 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Tensor-Train Point Cloud Compression and Efficient Approximate Nearest-Neighbor Search
Oct 06, 2024



Nearest-neighbor search in large vector databases is crucial for various machine learning applications. This paper introduces a novel method using tensor-train (TT) low-rank tensor decomposition to efficiently represent point clouds and enable fast approximate nearest-neighbor searches. We propose a probabilistic interpretation and utilize density estimation losses like Sliced Wasserstein to train TT decompositions, resulting in robust point cloud compression. We reveal an inherent hierarchical structure within TT point clouds, facilitating efficient approximate nearest-neighbor searches. In our paper, we provide detailed insights into the methodology and conduct comprehensive comparisons with existing methods. We demonstrate its effectiveness in various scenarios, including out-of-distribution (OOD) detection problems and approximate nearest-neighbor (ANN) search tasks.
Inverted Activations
Jul 22, 2024The scaling of neural networks with increasing data and model sizes necessitates more efficient deep learning algorithms. This paper addresses the memory footprint challenge in neural network training by proposing a modification to the handling of activation tensors in pointwise nonlinearity layers. Traditionally, these layers save the entire input tensor for the backward pass, leading to substantial memory use. Our method involves saving the output tensor instead, reducing the memory required when the subsequent layer also saves its input tensor. This approach is particularly beneficial for transformer-based architectures like GPT, BERT, Mistral, and Llama. Application of our method involves taken an inverse function of nonlinearity. To the best of our knowledge, that can not be done analitically and instead we buid an accurate approximations using simpler functions. Experimental results confirm that our method significantly reduces memory usage without affecting training accuracy. The implementation is available at https://github.com/PgLoLo/optiacts.
Efficient GPT Model Pre-training using Tensor Train Matrix Representation
Jun 05, 2023



Large-scale transformer models have shown remarkable performance in language modelling tasks. However, such models feature billions of parameters, leading to difficulties in their deployment and prohibitive training costs from scratch. To reduce the number of the parameters in the GPT-2 architecture, we replace the matrices of fully-connected layers with the corresponding Tensor Train Matrix~(TTM) structure. Finally, we customize forward and backward operations through the TTM-based layer for simplicity and the stableness of further training. % The resulting GPT-2-based model stores up to 40% fewer parameters, showing the perplexity comparable to the original model. On the downstream tasks, including language understanding and text summarization, the model performs similarly to the original GPT-2 model. The proposed tensorized layers could be used to efficiently pre-training other Transformer models.
Few-Bit Backward: Quantized Gradients of Activation Functions for Memory Footprint Reduction
Feb 02, 2022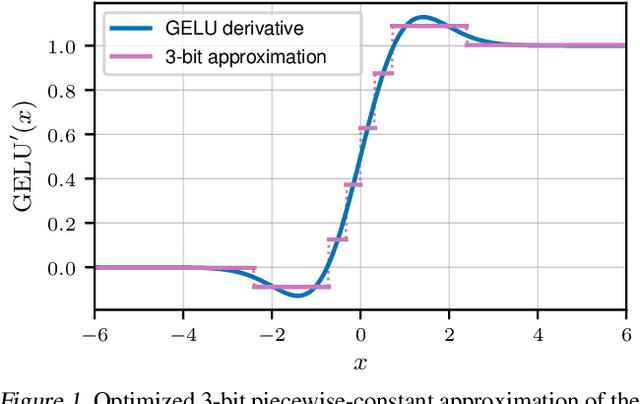

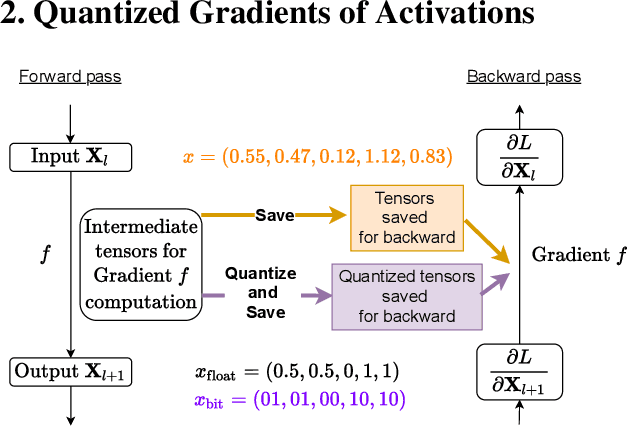

Memory footprint is one of the main limiting factors for large neural network training. In backpropagation, one needs to store the input to each operation in the computational graph. Every modern neural network model has quite a few pointwise nonlinearities in its architecture, and such operation induces additional memory costs which -- as we show -- can be significantly reduced by quantization of the gradients. We propose a systematic approach to compute optimal quantization of the retained gradients of the pointwise nonlinear functions with only a few bits per each element. We show that such approximation can be achieved by computing optimal piecewise-constant approximation of the derivative of the activation function, which can be done by dynamic programming. The drop-in replacements are implemented for all popular nonlinearities and can be used in any existing pipeline. We confirm the memory reduction and the same convergence on several open benchmarks.