 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Multimodal and Language-Agnostic Sentence Embeddings for Abstractive Summarization
Mar 09, 2026Abstractive summarization aims to generate concise summaries by creating new sentences, allowing for flexible rephrasing. However, this approach can be vulnerable to inaccuracies, particularly `hallucinations' where the model introduces non-existent information. In this paper, we leverage the use of multimodal and multilingual sentence embeddings derived from pretrained models such as LaBSE, SONAR, and BGE-M3, and feed them into a modified BART-based French model. A Named Entity Injection mechanism that appends tokenized named entities to the decoder input is introduced, in order to improve the factual consistency of the generated summary. Our novel framework, SBARThez, is applicable to both text and speech inputs and supports cross-lingual summarization; it shows competitive performance relative to token-level baselines, especially for low-resource languages, while generating more concise and abstract summaries.
Findings from Experiments of On-line Joint Reinforcement Learning of Semantic Parser and Dialogue Manager with real Users
Oct 25, 2021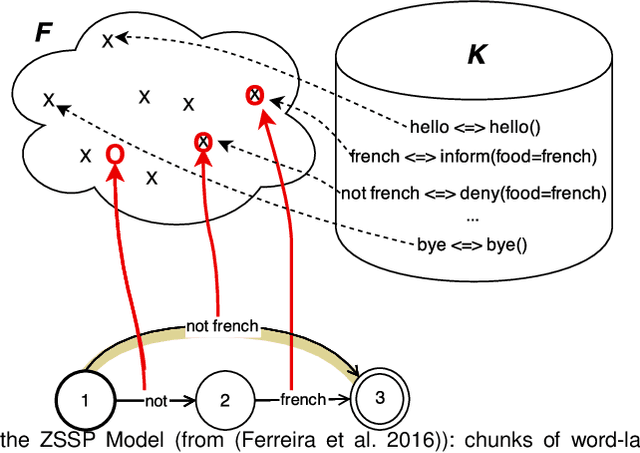
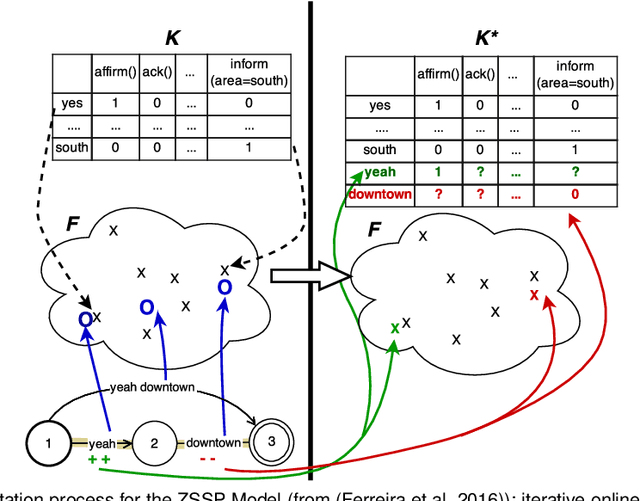

Design of dialogue systems has witnessed many advances lately, yet acquiring huge set of data remains an hindrance to their fast development for a new task or language. Besides, training interactive systems with batch data is not satisfactory. On-line learning is pursued in this paper as a convenient way to alleviate these difficulties. After the system modules are initiated, a single process handles data collection, annotation and use in training algorithms. A new challenge is to control the cost of the on-line learning borne by the user. Our work focuses on learning the semantic parsing and dialogue management modules (speech recognition and synthesis offer ready-for-use solutions). In this context we investigate several variants of simultaneous learning which are tested in user trials. In our experiments, with varying merits, they can all achieve good performance with only a few hundreds of training dialogues and overstep a handcrafted system. The analysis of these experiments gives us some insights, discussed in the paper, into the difficulty for the system's trainers to establish a coherent and constant behavioural strategy to enable a fast and good-quality training phase.
A Multilingual Study of Multi-Sentence Compression using Word Vertex-Labeled Graphs and Integer Linear Programming
Apr 09, 2020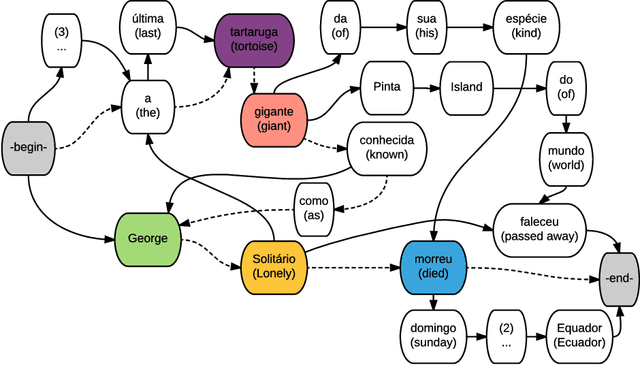
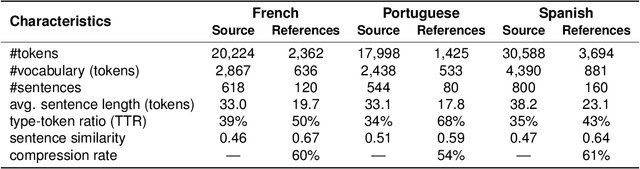
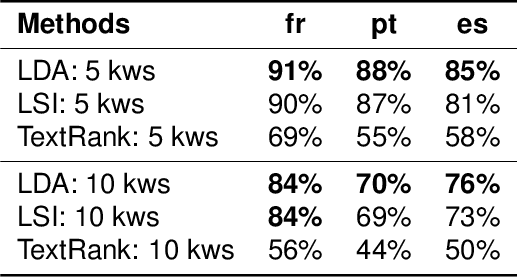
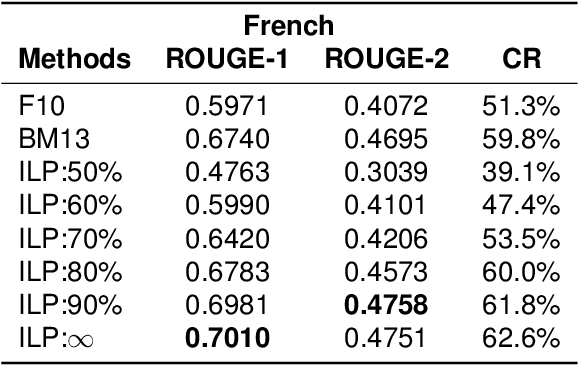
Multi-Sentence Compression (MSC) aims to generate a short sentence with the key information from a cluster of similar sentences. MSC enables summarization and question-answering systems to generate outputs combining fully formed sentences from one or several documents. This paper describes an Integer Linear Programming method for MSC using a vertex-labeled graph to select different keywords, with the goal of generating more informative sentences while maintaining their grammaticality. Our system is of good quality and outperforms the state of the art for evaluations led on news datasets in three languages: French, Portuguese and Spanish. We led both automatic and manual evaluations to determine the informativeness and the grammaticality of compressions for each dataset. In additional tests, which take advantage of the fact that the length of compressions can be modulated, we still improve ROUGE scores with shorter output sentences.
* Preprint version
Predicting the Semantic Textual Similarity with Siamese CNN and LSTM
Oct 24, 2018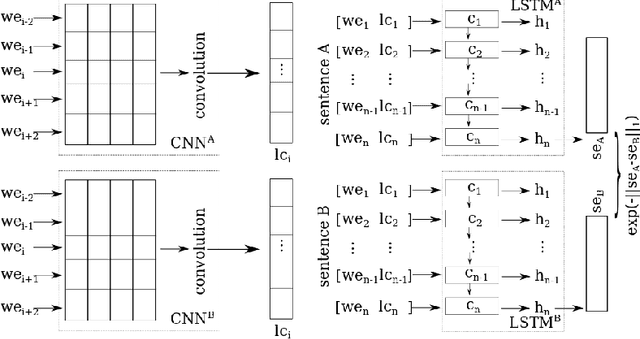
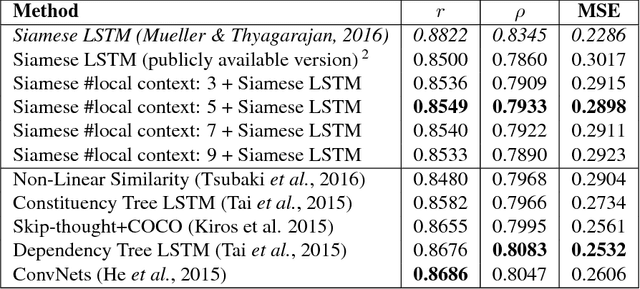
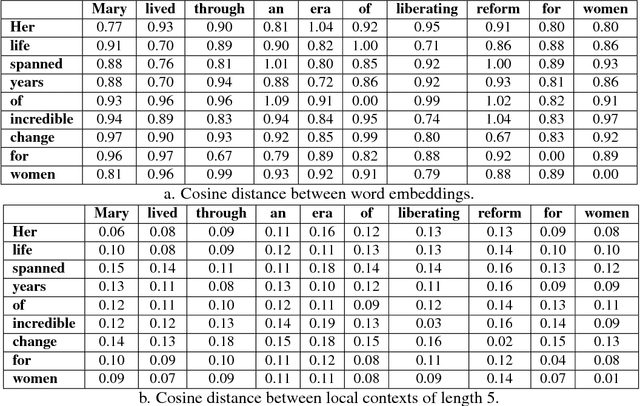
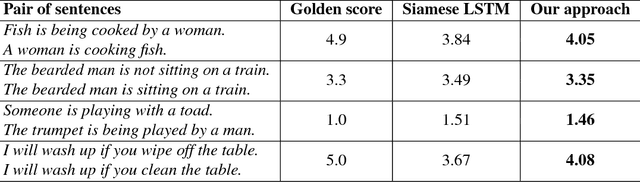
Semantic Textual Similarity (STS) is the basis of many applications in Natural Language Processing (NLP). Our system combines convolution and recurrent neural networks to measure the semantic similarity of sentences. It uses a convolution network to take account of the local context of words and an LSTM to consider the global context of sentences. This combination of networks helps to preserve the relevant information of sentences and improves the calculation of the similarity between sentences. Our model has achieved good results and is competitive with the best state-of-the-art systems.
A Multilingual Study of Compressive Cross-Language Text Summarization
Oct 24, 2018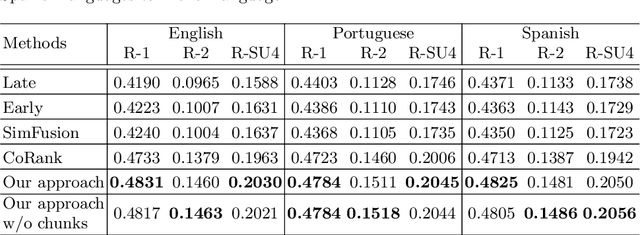

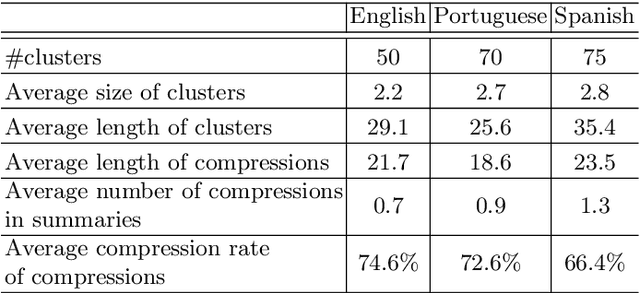
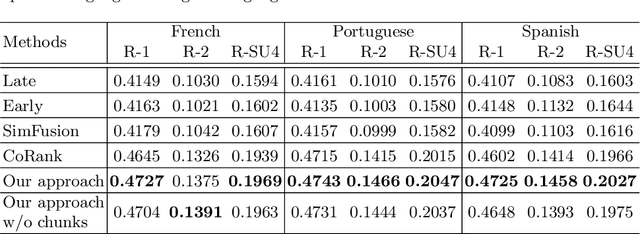
Cross-Language Text Summarization (CLTS) generates summaries in a language different from the language of the source documents. Recent methods use information from both languages to generate summaries with the most informative sentences. However, these methods have performance that can vary according to languages, which can reduce the quality of summaries. In this paper, we propose a compressive framework to generate cross-language summaries. In order to analyze performance and especially stability, we tested our system and extractive baselines on a dataset available in four languages (English, French, Portuguese, and Spanish) to generate English and French summaries. An automatic evaluation showed that our method outperformed extractive state-of-art CLTS methods with better and more stable ROUGE scores for all languages.
Joint On-line Learning of a Zero-shot Spoken Semantic Parser and a Reinforcement Learning Dialogue Manager
Oct 01, 2018
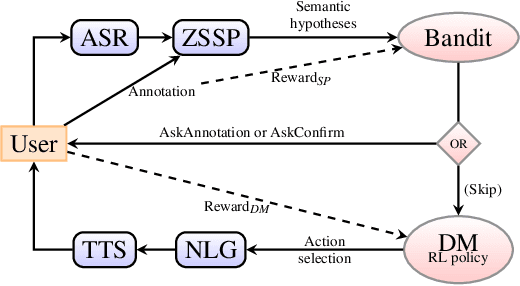
Despite many recent advances for the design of dialogue systems, a true bottleneck remains the acquisition of data required to train its components. Unlike many other language processing applications, dialogue systems require interactions with users, therefore it is complex to develop them with pre-recorded data. Building on previous works, on-line learning is pursued here as a most convenient way to address the issue. Data collection, annotation and use in learning algorithms are performed in a single process. The main difficulties are then: to bootstrap an initial basic system, and to control the level of additional cost on the user side. Considering that well-performing solutions can be used directly off the shelf for speech recognition and synthesis, the study is focused on learning the spoken language understanding and dialogue management modules only. Several variants of joint learning are investigated and tested with user trials to confirm that the overall on-line learning can be obtained after only a few hundred training dialogues and can overstep an expert-based system.
Métodos de Otimização Combinatória Aplicados ao Problema de Compressão MultiFrases
Mar 19, 2017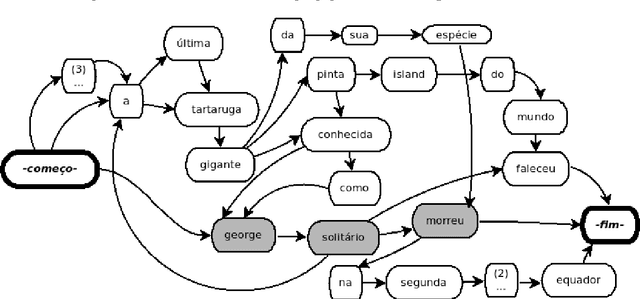



The Internet has led to a dramatic increase in the amount of available information. In this context, reading and understanding this flow of information have become costly tasks. In the last years, to assist people to understand textual data, various Natural Language Processing (NLP) applications based on Combinatorial Optimization have been devised. However, for Multi-Sentences Compression (MSC), method which reduces the sentence length without removing core information, the insertion of optimization methods requires further study to improve the performance of MSC. This article describes a method for MSC using Combinatorial Optimization and Graph Theory to generate more informative sentences while maintaining their grammaticality. An experiment led on a corpus of 40 clusters of sentences shows that our system has achieved a very good quality and is better than the state-of-the-art.
Algorithmes de classification et d'optimisation: participation du LIA/ADOC á DEFT'14
Feb 21, 2017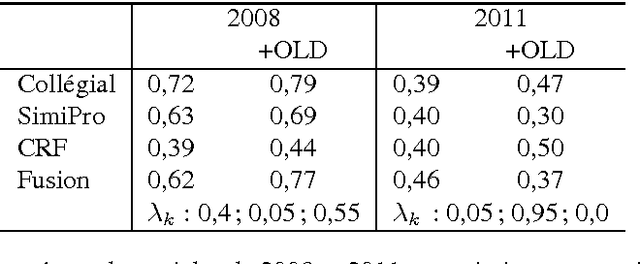

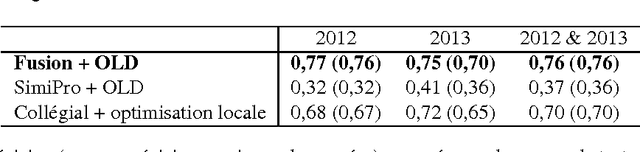
This year, the DEFT campaign (D\'efi Fouilles de Textes) incorporates a task which aims at identifying the session in which articles of previous TALN conferences were presented. We describe the three statistical systems developed at LIA/ADOC for this task. A fusion of these systems enables us to obtain interesting results (micro-precision score of 0.76 measured on the test corpus)
Utilisation de la linguistique en reconnaissance de la parole : un état de l'art
May 30, 2006To transcribe speech, automatic speech recognition systems use statistical methods, particularly hidden Markov model and N-gram models. Although these techniques perform well and lead to efficient systems, they approach their maximum possibilities. It seems thus necessary, in order to outperform current results, to use additional information, especially bound to language. However, introducing such knowledge must be realized taking into account specificities of spoken language (hesitations for example) and being robust to possible misrecognized words. This document presents a state of the art of these researches, evaluating the impact of the insertion of linguistic information on the quality of the transcription.