 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive learning in annotating micro-blogs dealing with e-reputation
Sep 25, 2017



Elections unleash strong political views on Twitter, but what do people really think about politics? Opinion and trend mining on micro blogs dealing with politics has recently attracted researchers in several fields including Information Retrieval and Machine Learning (ML). Since the performance of ML and Natural Language Processing (NLP) approaches are limited by the amount and quality of data available, one promising alternative for some tasks is the automatic propagation of expert annotations. This paper intends to develop a so-called active learning process for automatically annotating French language tweets that deal with the image (i.e., representation, web reputation) of politicians. Our main focus is on the methodology followed to build an original annotated dataset expressing opinion from two French politicians over time. We therefore review state of the art NLP-based ML algorithms to automatically annotate tweets using a manual initiation step as bootstrap. This paper focuses on key issues about active learning while building a large annotated data set from noise. This will be introduced by human annotators, abundance of data and the label distribution across data and entities. In turn, we show that Twitter characteristics such as the author's name or hashtags can be considered as the bearing point to not only improve automatic systems for Opinion Mining (OM) and Topic Classification but also to reduce noise in human annotations. However, a later thorough analysis shows that reducing noise might induce the loss of crucial information.
* Journal of Interdisciplinary Methodologies and Issues in Science - Vol 3 - Contextualisation digitale - 2017
Systèmes du LIA à DEFT'13
Feb 21, 2017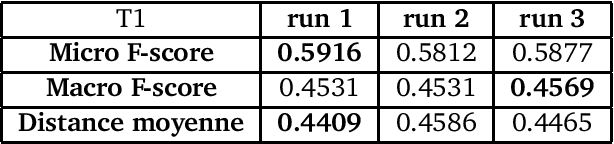


The 2013 D\'efi de Fouille de Textes (DEFT) campaign is interested in two types of language analysis tasks, the document classification and the information extraction in the specialized domain of cuisine recipes. We present the systems that the LIA has used in DEFT 2013. Our systems show interesting results, even though the complexity of the proposed tasks.
* 12 pages, 3 tables, (Paper in French)
A Review of Features for the Discrimination of Twitter Users: Application to the Prediction of Offline Influence
Jul 29, 2016



Many works related to Twitter aim at characterizing its users in some way: role on the service (spammers, bots, organizations, etc.), nature of the user (socio-professional category, age, etc.), topics of interest , and others. However, for a given user classification problem, it is very difficult to select a set of appropriate features, because the many features described in the literature are very heterogeneous, with name overlaps and collisions, and numerous very close variants. In this article, we review a wide range of such features. In order to present a clear state-of-the-art description, we unify their names, definitions and relationships, and we propose a new, neutral, typology. We then illustrate the interest of our review by applying a selection of these features to the offline influence detection problem. This task consists in identifying users which are influential in real-life, based on their Twitter account and related data. We show that most features deemed efficient to predict online influence, such as the numbers of retweets and followers, are not relevant to this problem. However, We propose several content-based approaches to label Twitter users as Influencers or not. We also rank them according to a predicted influence level. Our proposals are evaluated over the CLEF RepLab 2014 dataset, and outmatch state-of-the-art methods.
How to merge three different methods for information filtering ?
Oct 26, 2015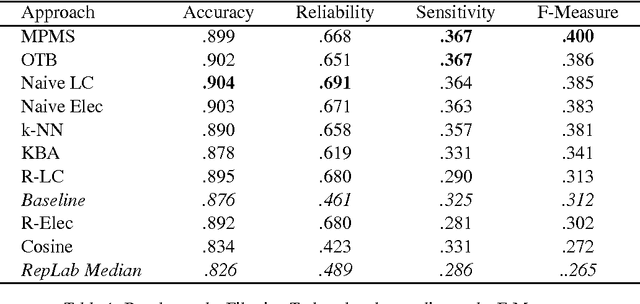
Twitter is now a gold marketing tool for entities concerned with online reputation. To automatically monitor online reputation of entities , systems have to deal with ambiguous entity names, polarity detection and topic detection. We propose three approaches to tackle the first issue: monitoring Twitter in order to find relevant tweets about a given entity. Evaluated within the framework of the RepLab-2013 Filtering task, each of them has been shown competitive with state-of-the-art approaches. Mainly we investigate on how much merging strategies may impact performances on a filtering task according to the evaluation measure.