 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinc Kolmogorov-Arnold Network and Its Applications on Physics-informed Neural Networks
Oct 05, 2024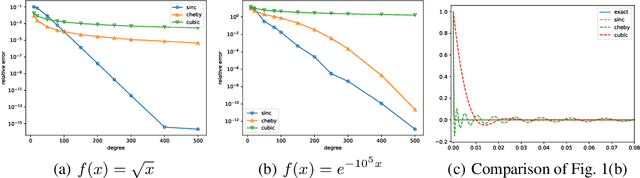
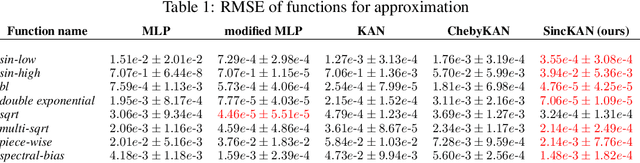


In this paper, we propose to use Sinc interpolation in the context of Kolmogorov-Arnold Networks, neural networks with learnable activation functions, which recently gained attention as alternatives to multilayer perceptron. Many different function representations have already been tried, but we show that Sinc interpolation proposes a viable alternative, since it is known in numerical analysis to represent well both smooth functions and functions with singularities. This is important not only for function approximation but also for the solutions of partial differential equations with physics-informed neural networks. Through a series of experiments, we show that SincKANs provide better results in almost all of the examples we have considered.
Fourier Spectral Physics Informed Neural Network: An Efficient and Low-Memory PINN
Aug 29, 2024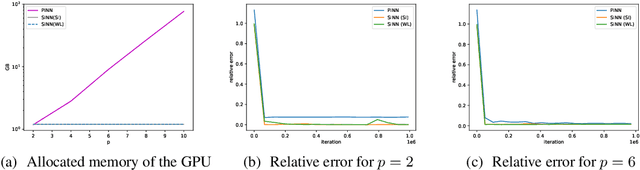

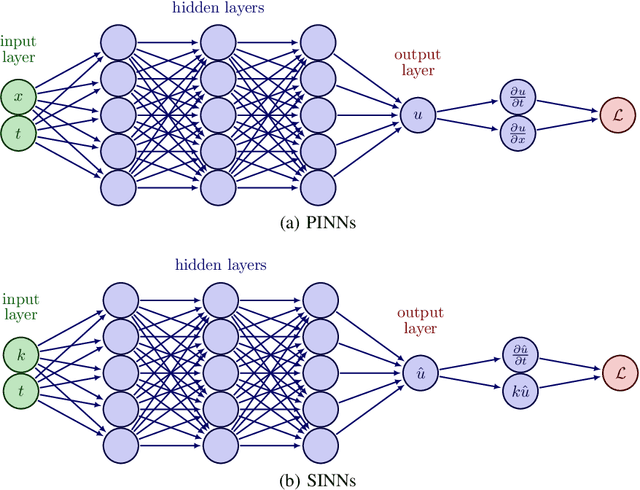

With growing investigations into solving partial differential equations by physics-informed neural networks (PINNs), more accurate and efficient PINNs are required to meet the practical demands of scientific computing. One bottleneck of current PINNs is computing the high-order derivatives via automatic differentiation which often necessitates substantial computing resources. In this paper, we focus on removing the automatic differentiation of the spatial derivatives and propose a spectral-based neural network that substitutes the differential operator with a multiplication. Compared to the PINNs, our approach requires lower memory and shorter training time. Thanks to the exponential convergence of the spectral basis, our approach is more accurate. Moreover, to handle the different situations between physics domain and spectral domain, we provide two strategies to train networks by their spectral information. Through a series of comprehensive experiments, We validate the aforementioned merits of our proposed network.
Astral: training physics-informed neural networks with error majorants
Jun 04, 2024The primal approach to physics-informed learning is a residual minimization. We argue that residual is, at best, an indirect measure of the error of approximate solution and propose to train with error majorant instead. Since error majorant provides a direct upper bound on error, one can reliably estimate how close PiNN is to the exact solution and stop the optimization process when the desired accuracy is reached. We call loss function associated with error majorant $\textbf{Astral}$: neur$\textbf{A}$l a po$\textbf{ST}$erio$\textbf{RI}$ function$\textbf{A}$l Loss. To compare Astral and residual loss functions, we illustrate how error majorants can be derived for various PDEs and conduct experiments with diffusion equations (including anisotropic and in the L-shaped domain), convection-diffusion equation, temporal discretization of Maxwell's equation, and magnetostatics problem. The results indicate that Astral loss is competitive to the residual loss, typically leading to faster convergence and lower error (e.g., for Maxwell's equations, we observe an order of magnitude better relative error and training time). We also report that the error estimate obtained with Astral loss is usually tight enough to be informative, e.g., for a highly anisotropic equation, on average, Astral overestimates error by a factor of $1.5$, and for convection-diffusion by a factor of $1.7$.