 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple topic identification in telephone conversations
Dec 29, 2018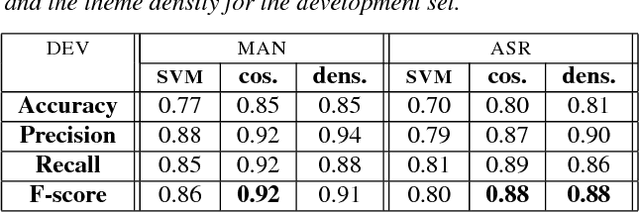
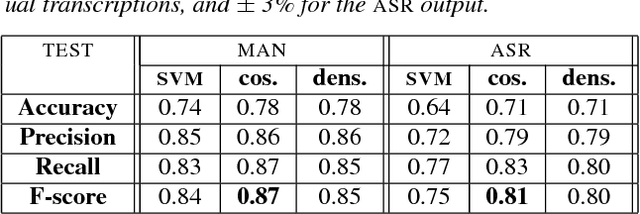
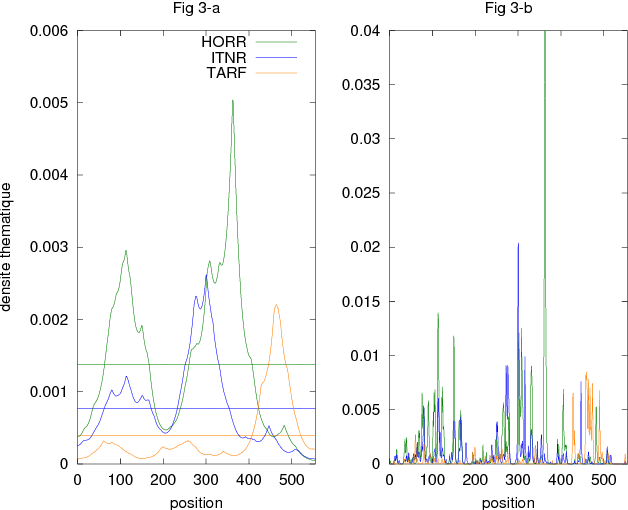
This paper deals with the automatic analysis of conversations between a customer and an agent in a call centre of a customer care service. The purpose of the analysis is to hypothesize themes about problems and complaints discussed in the conversation. Themes are defined by the application documentation topics. A conversation may contain mentions that are irrelevant for the application purpose and multiple themes whose mentions may be interleaved portions of a conversation that cannot be well defined. Two methods are proposed for multiple theme hypothesization. One of them is based on a cosine similarity measure using a bag of features extracted from the entire conversation. The other method introduces the concept of thematic density distributed around specific word positions in a conversation. In addition to automatically selected words, word bi-grams with possible gaps between successive words are also considered and selected. Experimental results show that the results obtained with the proposed methods outperform the results obtained with support vector machines on the same data. Furthermore, using the theme skeleton of a conversation from which thematic densities are derived, it will be possible to extract components of an automatic conversation report to be used for improving the service performance. Index Terms: multi-topic audio document classification, hu-man/human conversation analysis, speech analytics, distance bigrams
* arXiv admin note: text overlap with arXiv:1812.07207
How to merge three different methods for information filtering ?
Oct 26, 2015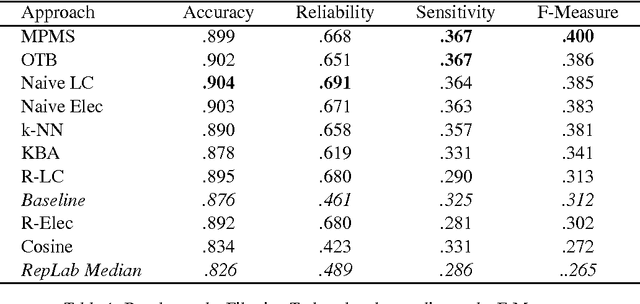
Twitter is now a gold marketing tool for entities concerned with online reputation. To automatically monitor online reputation of entities , systems have to deal with ambiguous entity names, polarity detection and topic detection. We propose three approaches to tackle the first issue: monitoring Twitter in order to find relevant tweets about a given entity. Evaluated within the framework of the RepLab-2013 Filtering task, each of them has been shown competitive with state-of-the-art approaches. Mainly we investigate on how much merging strategies may impact performances on a filtering task according to the evaluation measure.