 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConDiff: A Challenging Dataset for Neural Solvers of Partial Differential Equations
Jun 07, 2024We present ConDiff, a novel dataset for scientific machine learning. ConDiff focuses on the diffusion equation with varying coefficients, a fundamental problem in many applications of parametric partial differential equations (PDEs). The main novelty of the proposed dataset is that we consider discontinuous coefficients with high contrast. These coefficient functions are sampled from a selected set of distributions. This class of problems is not only of great academic interest, but is also the basis for describing various environmental and industrial problems. In this way, ConDiff shortens the gap with real-world problems while remaining fully synthetic and easy to use. ConDiff consists of a diverse set of diffusion equations with coefficients covering a wide range of contrast levels and heterogeneity with a measurable complexity metric for clearer comparison between different coefficient functions. We baseline ConDiff on standard deep learning models in the field of scientific machine learning. By providing a large number of problem instances, each with its own coefficient function and right-hand side, we hope to encourage the development of novel physics-based deep learning approaches, such as neural operators and physics-informed neural networks, ultimately driving progress towards more accurate and efficient solutions of complex PDE problems.
Astral: training physics-informed neural networks with error majorants
Jun 04, 2024


The primal approach to physics-informed learning is a residual minimization. We argue that residual is, at best, an indirect measure of the error of approximate solution and propose to train with error majorant instead. Since error majorant provides a direct upper bound on error, one can reliably estimate how close PiNN is to the exact solution and stop the optimization process when the desired accuracy is reached. We call loss function associated with error majorant $\textbf{Astral}$: neur$\textbf{A}$l a po$\textbf{ST}$erio$\textbf{RI}$ function$\textbf{A}$l Loss. To compare Astral and residual loss functions, we illustrate how error majorants can be derived for various PDEs and conduct experiments with diffusion equations (including anisotropic and in the L-shaped domain), convection-diffusion equation, temporal discretization of Maxwell's equation, and magnetostatics problem. The results indicate that Astral loss is competitive to the residual loss, typically leading to faster convergence and lower error (e.g., for Maxwell's equations, we observe an order of magnitude better relative error and training time). We also report that the error estimate obtained with Astral loss is usually tight enough to be informative, e.g., for a highly anisotropic equation, on average, Astral overestimates error by a factor of $1.5$, and for convection-diffusion by a factor of $1.7$.
Learning from Linear Algebra: A Graph Neural Network Approach to Preconditioner Design for Conjugate Gradient Solvers
May 24, 2024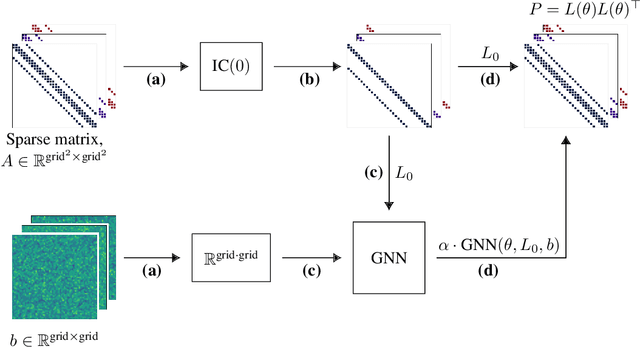
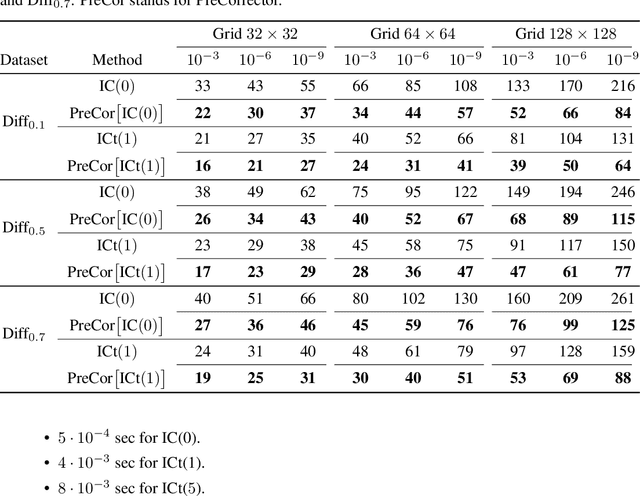
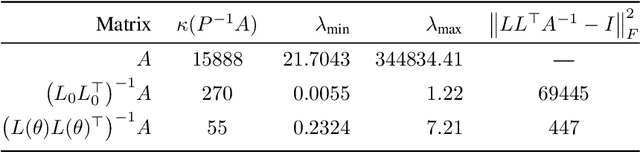
Large linear systems are ubiquitous in modern computational science. The main recipe for solving them is iterative solvers with well-designed preconditioners. Deep learning models may be used to precondition residuals during iteration of such linear solvers as the conjugate gradient (CG) method. Neural network models require an enormous number of parameters to approximate well in this setup. Another approach is to take advantage of small graph neural networks (GNNs) to construct preconditioners of the predefined sparsity pattern. In our work, we recall well-established preconditioners from linear algebra and use them as a starting point for training the GNN. Numerical experiments demonstrate that our approach outperforms both classical methods and neural network-based preconditioning. We also provide a heuristic justification for the loss function used and validate our approach on complex datasets.
Quantization of Large Language Models with an Overdetermined Basis
Apr 15, 2024In this paper, we introduce an algorithm for data quantization based on the principles of Kashin representation. This approach hinges on decomposing any given vector, matrix, or tensor into two factors. The first factor maintains a small infinity norm, while the second exhibits a similarly constrained norm when multiplied by an orthogonal matrix. Surprisingly, the entries of factors after decomposition are well-concentrated around several peaks, which allows us to efficiently replace them with corresponding centroids for quantization purposes. We study the theoretical properties of the proposed approach and rigorously evaluate our compression algorithm in the context of next-word prediction tasks and on a set of downstream tasks for text classification. Our findings demonstrate that Kashin Quantization achieves competitive or superior quality in model performance while ensuring data compression, marking a significant advancement in the field of data quantization.