 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting data augmentation for subspace clustering
Paper and Code
Jul 20, 2022
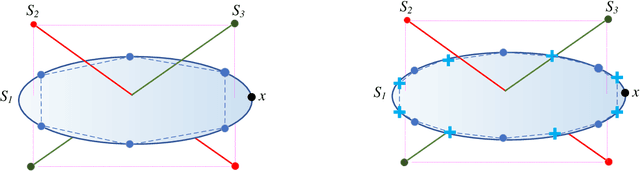
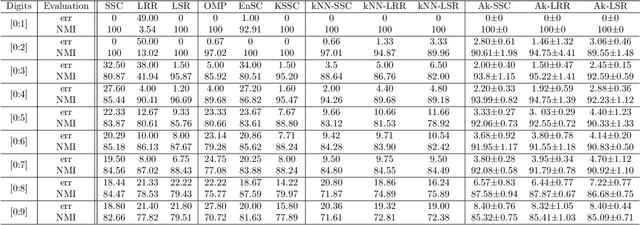
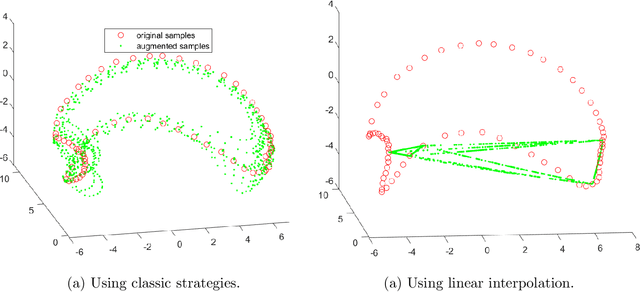
Subspace clustering is the classical problem of clustering a collection of data samples that approximately lie around several low-dimensional subspaces. The current state-of-the-art approaches for this problem are based on the self-expressive model which represents the samples as linear combination of other samples. However, these approaches require sufficiently well-spread samples for accurate representation which might not be necessarily accessible in many applications. In this paper, we shed light on this commonly neglected issue and argue that data distribution within each subspace plays a critical role in the success of self-expressive models. Our proposed solution to tackle this issue is motivated by the central role of data augmentation in the generalization power of deep neural networks. We propose two subspace clustering frameworks for both unsupervised and semi-supervised settings that use augmented samples as an enlarged dictionary to improve the quality of the self-expressive representation. We present an automatic augmentation strategy using a few labeled samples for the semi-supervised problem relying on the fact that the data samples lie in the union of multiple linear subspaces. Experimental results confirm the effectiveness of data augmentation, as it significantly improves the performance of general self-expressive models.