 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseGrad: A Selective Method for Efficient Fine-tuning of MLP Layers
Oct 09, 2024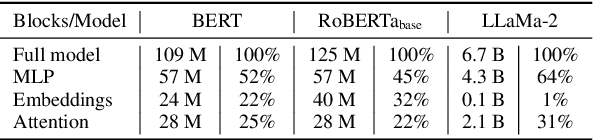
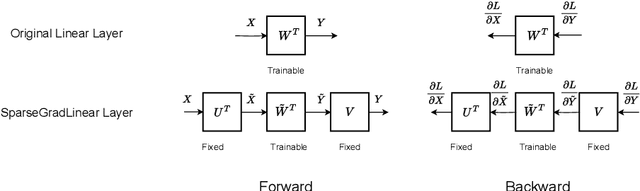
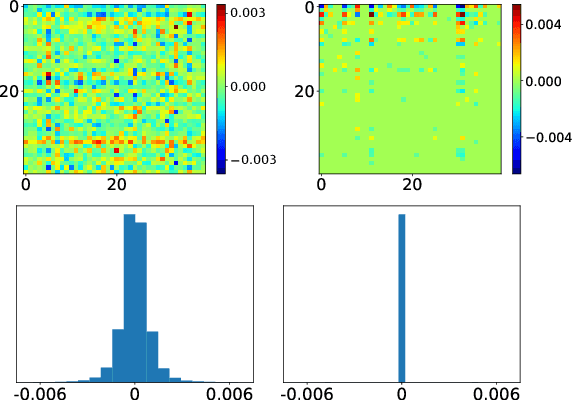
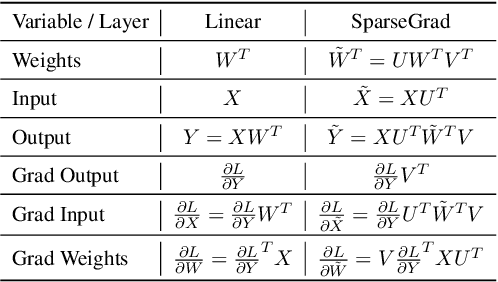
The performance of Transformer models has been enhanced by increasing the number of parameters and the length of the processed text. Consequently, fine-tuning the entire model becomes a memory-intensive process. High-performance methods for parameter-efficient fine-tuning (PEFT) typically work with Attention blocks and often overlook MLP blocks, which contain about half of the model parameters. We propose a new selective PEFT method, namely SparseGrad, that performs well on MLP blocks. We transfer layer gradients to a space where only about 1\% of the layer's elements remain significant. By converting gradients into a sparse structure, we reduce the number of updated parameters. We apply SparseGrad to fine-tune BERT and RoBERTa for the NLU task and LLaMa-2 for the Question-Answering task. In these experiments, with identical memory requirements, our method outperforms LoRA and MeProp, robust popular state-of-the-art PEFT approaches.
Efficient Rectangular Maximal-Volume Algorithm for Rating Elicitation in Collaborative Filtering
Oct 16, 2016
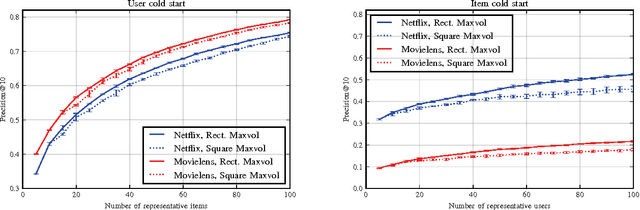


Cold start problem in Collaborative Filtering can be solved by asking new users to rate a small seed set of representative items or by asking representative users to rate a new item. The question is how to build a seed set that can give enough preference information for making good recommendations. One of the most successful approaches, called Representative Based Matrix Factorization, is based on Maxvol algorithm. Unfortunately, this approach has one important limitation --- a seed set of a particular size requires a rating matrix factorization of fixed rank that should coincide with that size. This is not necessarily optimal in the general case. In the current paper, we introduce a fast algorithm for an analytical generalization of this approach that we call Rectangular Maxvol. It allows the rank of factorization to be lower than the required size of the seed set. Moreover, the paper includes the theoretical analysis of the method's error, the complexity analysis of the existing methods and the comparison to the state-of-the-art approaches.