 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Numbers Tell Half the Story: Human-Metric Alignment in Topic Model Evaluation
Mar 02, 2026Topic models uncover latent thematic structures in text corpora, yet evaluating their quality remains challenging, particularly in specialized domains. Existing methods often rely on automated metrics like topic coherence and diversity, which may not fully align with human judgment. Human evaluation tasks, such as word intrusion, provide valuable insights but are costly and primarily validated on general-domain corpora. This paper introduces Topic Word Mixing (TWM), a novel human evaluation task assessing inter-topic distinctness by testing whether annotators can distinguish between word sets from single or mixed topics. TWM complements word intrusion's focus on intra-topic coherence and provides a human-grounded counterpart to diversity metrics. We evaluate six topic models - both statistical and embedding-based (LDA, NMF, Top2Vec, BERTopic, CFMF, CFMF-emb) - comparing automated metrics with human evaluation methods based on nearly 4,000 annotations from a domain-specific corpus of philosophy of science publications. Our findings reveal that word intrusion and coherence metrics do not always align, particularly in specialized domains, and that TWM captures human-perceived distinctness while appearing to align with diversity metrics. We release the annotated dataset and task generation code. This work highlights the need for evaluation frameworks bridging automated and human assessments, particularly for domain-specific corpora.
From communities to interpretable network and word embedding: an unified approach
Dec 11, 2024Modelling information from complex systems such as humans social interaction or words co-occurrences in our languages can help to understand how these systems are organized and function. Such systems can be modelled by networks, and network theory provides a useful set of methods to analyze them. Among these methods, graph embedding is a powerful tool to summarize the interactions and topology of a network in a vectorized feature space. When used in input of machine learning algorithms, embedding vectors help with common graph problems such as link prediction, graph matching, etc. Word embedding has the goal of representing the sense of words, extracting it from large text corpora. Despite differences in the structure of information in input of embedding algorithms, many graph embedding approaches are adapted and inspired from methods in NLP. Limits of these methods are observed in both domains. Most of these methods require long and resource greedy training. Another downside to most methods is that they are black-box, from which understanding how the information is structured is rather complex. Interpretability of a model allows understanding how the vector space is structured without the need for external information, and thus can be audited more easily. With both these limitations in mind, we propose a novel framework to efficiently embed network vertices in an interpretable vector space. Our Lower Dimension Bipartite Framework (LDBGF) leverages the bipartite projection of a network using cliques to reduce dimensionality. Along with LDBGF, we introduce two implementations of this framework that rely on communities instead of cliques: SINr-NR and SINr-MF. We show that SINr-MF can perform well on classical graphs and SINr-NR can produce high-quality graph and word embeddings that are interpretable and stable across runs.
Complex networks based word embeddings
Oct 03, 2019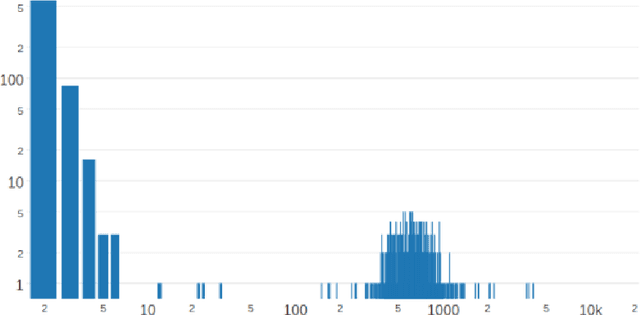
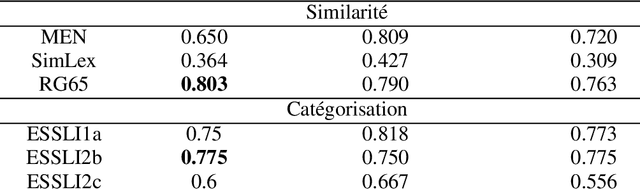
Most of the time, the first step to learn word embeddings is to build a word co-occurrence matrix. As such matrices are equivalent to graphs, complex networks theory can naturally be used to deal with such data. In this paper, we consider applying community detection, a main tool of this field, to the co-occurrence matrix corresponding to a huge corpus. Community structure is used as a way to reduce the dimensionality of the initial space. Using this community structure, we propose a method to extract word embeddings that are comparable to the state-of-the-art approaches.
A Review of Features for the Discrimination of Twitter Users: Application to the Prediction of Offline Influence
Jul 29, 2016



Many works related to Twitter aim at characterizing its users in some way: role on the service (spammers, bots, organizations, etc.), nature of the user (socio-professional category, age, etc.), topics of interest , and others. However, for a given user classification problem, it is very difficult to select a set of appropriate features, because the many features described in the literature are very heterogeneous, with name overlaps and collisions, and numerous very close variants. In this article, we review a wide range of such features. In order to present a clear state-of-the-art description, we unify their names, definitions and relationships, and we propose a new, neutral, typology. We then illustrate the interest of our review by applying a selection of these features to the offline influence detection problem. This task consists in identifying users which are influential in real-life, based on their Twitter account and related data. We show that most features deemed efficient to predict online influence, such as the numbers of retweets and followers, are not relevant to this problem. However, We propose several content-based approaches to label Twitter users as Influencers or not. We also rank them according to a predicted influence level. Our proposals are evaluated over the CLEF RepLab 2014 dataset, and outmatch state-of-the-art methods.