 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Spatial Structure of Mixture-of-Experts in Transformers
Apr 06, 2025A common assumption is that MoE routers primarily leverage semantic features for expert selection. However, our study challenges this notion by demonstrating that positional token information also plays a crucial role in routing decisions. Through extensive empirical analysis, we provide evidence supporting this hypothesis, develop a phenomenological explanation of the observed behavior, and discuss practical implications for MoE-based architectures.
LoTR: Low Tensor Rank Weight Adaptation
Feb 05, 2024In this paper we generalize and extend an idea of low-rank adaptation (LoRA) of large language models (LLMs) based on Transformer architecture. Widely used LoRA-like methods of fine-tuning LLMs are based on matrix factorization of gradient update. We introduce LoTR, a novel approach for parameter-efficient fine-tuning of LLMs which represents a gradient update to parameters in a form of tensor decomposition. Low-rank adapter for each layer is constructed as a product of three matrices, and tensor structure arises from sharing left and right multipliers of this product among layers. Simultaneous compression of a sequence of layers with low-rank tensor representation allows LoTR to archive even better parameter efficiency then LoRA especially for deep models. Moreover, the core tensor does not depend on original weight dimension and can be made arbitrary small, which allows for extremely cheap and fast downstream fine-tuning.
NAG-GS: Semi-Implicit, Accelerated and Robust Stochastic Optimizers
Sep 29, 2022
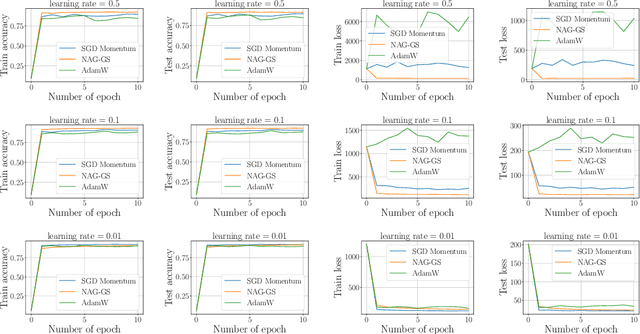
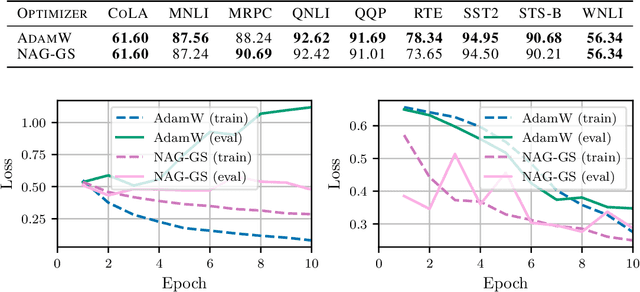
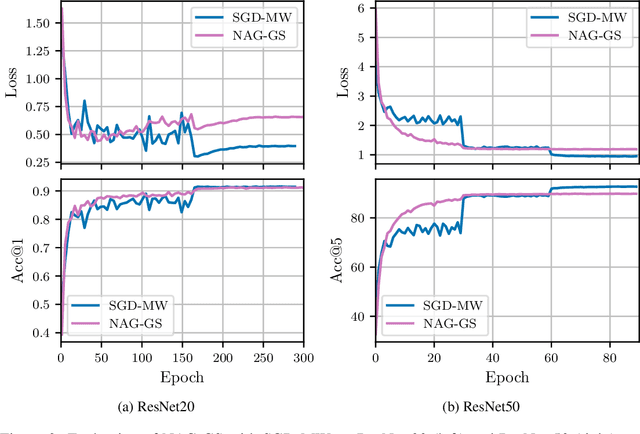
Classical machine learning models such as deep neural networks are usually trained by using Stochastic Gradient Descent-based (SGD) algorithms. The classical SGD can be interpreted as a discretization of the stochastic gradient flow. In this paper we propose a novel, robust and accelerated stochastic optimizer that relies on two key elements: (1) an accelerated Nesterov-like Stochastic Differential Equation (SDE) and (2) its semi-implicit Gauss-Seidel type discretization. The convergence and stability of the obtained method, referred to as NAG-GS, are first studied extensively in the case of the minimization of a quadratic function. This analysis allows us to come up with an optimal step size (or learning rate) in terms of rate of convergence while ensuring the stability of NAG-GS. This is achieved by the careful analysis of the spectral radius of the iteration matrix and the covariance matrix at stationarity with respect to all hyperparameters of our method. We show that NAG-GS is competitive with state-of-the-art methods such as momentum SGD with weight decay and AdamW for the training of machine learning models such as the logistic regression model, the residual networks models on standard computer vision datasets, and Transformers in the frame of the GLUE benchmark.
Survey on Large Scale Neural Network Training
Feb 21, 2022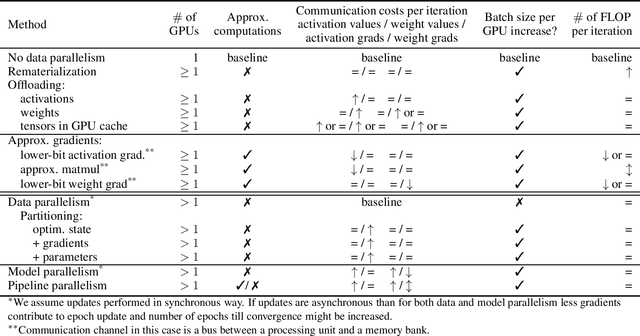
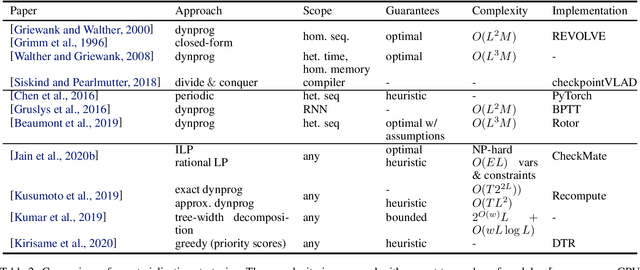
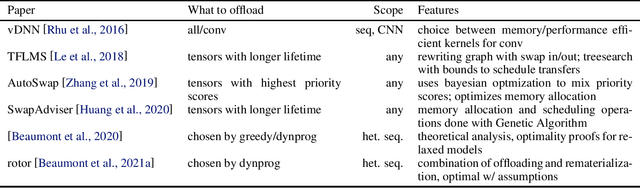
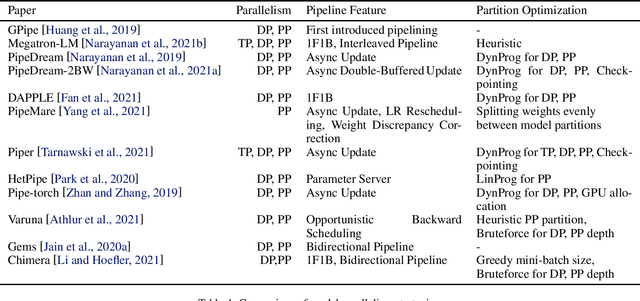
Modern Deep Neural Networks (DNNs) require significant memory to store weight, activations, and other intermediate tensors during training. Hence, many models do not fit one GPU device or can be trained using only a small per-GPU batch size. This survey provides a systematic overview of the approaches that enable more efficient DNNs training. We analyze techniques that save memory and make good use of computation and communication resources on architectures with a single or several GPUs. We summarize the main categories of strategies and compare strategies within and across categories. Along with approaches proposed in the literature, we discuss available implementations.
Memory-Efficient Backpropagation through Large Linear Layers
Feb 02, 2022

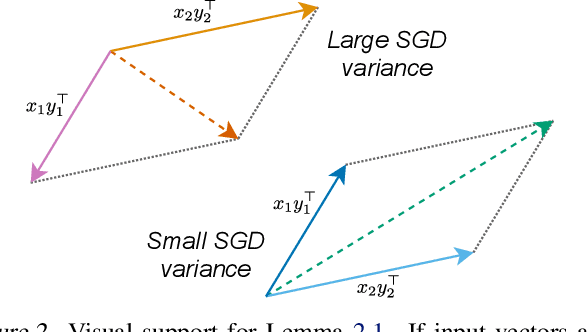

In modern neural networks like Transformers, linear layers require significant memory to store activations during backward pass. This study proposes a memory reduction approach to perform backpropagation through linear layers. Since the gradients of linear layers are computed by matrix multiplications, we consider methods for randomized matrix multiplications and demonstrate that they require less memory with a moderate decrease of the test accuracy. Also, we investigate the variance of the gradient estimate induced by the randomized matrix multiplication. We compare this variance with the variance coming from gradient estimation based on the batch of samples. We demonstrate the benefits of the proposed method on the fine-tuning of the pre-trained RoBERTa model on GLUE tasks.
Few-Bit Backward: Quantized Gradients of Activation Functions for Memory Footprint Reduction
Feb 02, 2022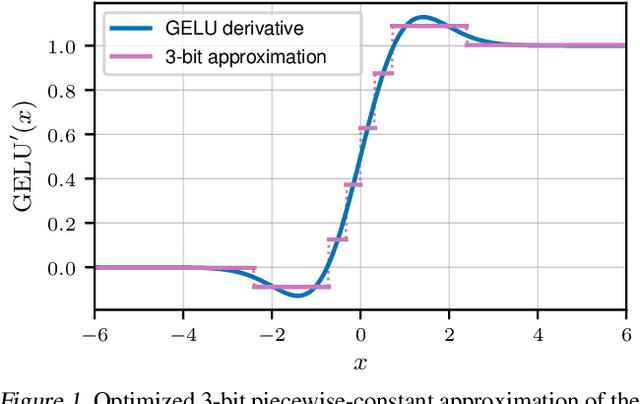

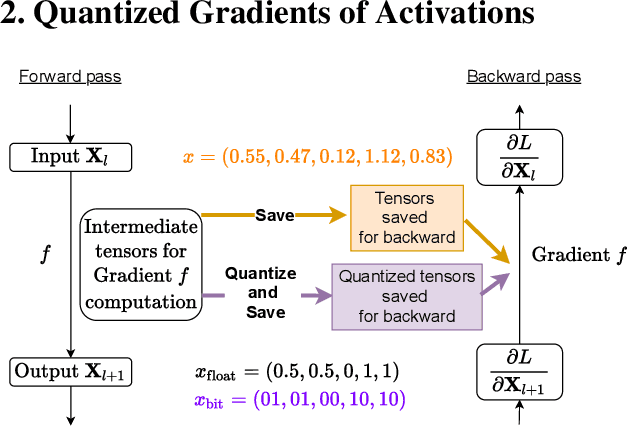

Memory footprint is one of the main limiting factors for large neural network training. In backpropagation, one needs to store the input to each operation in the computational graph. Every modern neural network model has quite a few pointwise nonlinearities in its architecture, and such operation induces additional memory costs which -- as we show -- can be significantly reduced by quantization of the gradients. We propose a systematic approach to compute optimal quantization of the retained gradients of the pointwise nonlinear functions with only a few bits per each element. We show that such approximation can be achieved by computing optimal piecewise-constant approximation of the derivative of the activation function, which can be done by dynamic programming. The drop-in replacements are implemented for all popular nonlinearities and can be used in any existing pipeline. We confirm the memory reduction and the same convergence on several open benchmarks.