 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Channel Automatic Music Transcription Using Tensor Algebra
Jul 23, 2021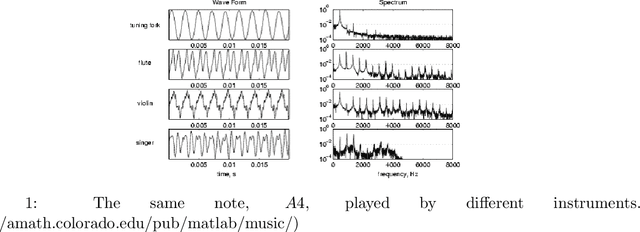
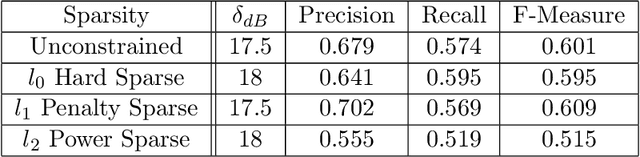

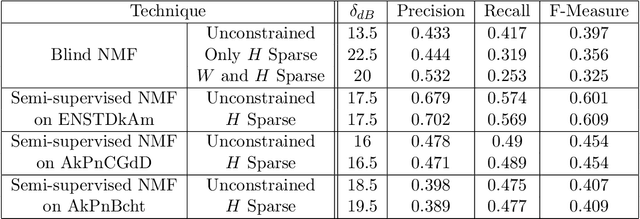
Music is an art, perceived in unique ways by every listener, coming from acoustic signals. In the meantime, standards as musical scores exist to describe it. Even if humans can make this transcription, it is costly in terms of time and efforts, even more with the explosion of information consecutively to the rise of the Internet. In that sense, researches are driven in the direction of Automatic Music Transcription. While this task is considered solved in the case of single notes, it is still open when notes superpose themselves, forming chords. This report aims at developing some of the existing techniques towards Music Transcription, particularly matrix factorization, and introducing the concept of multi-channel automatic music transcription. This concept will be explored with mathematical objects called tensors.
dEchorate: a Calibrated Room Impulse Response Database for Echo-aware Signal Processing
Apr 27, 2021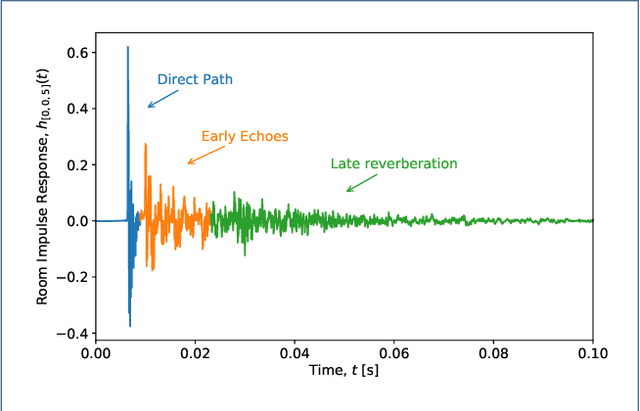
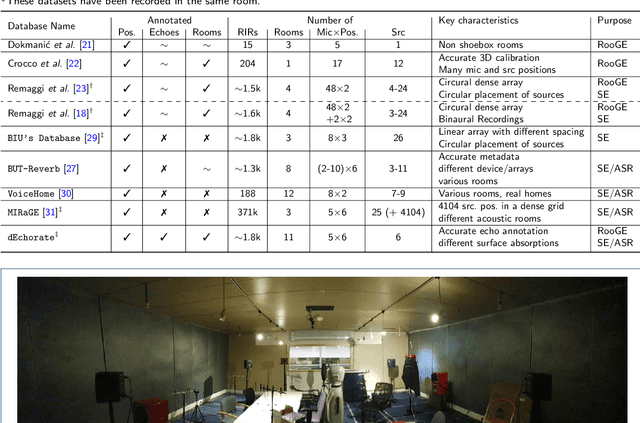

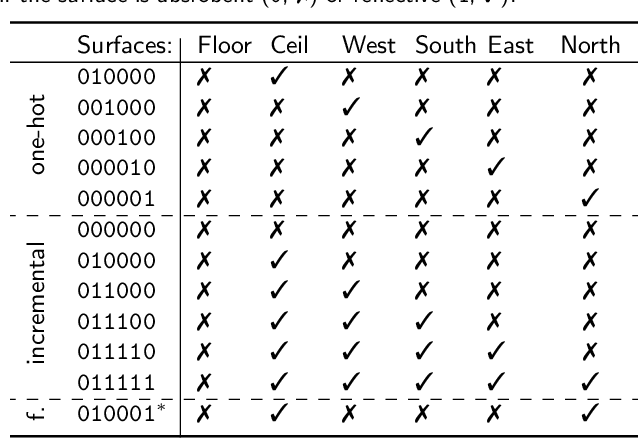
This paper presents dEchorate: a new database of measured multichannel Room Impulse Responses (RIRs) including annotations of early echo timings and 3D positions of microphones, real sources and image sources under different wall configurations in a cuboid room. These data provide a tool for benchmarking recent methods in echo-aware speech enhancement, room geometry estimation, RIR estimation, acoustic echo retrieval, microphone calibration, echo labeling and reflectors estimation. The database is accompanied with software utilities to easily access, manipulate and visualize the data as well as baseline methods for echo-related tasks.
Uncovering audio patterns in music with Nonnegative Tucker Decomposition for structural segmentation
Apr 17, 2021
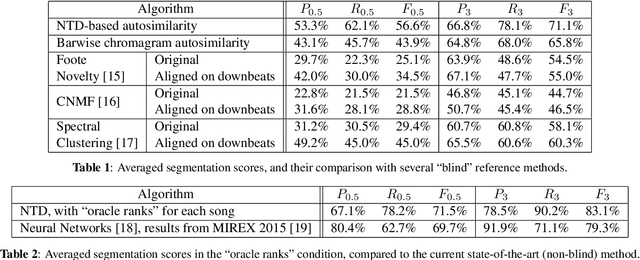
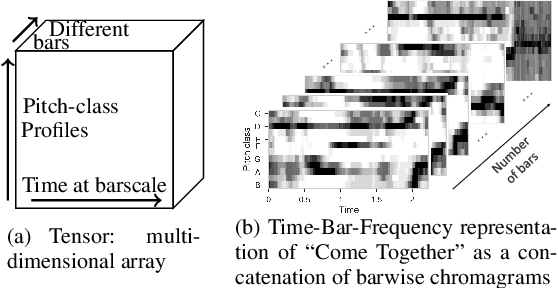
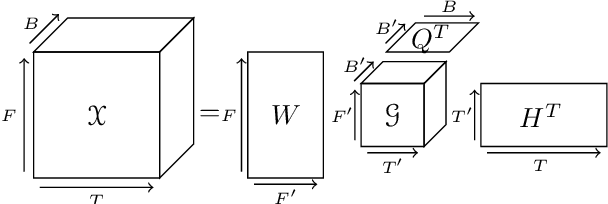
Recent work has proposed the use of tensor decomposition to model repetitions and to separate tracks in loop-based electronic music. The present work investigates further on the ability of Nonnegative Tucker Decompositon (NTD) to uncover musical patterns and structure in pop songs in their audio form. Exploiting the fact that NTD tends to express the content of bars as linear combinations of a few patterns, we illustrate the ability of the decomposition to capture and single out repeated motifs in the corresponding compressed space, which can be interpreted from a musical viewpoint. The resulting features also turn out to be efficient for structural segmentation, leading to experimental results on the RWC Pop data set which are potentially challenging state-of-the-art approaches that rely on extensive example-based learning schemes.
* 7 pages, 6 figures; Code and experiments details available at https://gitlab.inria.fr/amarmore/musicntd/-/tree/0.1.0; Experiments details available at https://ax-le.github.io/resources/ISMIR2020/Notebooks_mainpage.html