 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Fisher-Weighted SVD: Scalable Kronecker-Factored Fisher Approximation for Compressing Large Language Models
May 23, 2025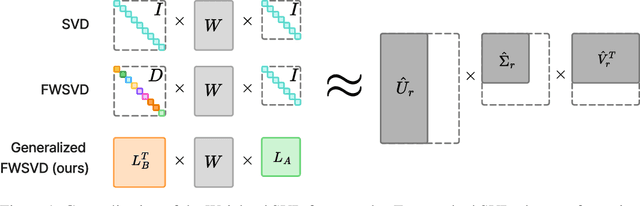
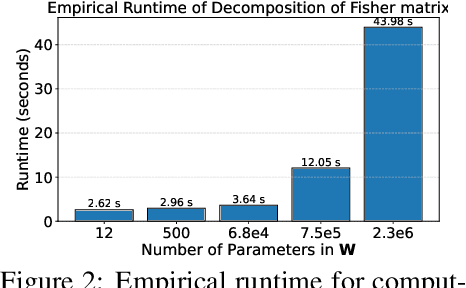

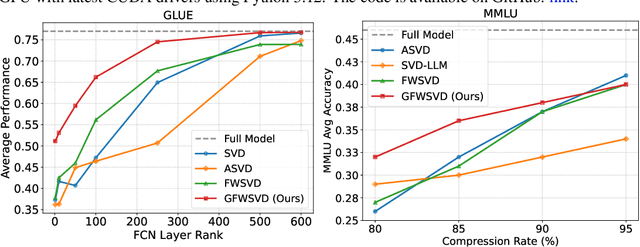
The Fisher information is a fundamental concept for characterizing the sensitivity of parameters in neural networks. However, leveraging the full observed Fisher information is too expensive for large models, so most methods rely on simple diagonal approximations. While efficient, this approach ignores parameter correlations, often resulting in reduced performance on downstream tasks. In this work, we mitigate these limitations and propose Generalized Fisher-Weighted SVD (GFWSVD), a post-training LLM compression technique that accounts for both diagonal and off-diagonal elements of the Fisher information matrix, providing a more accurate reflection of parameter importance. To make the method tractable, we introduce a scalable adaptation of the Kronecker-factored approximation algorithm for the observed Fisher information. We demonstrate the effectiveness of our method on LLM compression, showing improvements over existing compression baselines. For example, at a 20 compression rate on the MMLU benchmark, our method outperforms FWSVD, which is based on a diagonal approximation of the Fisher information, by 5 percent, SVD-LLM by 3 percent, and ASVD by 6 percent compression rate.
Quantization of Large Language Models with an Overdetermined Basis
Apr 15, 2024In this paper, we introduce an algorithm for data quantization based on the principles of Kashin representation. This approach hinges on decomposing any given vector, matrix, or tensor into two factors. The first factor maintains a small infinity norm, while the second exhibits a similarly constrained norm when multiplied by an orthogonal matrix. Surprisingly, the entries of factors after decomposition are well-concentrated around several peaks, which allows us to efficiently replace them with corresponding centroids for quantization purposes. We study the theoretical properties of the proposed approach and rigorously evaluate our compression algorithm in the context of next-word prediction tasks and on a set of downstream tasks for text classification. Our findings demonstrate that Kashin Quantization achieves competitive or superior quality in model performance while ensuring data compression, marking a significant advancement in the field of data quantization.
LoTR: Low Tensor Rank Weight Adaptation
Feb 05, 2024In this paper we generalize and extend an idea of low-rank adaptation (LoRA) of large language models (LLMs) based on Transformer architecture. Widely used LoRA-like methods of fine-tuning LLMs are based on matrix factorization of gradient update. We introduce LoTR, a novel approach for parameter-efficient fine-tuning of LLMs which represents a gradient update to parameters in a form of tensor decomposition. Low-rank adapter for each layer is constructed as a product of three matrices, and tensor structure arises from sharing left and right multipliers of this product among layers. Simultaneous compression of a sequence of layers with low-rank tensor representation allows LoTR to archive even better parameter efficiency then LoRA especially for deep models. Moreover, the core tensor does not depend on original weight dimension and can be made arbitrary small, which allows for extremely cheap and fast downstream fine-tuning.
Run LoRA Run: Faster and Lighter LoRA Implementations
Dec 06, 2023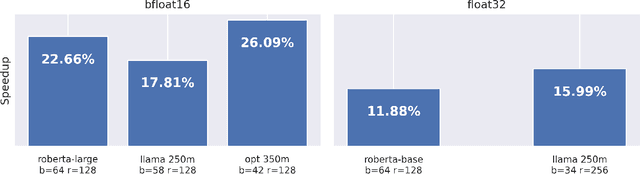

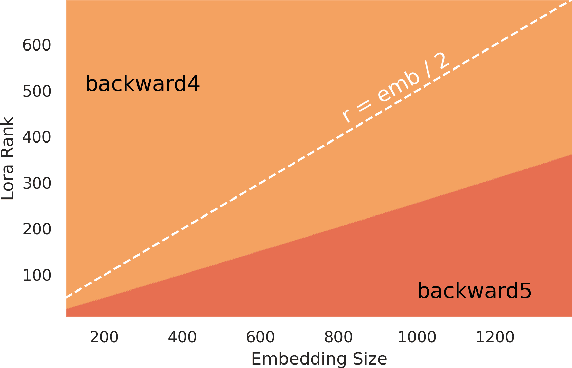
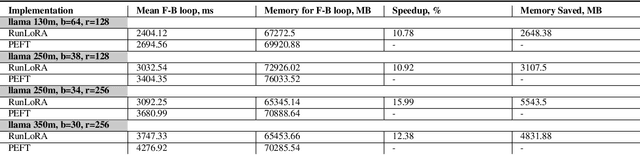
LoRA is a technique that reduces the number of trainable parameters in a neural network by introducing low-rank adapters to linear layers. This technique is used both for fine-tuning (LoRA, QLoRA) and full train (ReLoRA). This paper presents the RunLoRA framework for efficient implementations of LoRA that significantly improves the speed of neural network training and fine-tuning using low-rank adapters. The proposed implementation optimizes the computation of LoRA operations based on dimensions of corresponding linear layer, layer input dimensions and lora rank by choosing best forward and backward computation graph based on FLOPs and time estimations, resulting in faster training without sacrificing accuracy. The experimental results show up to 17% speedup on Llama family of models.
Quantization Aware Factorization for Deep Neural Network Compression
Aug 08, 2023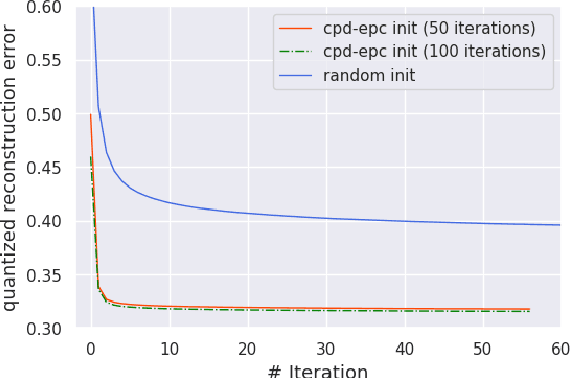
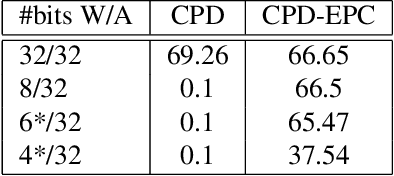
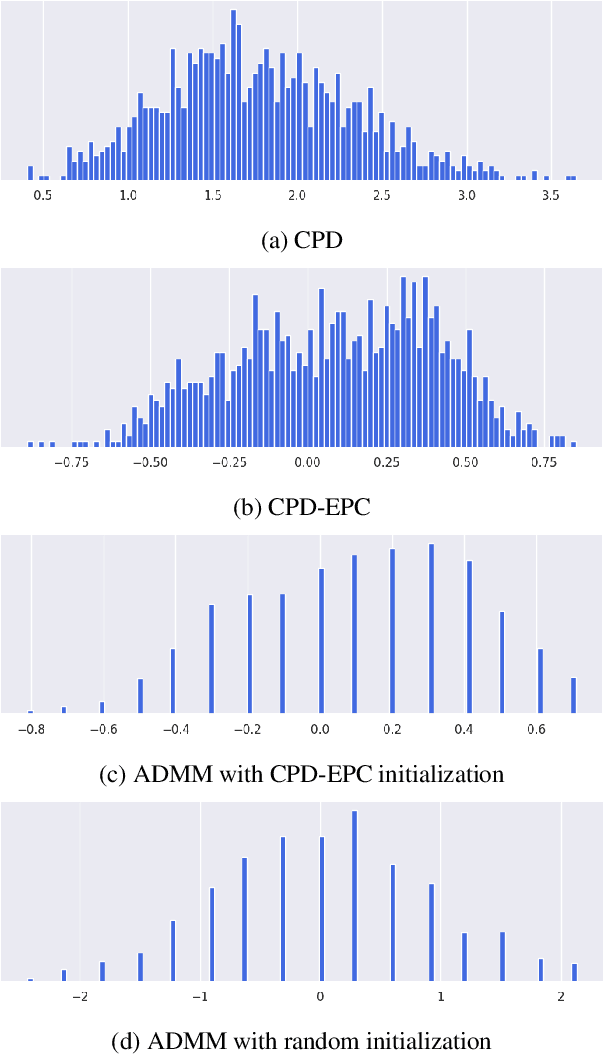
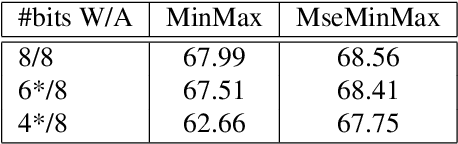
Tensor decomposition of convolutional and fully-connected layers is an effective way to reduce parameters and FLOP in neural networks. Due to memory and power consumption limitations of mobile or embedded devices, the quantization step is usually necessary when pre-trained models are deployed. A conventional post-training quantization approach applied to networks with decomposed weights yields a drop in accuracy. This motivated us to develop an algorithm that finds tensor approximation directly with quantized factors and thus benefit from both compression techniques while keeping the prediction quality of the model. Namely, we propose to use Alternating Direction Method of Multipliers (ADMM) for Canonical Polyadic (CP) decomposition with factors whose elements lie on a specified quantization grid. We compress neural network weights with a devised algorithm and evaluate it's prediction quality and performance. We compare our approach to state-of-the-art post-training quantization methods and demonstrate competitive results and high flexibility in achiving a desirable quality-performance tradeoff.
Survey on Large Scale Neural Network Training
Feb 21, 2022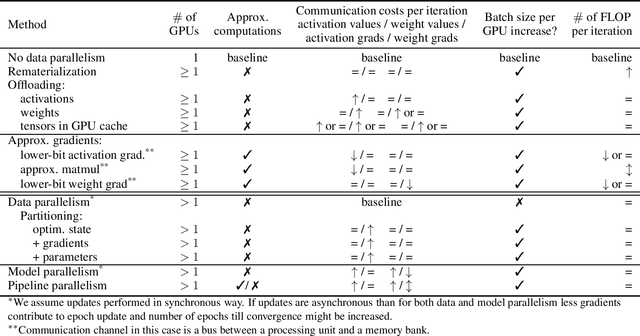
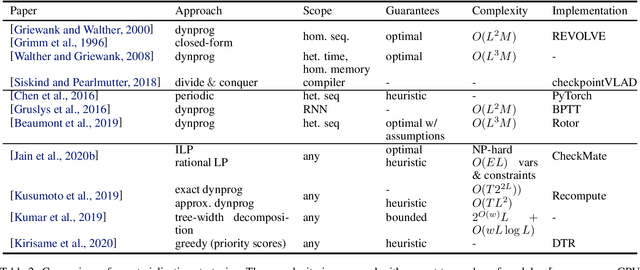
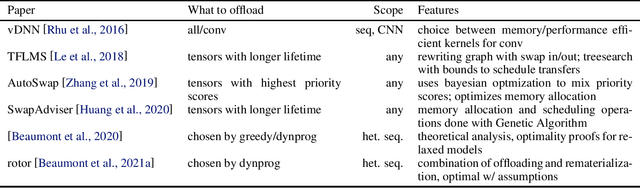
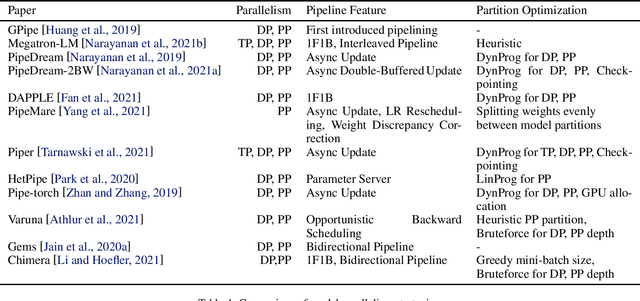
Modern Deep Neural Networks (DNNs) require significant memory to store weight, activations, and other intermediate tensors during training. Hence, many models do not fit one GPU device or can be trained using only a small per-GPU batch size. This survey provides a systematic overview of the approaches that enable more efficient DNNs training. We analyze techniques that save memory and make good use of computation and communication resources on architectures with a single or several GPUs. We summarize the main categories of strategies and compare strategies within and across categories. Along with approaches proposed in the literature, we discuss available implementations.