 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying long legal documents using short random chunks
Dec 31, 2025Classifying legal documents is a challenge, besides their specialized vocabulary, sometimes they can be very long. This means that feeding full documents to a Transformers-based models for classification might be impossible, expensive or slow. Thus, we present a legal document classifier based on DeBERTa V3 and a LSTM, that uses as input a collection of 48 randomly-selected short chunks (max 128 tokens). Besides, we present its deployment pipeline using Temporal, a durable execution solution, which allow us to have a reliable and robust processing workflow. The best model had a weighted F-score of 0.898, while the pipeline running on CPU had a processing median time of 498 seconds per 100 files.
Algorithmes de classification et d'optimisation: participation du LIA/ADOC á DEFT'14
Feb 21, 2017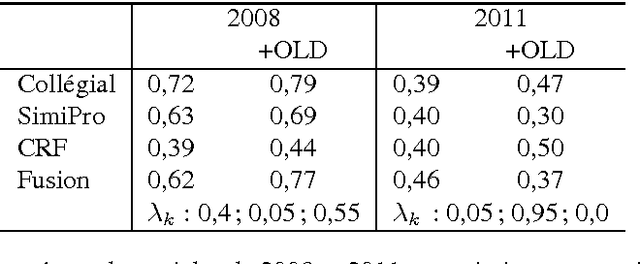

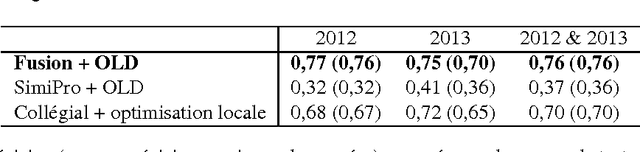
This year, the DEFT campaign (D\'efi Fouilles de Textes) incorporates a task which aims at identifying the session in which articles of previous TALN conferences were presented. We describe the three statistical systems developed at LIA/ADOC for this task. A fusion of these systems enables us to obtain interesting results (micro-precision score of 0.76 measured on the test corpus)
Systèmes du LIA à DEFT'13
Feb 21, 2017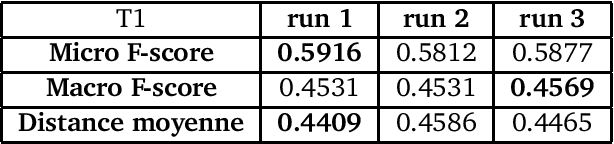


The 2013 D\'efi de Fouille de Textes (DEFT) campaign is interested in two types of language analysis tasks, the document classification and the information extraction in the specialized domain of cuisine recipes. We present the systems that the LIA has used in DEFT 2013. Our systems show interesting results, even though the complexity of the proposed tasks.
* 12 pages, 3 tables, (Paper in French)