 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLETI: Latency Estimation Tool and Investigation of Neural Networks inference on Mobile GPU
Oct 06, 2020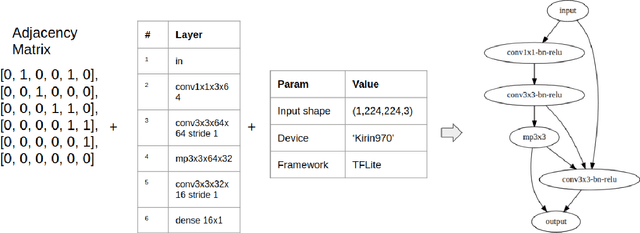


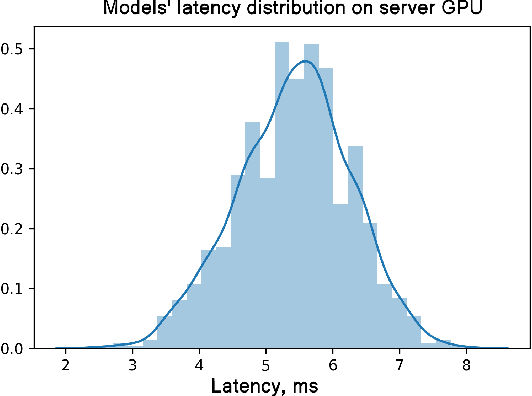
A lot of deep learning applications are desired to be run on mobile devices. Both accuracy and inference time are meaningful for a lot of them. While the number of FLOPs is usually used as a proxy for neural network latency, it may be not the best choice. In order to obtain a better approximation of latency, research community uses look-up tables of all possible layers for latency calculation for the final prediction of the inference on mobile CPU. It requires only a small number of experiments. Unfortunately, on mobile GPU this method is not applicable in a straight-forward way and shows low precision. In this work, we consider latency approximation on mobile GPU as a data and hardware-specific problem. Our main goal is to construct a convenient latency estimation tool for investigation(LETI) of neural network inference and building robust and accurate latency prediction models for each specific task. To achieve this goal, we build open-source tools which provide a convenient way to conduct massive experiments on different target devices focusing on mobile GPU. After evaluation of the dataset, we learn the regression model on experimental data and use it for future latency prediction and analysis. We experimentally demonstrate the applicability of such an approach on a subset of popular NAS-Benchmark 101 dataset and also evaluate the most popular neural network architectures for two mobile GPUs. As a result, we construct latency prediction model with good precision on the target evaluation subset. We consider LETI as a useful tool for neural architecture search or massive latency evaluation. The project is available at https://github.com/leti-ai
Using Reinforcement Learning in the Algorithmic Trading Problem
Feb 26, 2020


The development of reinforced learning methods has extended application to many areas including algorithmic trading. In this paper trading on the stock exchange is interpreted into a game with a Markov property consisting of states, actions, and rewards. A system for trading the fixed volume of a financial instrument is proposed and experimentally tested; this is based on the asynchronous advantage actor-critic method with the use of several neural network architectures. The application of recurrent layers in this approach is investigated. The experiments were performed on real anonymized data. The best architecture demonstrated a trading strategy for the RTS Index futures (MOEX:RTSI) with a profitability of 66% per annum accounting for commission. The project source code is available via the following link: http://github.com/evgps/a3c_trading.
Reduced-Order Modeling of Deep Neural Networks
Nov 25, 2019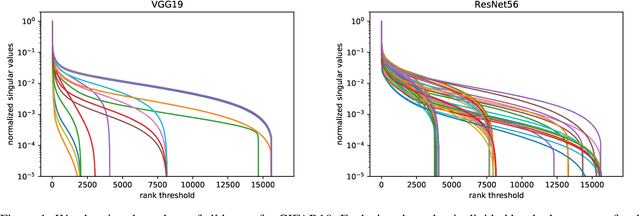

We introduce a new method for speeding up the inference of deep neural networks. It is somewhat inspired by the reduced-order modeling techniques for dynamical systems.The cornerstone of the proposed method is the maximum volume algorithm. We demonstrate efficiency on neural networks pre-trained on different datasets. We show that in many practical cases it is possible to replace convolutional layers with much smaller fully-connected layers with a relatively small drop in accuracy.
One time is not enough: iterative tensor decomposition for neural network compression
Mar 24, 2019

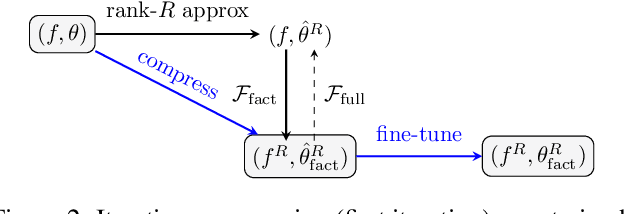

The low-rank tensor approximation is very promising for the compression of deep neural networks. We propose a new simple and efficient iterative approach, which alternates low-rank factorization with a smart rank selection and fine-tuning. We demonstrate the efficiency of our method comparing to non-iterative ones. Our approach improves the compression rate while maintaining the accuracy for a variety of tasks.