 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoTR: Low Tensor Rank Weight Adaptation
Feb 05, 2024In this paper we generalize and extend an idea of low-rank adaptation (LoRA) of large language models (LLMs) based on Transformer architecture. Widely used LoRA-like methods of fine-tuning LLMs are based on matrix factorization of gradient update. We introduce LoTR, a novel approach for parameter-efficient fine-tuning of LLMs which represents a gradient update to parameters in a form of tensor decomposition. Low-rank adapter for each layer is constructed as a product of three matrices, and tensor structure arises from sharing left and right multipliers of this product among layers. Simultaneous compression of a sequence of layers with low-rank tensor representation allows LoTR to archive even better parameter efficiency then LoRA especially for deep models. Moreover, the core tensor does not depend on original weight dimension and can be made arbitrary small, which allows for extremely cheap and fast downstream fine-tuning.
Meta-Solver for Neural Ordinary Differential Equations
Mar 15, 2021
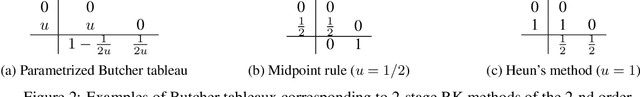

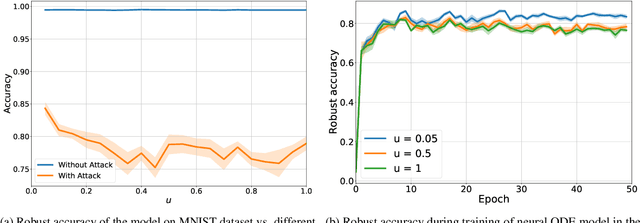
A conventional approach to train neural ordinary differential equations (ODEs) is to fix an ODE solver and then learn the neural network's weights to optimize a target loss function. However, such an approach is tailored for a specific discretization method and its properties, which may not be optimal for the selected application and yield the overfitting to the given solver. In our paper, we investigate how the variability in solvers' space can improve neural ODEs performance. We consider a family of Runge-Kutta methods that are parameterized by no more than two scalar variables. Based on the solvers' properties, we propose an approach to decrease neural ODEs overfitting to the pre-defined solver, along with a criterion to evaluate such behaviour. Moreover, we show that the right choice of solver parameterization can significantly affect neural ODEs models in terms of robustness to adversarial attacks. Recently it was shown that neural ODEs demonstrate superiority over conventional CNNs in terms of robustness. Our work demonstrates that the model robustness can be further improved by optimizing solver choice for a given task. The source code to reproduce our experiments is available at https://github.com/juliagusak/neural-ode-metasolver.
Towards Understanding Normalization in Neural ODEs
Apr 27, 2020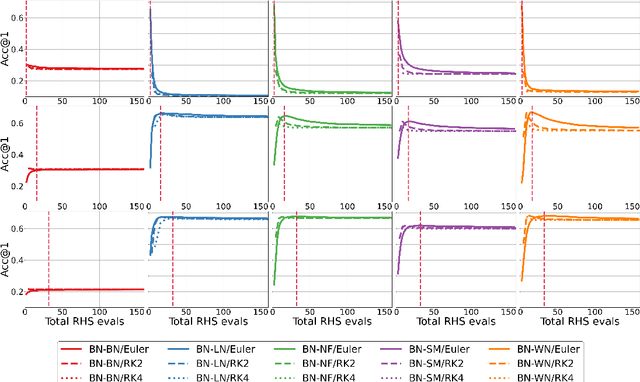
Normalization is an important and vastly investigated technique in deep learning. However, its role for Ordinary Differential Equation based networks (neural ODEs) is still poorly understood. This paper investigates how different normalization techniques affect the performance of neural ODEs. Particularly, we show that it is possible to achieve 93% accuracy in the CIFAR-10 classification task, and to the best of our knowledge, this is the highest reported accuracy among neural ODEs tested on this problem.
Interpolated Adjoint Method for Neural ODEs
Mar 11, 2020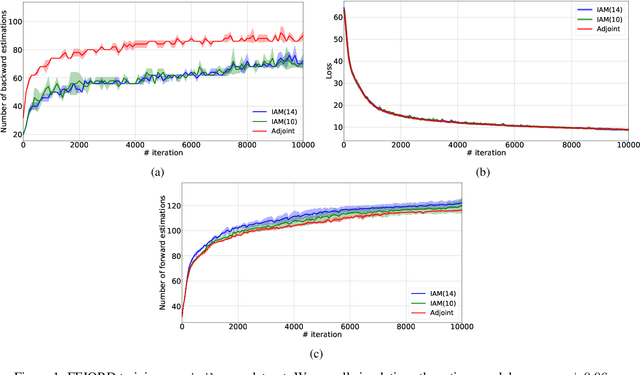
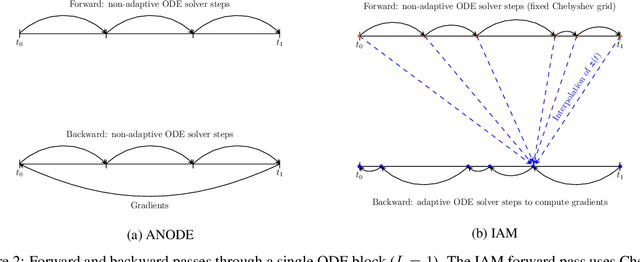

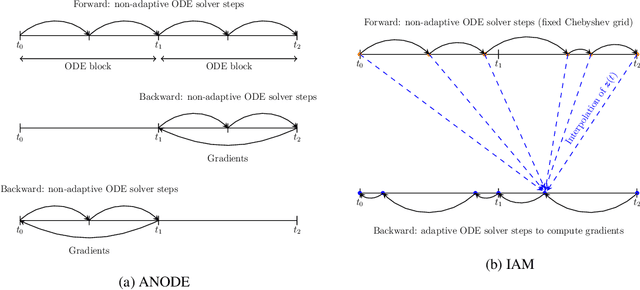
In this paper, we propose a method, which allows us to alleviate or completely avoid the notorious problem of numerical instability and stiffness of the adjoint method for training neural ODE. On the backward pass, we propose to use the machinery of smooth function interpolation to restore the trajectory obtained during the forward integration. We show the viability of our approach, both in theory and practice.
Reduced-Order Modeling of Deep Neural Networks
Nov 25, 2019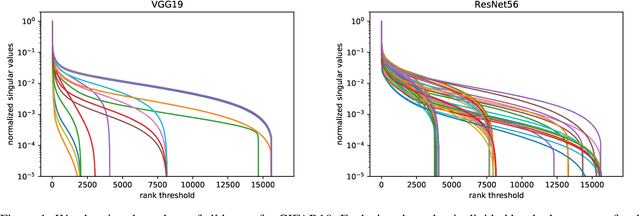

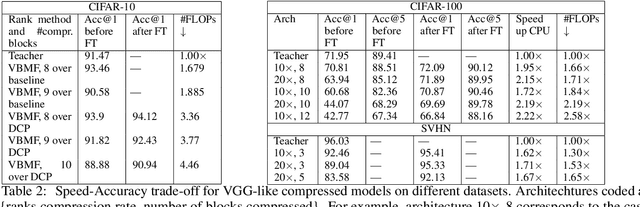
We introduce a new method for speeding up the inference of deep neural networks. It is somewhat inspired by the reduced-order modeling techniques for dynamical systems.The cornerstone of the proposed method is the maximum volume algorithm. We demonstrate efficiency on neural networks pre-trained on different datasets. We show that in many practical cases it is possible to replace convolutional layers with much smaller fully-connected layers with a relatively small drop in accuracy.
Active Subspace of Neural Networks: Structural Analysis and Universal Attacks
Oct 29, 2019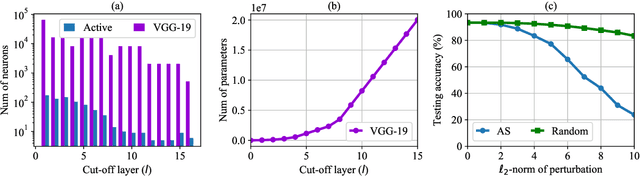
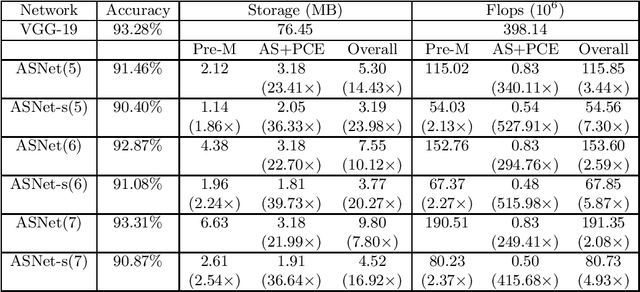
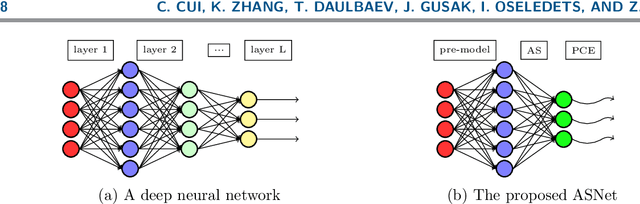
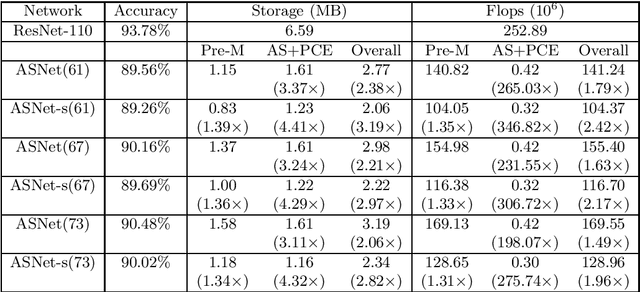
Active subspace is a model reduction method widely used in the uncertainty quantification community. In this paper, we propose analyzing the internal structure and vulnerability and deep neural networks using active subspace. Firstly, we employ the active subspace to measure the number of "active neurons" at each intermediate layer and reduce the number of neurons from several thousands to several dozens. This motivates us to change the network structure and to develop a new and more compact network, referred to as {ASNet}, that has significantly fewer model parameters. Secondly, we propose analyzing the vulnerability of a neural network using active subspace and finding an additive universal adversarial attack vector that can misclassify a dataset with a high probability. Our experiments on CIFAR-10 show that ASNet can achieve 23.98$\times$ parameter and 7.30$\times$ flops reduction. The universal active subspace attack vector can achieve around 20% higher attack ratio compared with the existing approach in all of our numerical experiments. The PyTorch codes for this paper are available online.