 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Fisher-Weighted SVD: Scalable Kronecker-Factored Fisher Approximation for Compressing Large Language Models
May 23, 2025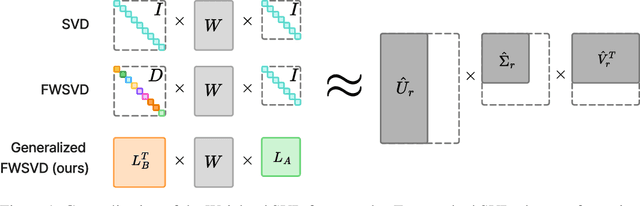
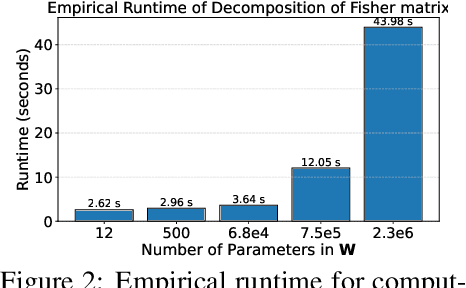

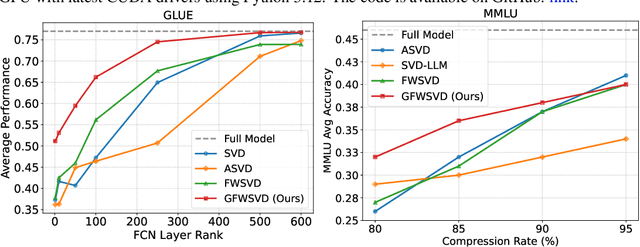
The Fisher information is a fundamental concept for characterizing the sensitivity of parameters in neural networks. However, leveraging the full observed Fisher information is too expensive for large models, so most methods rely on simple diagonal approximations. While efficient, this approach ignores parameter correlations, often resulting in reduced performance on downstream tasks. In this work, we mitigate these limitations and propose Generalized Fisher-Weighted SVD (GFWSVD), a post-training LLM compression technique that accounts for both diagonal and off-diagonal elements of the Fisher information matrix, providing a more accurate reflection of parameter importance. To make the method tractable, we introduce a scalable adaptation of the Kronecker-factored approximation algorithm for the observed Fisher information. We demonstrate the effectiveness of our method on LLM compression, showing improvements over existing compression baselines. For example, at a 20 compression rate on the MMLU benchmark, our method outperforms FWSVD, which is based on a diagonal approximation of the Fisher information, by 5 percent, SVD-LLM by 3 percent, and ASVD by 6 percent compression rate.
Addressing Hallucinations in Language Models with Knowledge Graph Embeddings as an Additional Modality
Nov 18, 2024In this paper we present an approach to reduce hallucinations in Large Language Models (LLMs) by incorporating Knowledge Graphs (KGs) as an additional modality. Our method involves transforming input text into a set of KG embeddings and using an adapter to integrate these embeddings into the language model space, without relying on external retrieval processes. To facilitate this, we created WikiEntities, a dataset containing over 3 million Wikipedia texts annotated with entities from Wikidata and their corresponding embeddings from PyTorch-BigGraph. This dataset serves as a valuable resource for training Entity Linking models and adapting the described method to various LLMs using specialized adapters. Our method does not require fine-tuning of the language models themselves; instead, we only train the adapter. This ensures that the model's performance on other tasks is not affected. We trained an adapter for the Mistral 7B, LLaMA 2-7B (chat), and LLaMA 3-8B (instruct) models using this dataset and demonstrated that our approach improves performance on the HaluEval, True-False benchmarks and FEVER dataset. The results indicate that incorporating KGs as a new modality can effectively reduce hallucinations and improve the factual accuracy of language models, all without the need for external retrieval.
SparseGrad: A Selective Method for Efficient Fine-tuning of MLP Layers
Oct 09, 2024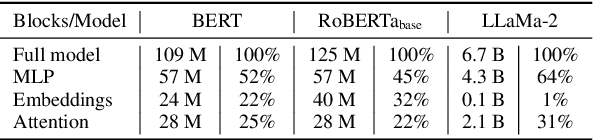
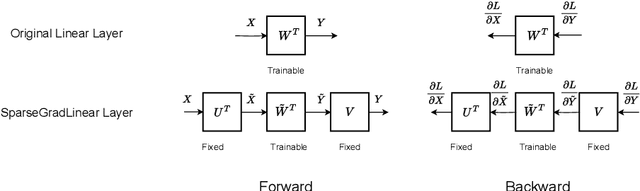
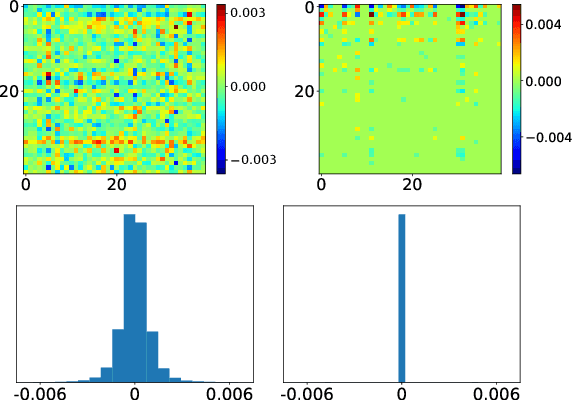
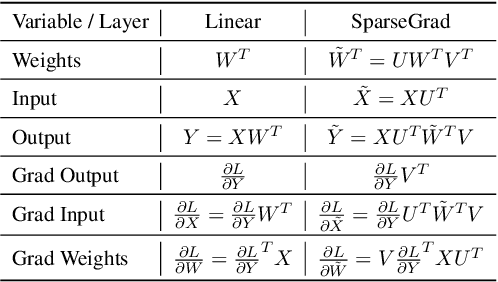
The performance of Transformer models has been enhanced by increasing the number of parameters and the length of the processed text. Consequently, fine-tuning the entire model becomes a memory-intensive process. High-performance methods for parameter-efficient fine-tuning (PEFT) typically work with Attention blocks and often overlook MLP blocks, which contain about half of the model parameters. We propose a new selective PEFT method, namely SparseGrad, that performs well on MLP blocks. We transfer layer gradients to a space where only about 1\% of the layer's elements remain significant. By converting gradients into a sparse structure, we reduce the number of updated parameters. We apply SparseGrad to fine-tune BERT and RoBERTa for the NLU task and LLaMa-2 for the Question-Answering task. In these experiments, with identical memory requirements, our method outperforms LoRA and MeProp, robust popular state-of-the-art PEFT approaches.
Efficient GPT Model Pre-training using Tensor Train Matrix Representation
Jun 05, 2023



Large-scale transformer models have shown remarkable performance in language modelling tasks. However, such models feature billions of parameters, leading to difficulties in their deployment and prohibitive training costs from scratch. To reduce the number of the parameters in the GPT-2 architecture, we replace the matrices of fully-connected layers with the corresponding Tensor Train Matrix~(TTM) structure. Finally, we customize forward and backward operations through the TTM-based layer for simplicity and the stableness of further training. % The resulting GPT-2-based model stores up to 40% fewer parameters, showing the perplexity comparable to the original model. On the downstream tasks, including language understanding and text summarization, the model performs similarly to the original GPT-2 model. The proposed tensorized layers could be used to efficiently pre-training other Transformer models.
Retrieving Comparative Arguments using Ensemble Methods and Neural Information Retrieval
May 01, 2023

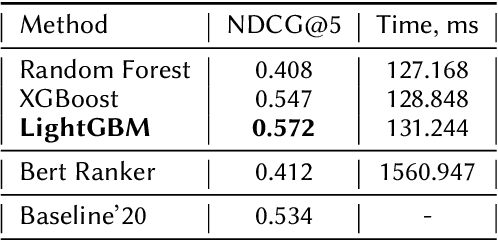
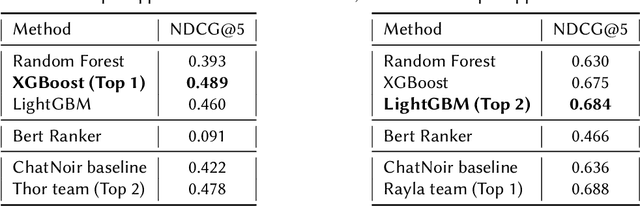
In this paper, we present a submission to the Touche lab's Task 2 on Argument Retrieval for Comparative Questions. Our team Katana supplies several approaches based on decision tree ensembles algorithms to rank comparative documents in accordance with their relevance and argumentative support. We use PyTerrier library to apply ensembles models to a ranking problem, considering statistical text features and features based on comparative structures. We also employ large contextualized language modelling techniques, such as BERT, to solve the proposed ranking task. To merge this technique with ranking modelling, we leverage neural ranking library OpenNIR. Our systems substantially outperforming the proposed baseline and scored first in relevance and second in quality according to the official metrics of the competition (for measure NDCG@5 score). Presented models could help to improve the performance of processing comparative queries in information retrieval and dialogue systems.
MEKER: Memory Efficient Knowledge Embedding Representation for Link Prediction and Question Answering
Apr 22, 2022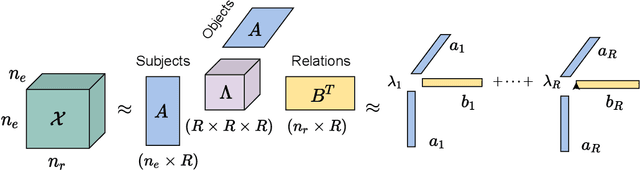
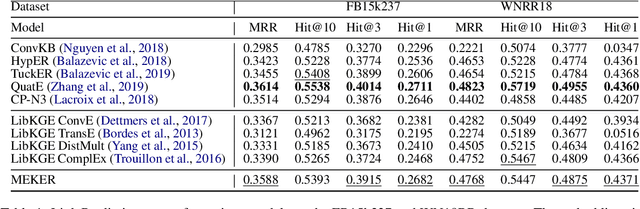
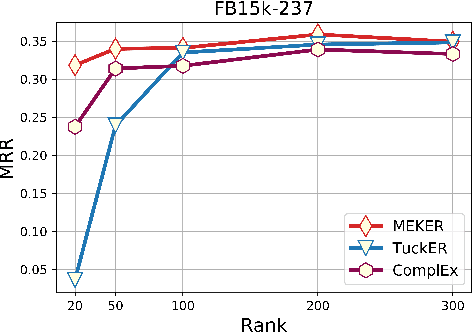
Knowledge Graphs (KGs) are symbolically structured storages of facts. The KG embedding contains concise data used in NLP tasks requiring implicit information about the real world. Furthermore, the size of KGs that may be useful in actual NLP assignments is enormous, and creating embedding over it has memory cost issues. We represent KG as a 3rd-order binary tensor and move beyond the standard CP decomposition by using a data-specific generalized version of it. The generalization of the standard CP-ALS algorithm allows obtaining optimization gradients without a backpropagation mechanism. It reduces the memory needed in training while providing computational benefits. We propose a MEKER, a memory-efficient KG embedding model, which yields SOTA-comparable performance on link prediction tasks and KG-based Question Answering.