 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition-Aware Sequential Attention for Accurate Next Item Recommendations
Feb 24, 2026Sequential self-attention models usually rely on additive positional embeddings, which inject positional information into item representations at the input. In the absence of positional signals, the attention block is permutation-equivariant over sequence positions and thus has no intrinsic notion of temporal order beyond causal masking. We argue that additive positional embeddings make the attention mechanism only superficially sensitive to sequence order: positional information is entangled with item embedding semantics, propagates weakly in deep architectures, and limits the ability to capture rich sequential patterns. To address these limitations, we introduce a kernelized self-attention mechanism, where a learnable positional kernel operates purely in the position space, disentangled from semantic similarity, and directly modulates attention weights. When applied per attention block, this kernel enables adaptive multi-scale sequential modeling. Experiments on standard next-item prediction benchmarks show that our positional kernel attention consistently improves over strong competing baselines.
SplitLight: An Exploratory Toolkit for Recommender Systems Datasets and Splits
Feb 22, 2026Offline evaluation of recommender systems is often affected by hidden, under-documented choices in data preparation. Seemingly minor decisions in filtering, handling repeats, cold-start treatment, and splitting strategy design can substantially reorder model rankings and undermine reproducibility and cross-paper comparability. In this paper, we introduce SplitLight, an open-source exploratory toolkit that enables researchers and practitioners designing preprocessing and splitting pipelines or reviewing external artifacts to make these decisions measurable, comparable, and reportable. Given an interaction log and derived split subsets, SplitLight analyzes core and temporal dataset statistics, characterizes repeat consumption patterns and timestamp anomalies, and diagnoses split validity, including temporal leakage, cold-user/item exposure, and distribution shifts. SplitLight further allows side-by-side comparison of alternative splitting strategies through comprehensive aggregated summaries and interactive visualizations. Delivered as both a Python toolkit and an interactive no-code interface, SplitLight produces audit summaries that justify evaluation protocols and support transparent, reliable, and comparable experimentation in recommender systems research and industry.
Barlow Twins for Sequential Recommendation
Oct 30, 2025Sequential recommendation models must navigate sparse interaction data popularity bias and conflicting objectives like accuracy versus diversity While recent contrastive selfsupervised learning SSL methods offer improved accuracy they come with tradeoffs large batch requirements reliance on handcrafted augmentations and negative sampling that can reinforce popularity bias In this paper we introduce BT-SR a novel noncontrastive SSL framework that integrates the Barlow Twins redundancyreduction principle into a Transformerbased nextitem recommender BTSR learns embeddings that align users with similar shortterm behaviors while preserving longterm distinctionswithout requiring negative sampling or artificial perturbations This structuresensitive alignment allows BT-SR to more effectively recognize emerging user intent and mitigate the influence of noisy historical context Our experiments on five public benchmarks demonstrate that BTSR consistently improves nextitem prediction accuracy and significantly enhances longtail item coverage and recommendation calibration Crucially we show that a single hyperparameter can control the accuracydiversity tradeoff enabling practitioners to adapt recommendations to specific application needs
Low-rank surrogate modeling and stochastic zero-order optimization for training of neural networks with black-box layers
Sep 18, 2025The growing demand for energy-efficient, high-performance AI systems has led to increased attention on alternative computing platforms (e.g., photonic, neuromorphic) due to their potential to accelerate learning and inference. However, integrating such physical components into deep learning pipelines remains challenging, as physical devices often offer limited expressiveness, and their non-differentiable nature renders on-device backpropagation difficult or infeasible. This motivates the development of hybrid architectures that combine digital neural networks with reconfigurable physical layers, which effectively behave as black boxes. In this work, we present a framework for the end-to-end training of such hybrid networks. This framework integrates stochastic zeroth-order optimization for updating the physical layer's internal parameters with a dynamic low-rank surrogate model that enables gradient propagation through the physical layer. A key component of our approach is the implicit projector-splitting integrator algorithm, which updates the lightweight surrogate model after each forward pass with minimal hardware queries, thereby avoiding costly full matrix reconstruction. We demonstrate our method across diverse deep learning tasks, including: computer vision, audio classification, and language modeling. Notably, across all modalities, the proposed approach achieves near-digital baseline accuracy and consistently enables effective end-to-end training of hybrid models incorporating various non-differentiable physical components (spatial light modulators, microring resonators, and Mach-Zehnder interferometers). This work bridges hardware-aware deep learning and gradient-free optimization, thereby offering a practical pathway for integrating non-differentiable physical components into scalable, end-to-end trainable AI systems.
Dynamic Low-rank Approximation of Full-Matrix Preconditioner for Training Generalized Linear Models
Aug 28, 2025Adaptive gradient methods like Adagrad and its variants are widespread in large-scale optimization. However, their use of diagonal preconditioning matrices limits the ability to capture parameter correlations. Full-matrix adaptive methods, approximating the exact Hessian, can model these correlations and may enable faster convergence. At the same time, their computational and memory costs are often prohibitive for large-scale models. To address this limitation, we propose AdaGram, an optimizer that enables efficient full-matrix adaptive gradient updates. To reduce memory and computational overhead, we utilize fast symmetric factorization for computing the preconditioned update direction at each iteration. Additionally, we maintain the low-rank structure of a preconditioner along the optimization trajectory using matrix integrator methods. Numerical experiments on standard machine learning tasks show that AdaGram converges faster or matches the performance of diagonal adaptive optimizers when using rank five and smaller rank approximations. This demonstrates AdaGram's potential as a scalable solution for adaptive optimization in large models.
Benefiting from Negative yet Informative Feedback by Contrasting Opposing Sequential Patterns
Aug 20, 2025


We consider the task of learning from both positive and negative feedback in a sequential recommendation scenario, as both types of feedback are often present in user interactions. Meanwhile, conventional sequential learning models usually focus on considering and predicting positive interactions, ignoring that reducing items with negative feedback in recommendations improves user satisfaction with the service. Moreover, the negative feedback can potentially provide a useful signal for more accurate identification of true user interests. In this work, we propose to train two transformer encoders on separate positive and negative interaction sequences. We incorporate both types of feedback into the training objective of the sequential recommender using a composite loss function that includes positive and negative cross-entropy as well as a cleverly crafted contrastive term, that helps better modeling opposing patterns. We demonstrate the effectiveness of this approach in terms of increasing true-positive metrics compared to state-of-the-art sequential recommendation methods while reducing the number of wrongly promoted negative items.
Recommendation Is a Dish Better Served Warm
Aug 11, 2025In modern recommender systems, experimental settings typically include filtering out cold users and items based on a minimum interaction threshold. However, these thresholds are often chosen arbitrarily and vary widely across studies, leading to inconsistencies that can significantly affect the comparability and reliability of evaluation results. In this paper, we systematically explore the cold-start boundary by examining the criteria used to determine whether a user or an item should be considered cold. Our experiments incrementally vary the number of interactions for different items during training, and gradually update the length of user interaction histories during inference. We investigate the thresholds across several widely used datasets, commonly represented in recent papers from top-tier conferences, and on multiple established recommender baselines. Our findings show that inconsistent selection of cold-start thresholds can either result in the unnecessary removal of valuable data or lead to the misclassification of cold instances as warm, introducing more noise into the system.
Maximum Impact with Fewer Features: Efficient Feature Selection for Cold-Start Recommenders through Collaborative Importance Weighting
Aug 08, 2025



Cold-start challenges in recommender systems necessitate leveraging auxiliary features beyond user-item interactions. However, the presence of irrelevant or noisy features can degrade predictive performance, whereas an excessive number of features increases computational demands, leading to higher memory consumption and prolonged training times. To address this, we propose a feature selection strategy that prioritizes the user behavioral information. Our method enhances the feature representation by incorporating correlations from collaborative behavior data using a hybrid matrix factorization technique and then ranks features using a mechanism based on the maximum volume algorithm. This approach identifies the most influential features, striking a balance between recommendation accuracy and computational efficiency. We conduct an extensive evaluation across various datasets and hybrid recommendation models, demonstrating that our method excels in cold-start scenarios by selecting minimal yet highly effective feature subsets. Even under strict feature reduction, our approach surpasses existing feature selection techniques while maintaining superior efficiency.
Generalized Fisher-Weighted SVD: Scalable Kronecker-Factored Fisher Approximation for Compressing Large Language Models
May 23, 2025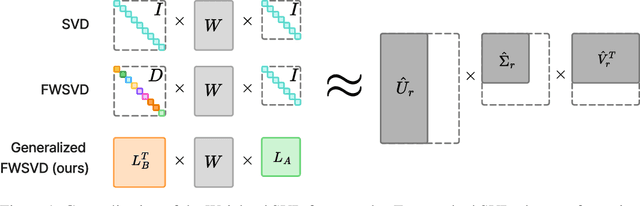
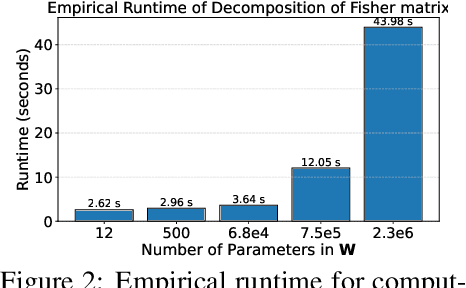

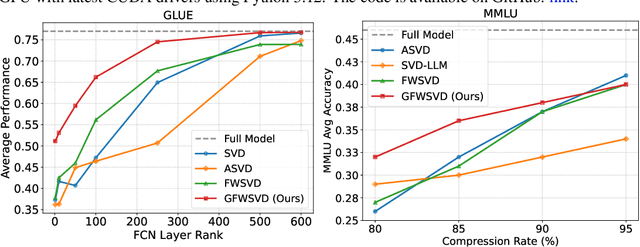
The Fisher information is a fundamental concept for characterizing the sensitivity of parameters in neural networks. However, leveraging the full observed Fisher information is too expensive for large models, so most methods rely on simple diagonal approximations. While efficient, this approach ignores parameter correlations, often resulting in reduced performance on downstream tasks. In this work, we mitigate these limitations and propose Generalized Fisher-Weighted SVD (GFWSVD), a post-training LLM compression technique that accounts for both diagonal and off-diagonal elements of the Fisher information matrix, providing a more accurate reflection of parameter importance. To make the method tractable, we introduce a scalable adaptation of the Kronecker-factored approximation algorithm for the observed Fisher information. We demonstrate the effectiveness of our method on LLM compression, showing improvements over existing compression baselines. For example, at a 20 compression rate on the MMLU benchmark, our method outperforms FWSVD, which is based on a diagonal approximation of the Fisher information, by 5 percent, SVD-LLM by 3 percent, and ASVD by 6 percent compression rate.
Knowledge Graph Completion with Mixed Geometry Tensor Factorization
Apr 03, 2025



In this paper, we propose a new geometric approach for knowledge graph completion via low rank tensor approximation. We augment a pretrained and well-established Euclidean model based on a Tucker tensor decomposition with a novel hyperbolic interaction term. This correction enables more nuanced capturing of distributional properties in data better aligned with real-world knowledge graphs. By combining two geometries together, our approach improves expressivity of the resulting model achieving new state-of-the-art link prediction accuracy with a significantly lower number of parameters compared to the previous Euclidean and hyperbolic models.