 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Linear Algebra: A Graph Neural Network Approach to Preconditioner Design for Conjugate Gradient Solvers
Paper and Code
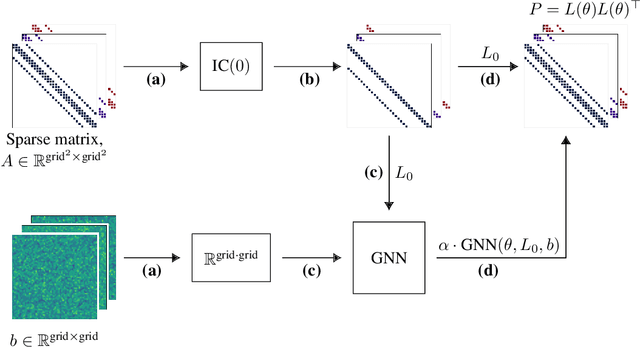
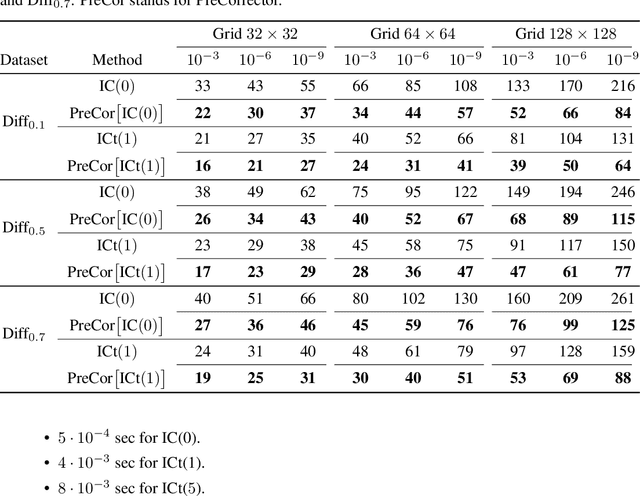
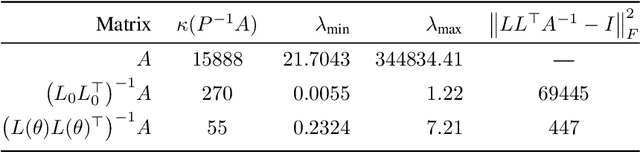
Large linear systems are ubiquitous in modern computational science. The main recipe for solving them is iterative solvers with well-designed preconditioners. Deep learning models may be used to precondition residuals during iteration of such linear solvers as the conjugate gradient (CG) method. Neural network models require an enormous number of parameters to approximate well in this setup. Another approach is to take advantage of small graph neural networks (GNNs) to construct preconditioners of the predefined sparsity pattern. In our work, we recall well-established preconditioners from linear algebra and use them as a starting point for training the GNN. Numerical experiments demonstrate that our approach outperforms both classical methods and neural network-based preconditioning. We also provide a heuristic justification for the loss function used and validate our approach on complex datasets.