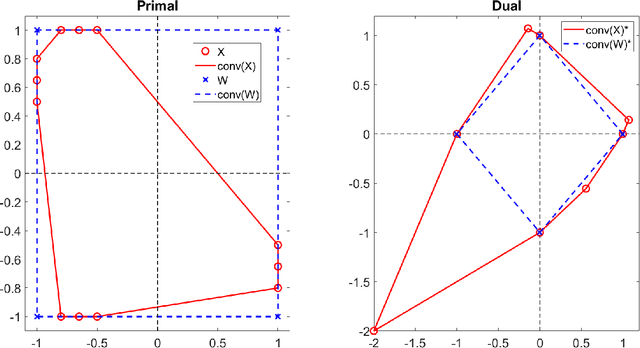
Simplex-structured matrix factorization (SSMF) is a generalization of nonnegative matrix factorization, a fundamental interpretable data analysis model, and has applications in hyperspectral unmixing and topic modeling. To obtain identifiable solutions, a standard approach is to find minimum-volume solutions. By taking advantage of the duality/polarity concept for polytopes, we convert minimum-volume SSMF in the primal space to a maximum-volume problem in the dual space. We first prove the identifiability of this maximum-volume dual problem. Then, we use this dual formulation to provide a novel optimization approach which bridges the gap between two existing families of algorithms for SSMF, namely volume minimization and facet identification. Numerical experiments show that the proposed approach performs favorably compared to the state-of-the-art SSMF algorithms.
Revisiting data augmentation for subspace clustering
Jul 20, 2022
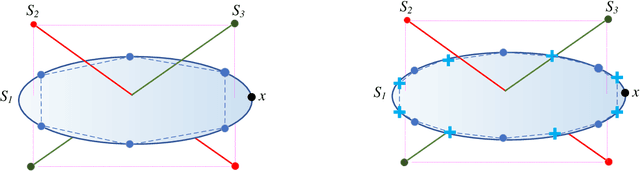
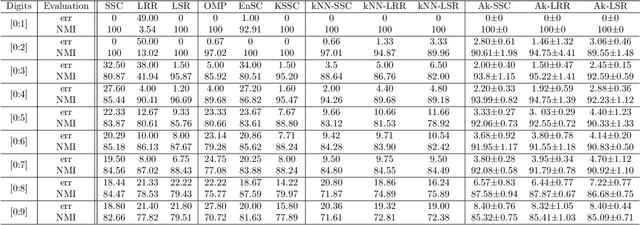
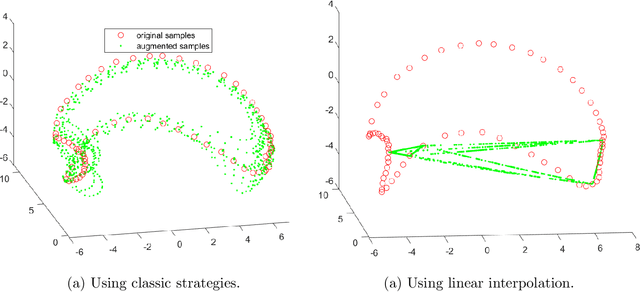
Subspace clustering is the classical problem of clustering a collection of data samples that approximately lie around several low-dimensional subspaces. The current state-of-the-art approaches for this problem are based on the self-expressive model which represents the samples as linear combination of other samples. However, these approaches require sufficiently well-spread samples for accurate representation which might not be necessarily accessible in many applications. In this paper, we shed light on this commonly neglected issue and argue that data distribution within each subspace plays a critical role in the success of self-expressive models. Our proposed solution to tackle this issue is motivated by the central role of data augmentation in the generalization power of deep neural networks. We propose two subspace clustering frameworks for both unsupervised and semi-supervised settings that use augmented samples as an enlarged dictionary to improve the quality of the self-expressive representation. We present an automatic augmentation strategy using a few labeled samples for the semi-supervised problem relying on the fact that the data samples lie in the union of multiple linear subspaces. Experimental results confirm the effectiveness of data augmentation, as it significantly improves the performance of general self-expressive models.
Beyond Linear Subspace Clustering: A Comparative Study of Nonlinear Manifold Clustering Algorithms
Mar 19, 2021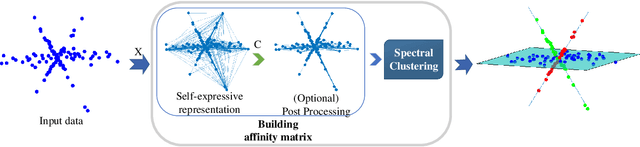
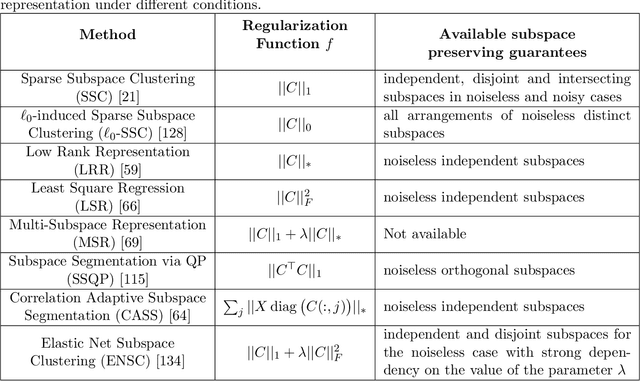
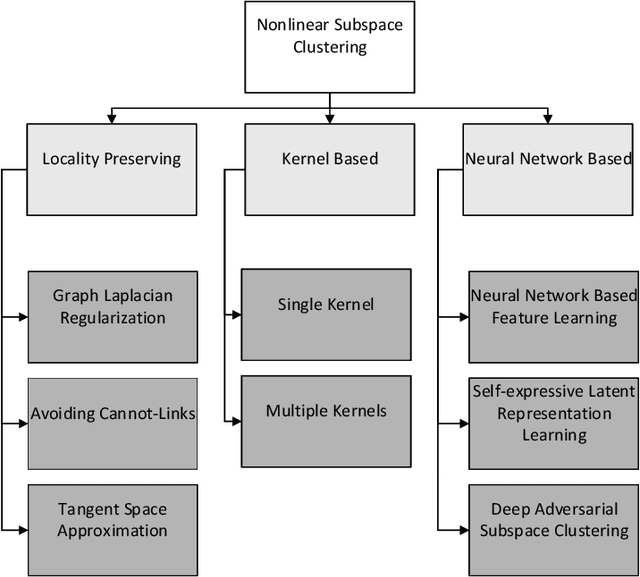
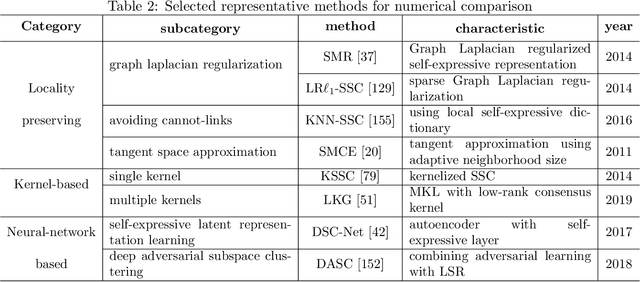
Subspace clustering is an important unsupervised clustering approach. It is based on the assumption that the high-dimensional data points are approximately distributed around several low-dimensional linear subspaces. The majority of the prominent subspace clustering algorithms rely on the representation of the data points as linear combinations of other data points, which is known as a self-expressive representation. To overcome the restrictive linearity assumption, numerous nonlinear approaches were proposed to extend successful subspace clustering approaches to data on a union of nonlinear manifolds. In this comparative study, we provide a comprehensive overview of nonlinear subspace clustering approaches proposed in the last decade. We introduce a new taxonomy to classify the state-of-the-art approaches into three categories, namely locality preserving, kernel based, and neural network based. The major representative algorithms within each category are extensively compared on carefully designed synthetic and real-world data sets. The detailed analysis of these approaches unfolds potential research directions and unsolved challenges in this field.
Simplex-Structured Matrix Factorization: Sparsity-based Identifiability and Provably Correct Algorithms
Jul 22, 2020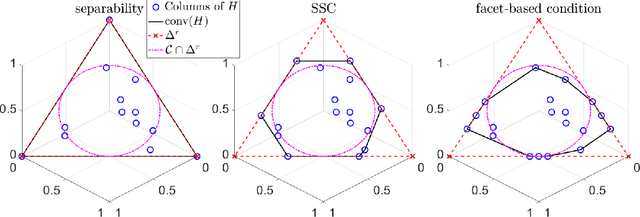
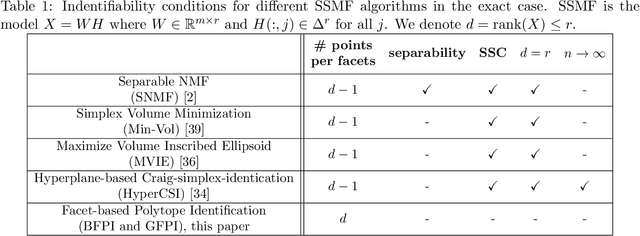
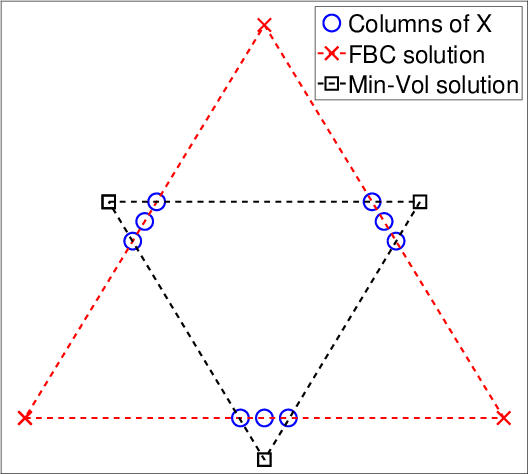
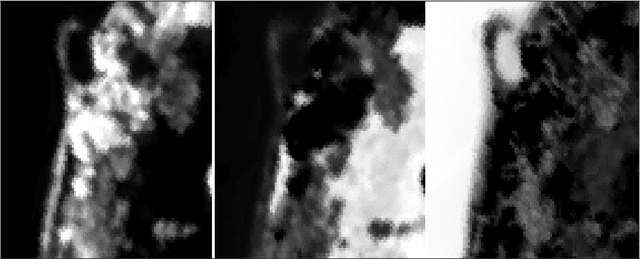
In this paper, we provide novel algorithms with identifiability guarantees for simplex-structured matrix factorization (SSMF), a generalization of nonnegative matrix factorization. Current state-of-the-art algorithms that provide identifiability results for SSMF rely on the sufficiently scattered condition (SSC) which requires the data points to be well spread within the convex hull of the basis vectors. The conditions under which our proposed algorithms recover the unique decomposition is in most cases much weaker than the SSC. We only require to have $d$ points on each facet of the convex hull of the basis vectors whose dimension is $d-1$. The key idea is based on extracting facets containing the largest number of points. We illustrate the effectiveness of our approach on synthetic data sets and hyperspectral images, showing that it outperforms state-of-the-art SSMF algorithms as it is able to handle higher noise levels, rank deficient matrices, outliers, and input data that highly violates the SSC.
Neither Global Nor Local: A Hierarchical Robust Subspace Clustering For Image Data
May 17, 2019
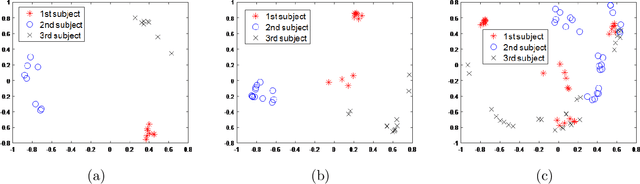
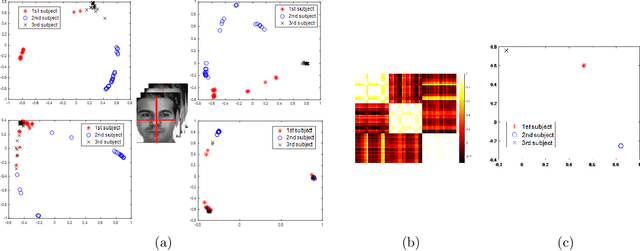
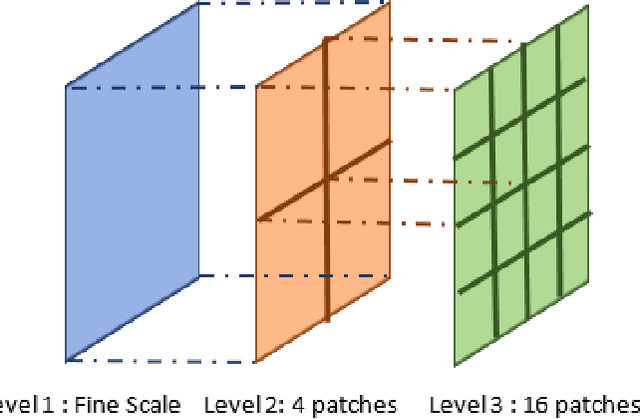
In this paper, we consider the problem of subspace clustering in presence of contiguous noise, occlusion and disguise. We argue that self-expressive representation of data in current state-of-the-art approaches is severely sensitive to occlusions and complex real-world noises. To alleviate this problem, we propose a hierarchical framework that brings robustness of local patches-based representations and discriminant property of global representations together. This approach consists of 1) a top-down stage, in which the input data is subject to repeated division to smaller patches and 2) a bottom-up stage, in which the low rank embedding of local patches in field of view of a corresponding patch in upper level are merged on a Grassmann manifold. This summarized information provides two key information for the corresponding patch on the upper level: cannot-links and recommended-links. This information is employed for computing a self-expressive representation of each patch at upper levels using a weighted sparse group lasso optimization problem. Numerical results on several real data sets confirm the efficiency of our approach.
Scalable and Robust Sparse Subspace Clustering Using Randomized Clustering and Multilayer Graphs
Feb 23, 2018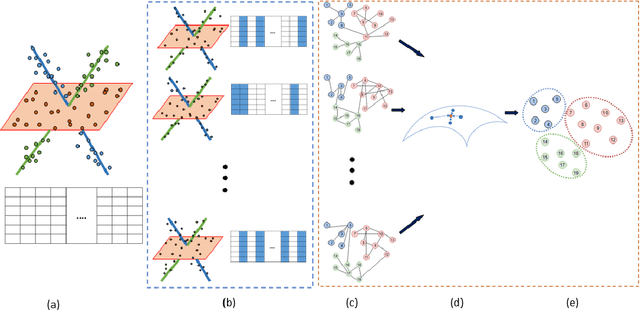
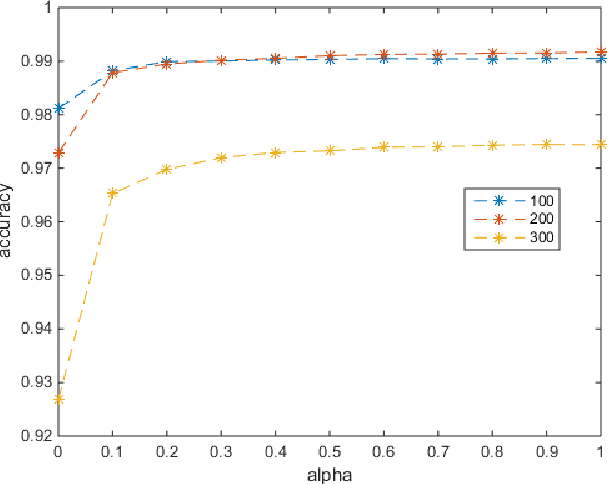
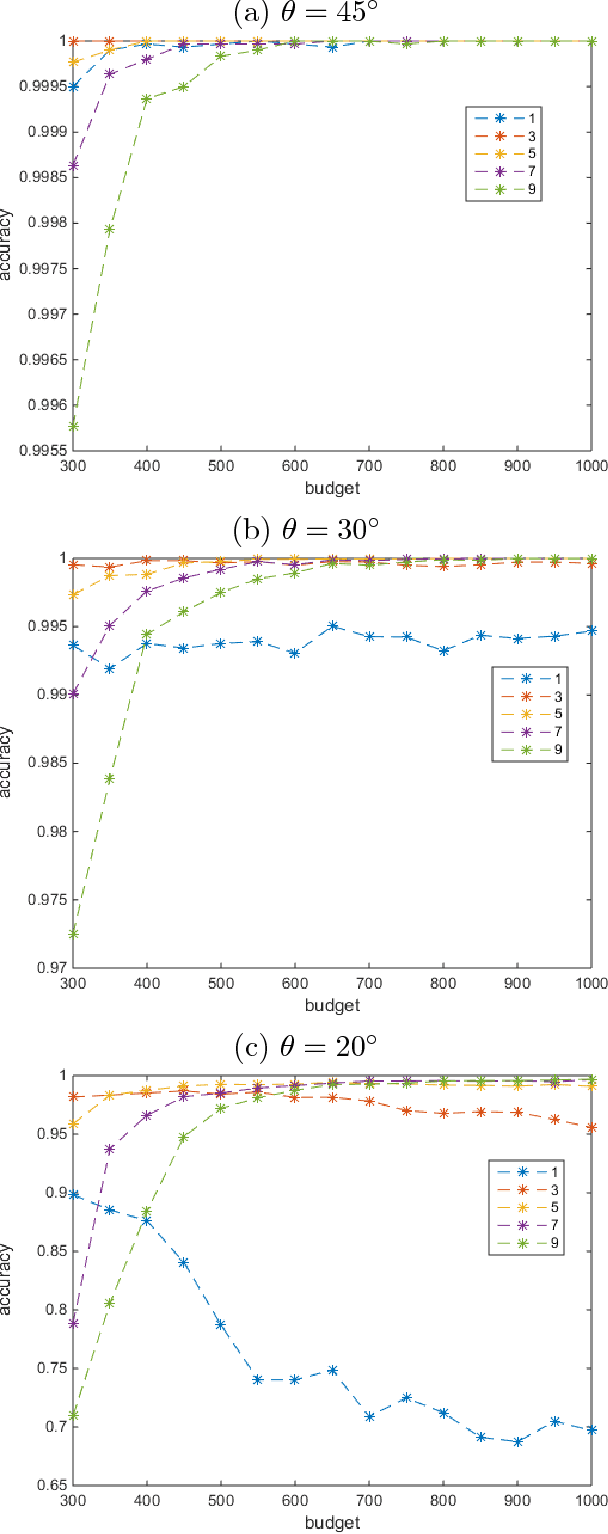
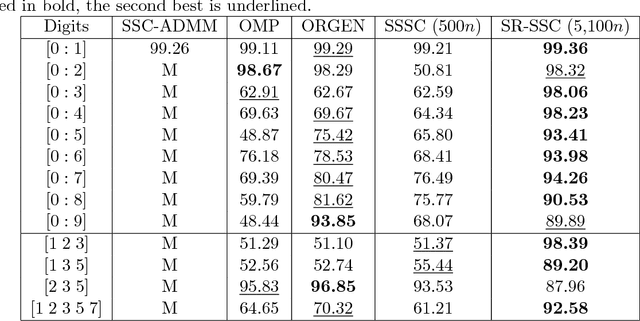
Sparse subspace clustering (SSC) is one of the current state-of-the-art methods for partitioning data points into the union of subspaces, with strong theoretical guarantees. However, it is not practical for large data sets as it requires solving a LASSO problem for each data point, where the number of variables in each LASSO problem is the number of data points. To improve the scalability of SSC, we propose to select a few sets of anchor points using a randomized hierarchical clustering method, and, for each set of anchor points, solve the LASSO problems for each data point allowing only anchor points to have a non-zero weight (this reduces drastically the number of variables). This generates a multilayer graph where each layer corresponds to a different set of anchor points. Using the Grassmann manifold of orthogonal matrices, the shared connectivity among the layers is summarized within a single subspace. Finally, we use $k$-means clustering within that subspace to cluster the data points, similarly as done by spectral clustering in SSC. We show on both synthetic and real-world data sets that the proposed method not only allows SSC to scale to large-scale data sets, but that it is also much more robust as it performs significantly better on noisy data and on data with close susbspaces and outliers, while it is not prone to oversegmentation.