 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Latent Capacity of LLMs for One-Step Text Generation
May 27, 2025A recent study showed that large language models (LLMs) can reconstruct surprisingly long texts - up to thousands of tokens - via autoregressive generation from just one specially trained input embedding. In this work, we explore whether such reconstruction is possible without autoregression. We show that frozen LLMs can generate hundreds of accurate tokens in just one forward pass, when provided with only two learned embeddings. This reveals a surprising and underexplored capability of LLMs - multi-token generation without iterative decoding. We investigate the behaviour of these embeddings and provide insight into the type of information they encode. We also empirically show that although these representations are not unique for a given text, they form connected and local regions in embedding space - a property that suggests the potential of learning a dedicated encoder into that space.
SparseGrad: A Selective Method for Efficient Fine-tuning of MLP Layers
Oct 09, 2024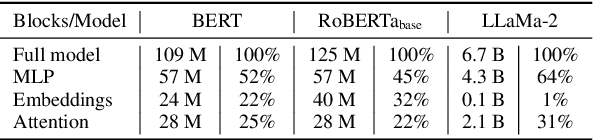
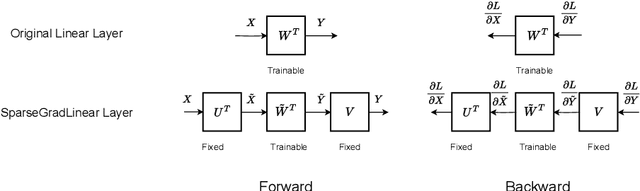
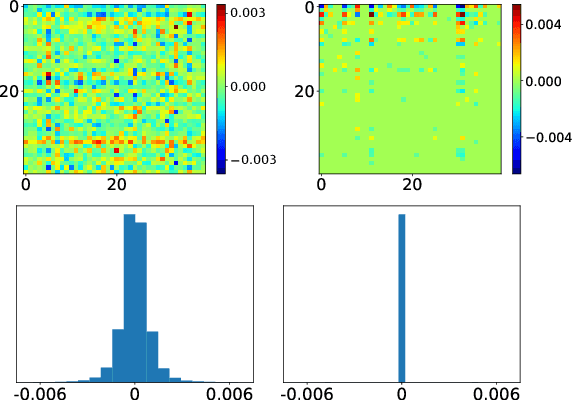
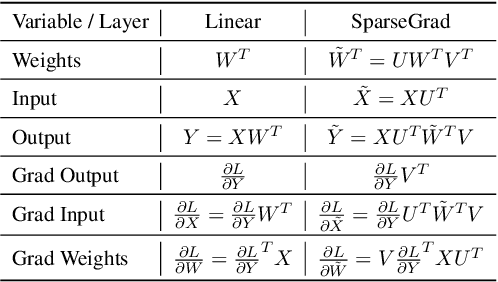
The performance of Transformer models has been enhanced by increasing the number of parameters and the length of the processed text. Consequently, fine-tuning the entire model becomes a memory-intensive process. High-performance methods for parameter-efficient fine-tuning (PEFT) typically work with Attention blocks and often overlook MLP blocks, which contain about half of the model parameters. We propose a new selective PEFT method, namely SparseGrad, that performs well on MLP blocks. We transfer layer gradients to a space where only about 1\% of the layer's elements remain significant. By converting gradients into a sparse structure, we reduce the number of updated parameters. We apply SparseGrad to fine-tune BERT and RoBERTa for the NLU task and LLaMa-2 for the Question-Answering task. In these experiments, with identical memory requirements, our method outperforms LoRA and MeProp, robust popular state-of-the-art PEFT approaches.
Scalable Cross-Entropy Loss for Sequential Recommendations with Large Item Catalogs
Sep 27, 2024Scalability issue plays a crucial role in productionizing modern recommender systems. Even lightweight architectures may suffer from high computational overload due to intermediate calculations, limiting their practicality in real-world applications. Specifically, applying full Cross-Entropy (CE) loss often yields state-of-the-art performance in terms of recommendations quality. Still, it suffers from excessive GPU memory utilization when dealing with large item catalogs. This paper introduces a novel Scalable Cross-Entropy (SCE) loss function in the sequential learning setup. It approximates the CE loss for datasets with large-size catalogs, enhancing both time efficiency and memory usage without compromising recommendations quality. Unlike traditional negative sampling methods, our approach utilizes a selective GPU-efficient computation strategy, focusing on the most informative elements of the catalog, particularly those most likely to be false positives. This is achieved by approximating the softmax distribution over a subset of the model outputs through the maximum inner product search. Experimental results on multiple datasets demonstrate the effectiveness of SCE in reducing peak memory usage by a factor of up to 100 compared to the alternatives, retaining or even exceeding their metrics values. The proposed approach also opens new perspectives for large-scale developments in different domains, such as large language models.
RECE: Reduced Cross-Entropy Loss for Large-Catalogue Sequential Recommenders
Aug 06, 2024Scalability is a major challenge in modern recommender systems. In sequential recommendations, full Cross-Entropy (CE) loss achieves state-of-the-art recommendation quality but consumes excessive GPU memory with large item catalogs, limiting its practicality. Using a GPU-efficient locality-sensitive hashing-like algorithm for approximating large tensor of logits, this paper introduces a novel RECE (REduced Cross-Entropy) loss. RECE significantly reduces memory consumption while allowing one to enjoy the state-of-the-art performance of full CE loss. Experimental results on various datasets show that RECE cuts training peak memory usage by up to 12 times compared to existing methods while retaining or exceeding performance metrics of CE loss. The approach also opens up new possibilities for large-scale applications in other domains.