 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization Strategies in Multi-Task Learning: Averaged or Independent Losses?
Oct 04, 2021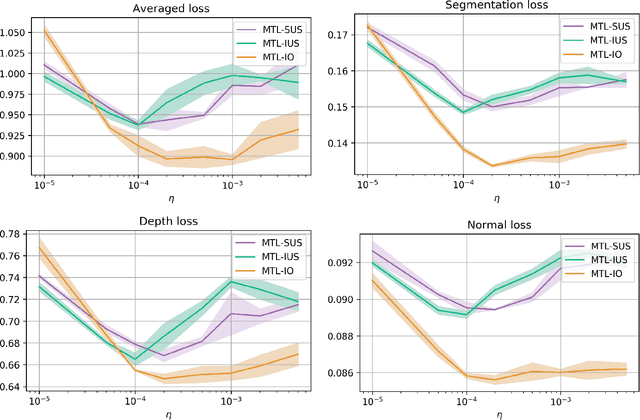
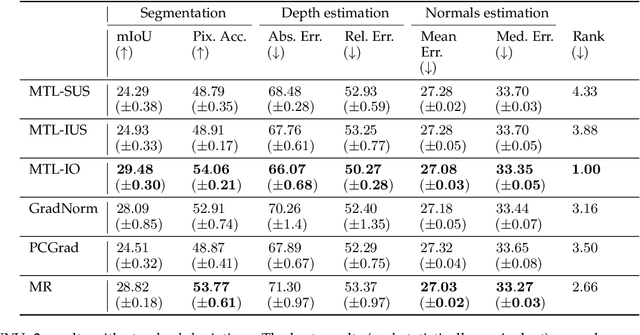
In Multi-Task Learning (MTL), it is a common practice to train multi-task networks by optimizing an objective function, which is a weighted average of the task-specific objective functions. Although the computational advantages of this strategy are clear, the complexity of the resulting loss landscape has not been studied in the literature. Arguably, its optimization may be more difficult than a separate optimization of the constituting task-specific objectives. In this work, we investigate the benefits of such an alternative, by alternating independent gradient descent steps on the different task-specific objective functions and we formulate a novel way to combine this approach with state-of-the-art optimizers. As the separation of task-specific objectives comes at the cost of increased computational time, we propose a random task grouping as a trade-off between better optimization and computational efficiency. Experimental results over three well-known visual MTL datasets show better overall absolute performance on losses and standard metrics compared to an averaged objective function and other state-of-the-art MTL methods. In particular, our method shows the most benefits when dealing with tasks of different nature and it enables a wider exploration of the shared parameter space. We also show that our random grouping strategy allows to trade-off between these benefits and computational efficiency.
Maximum Roaming Multi-Task Learning
Jun 17, 2020
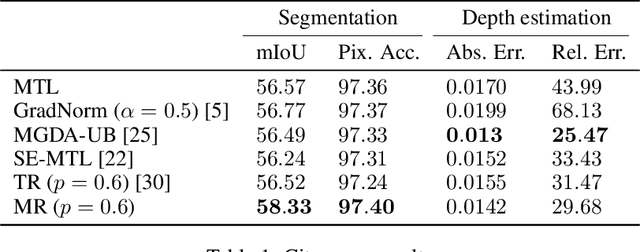
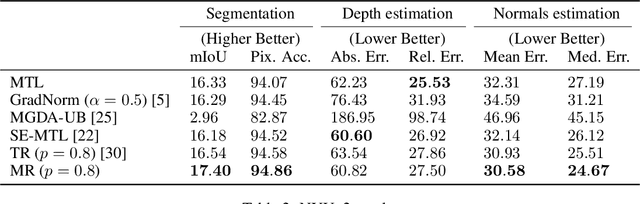
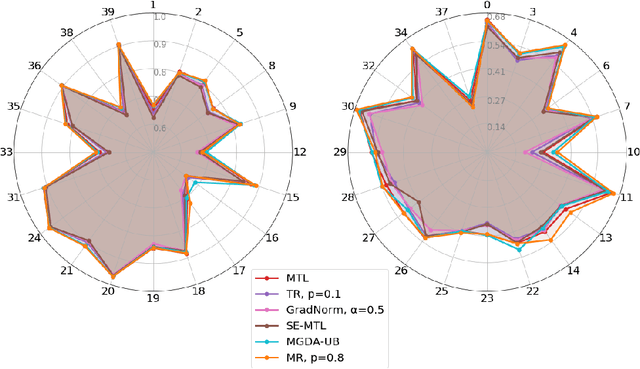
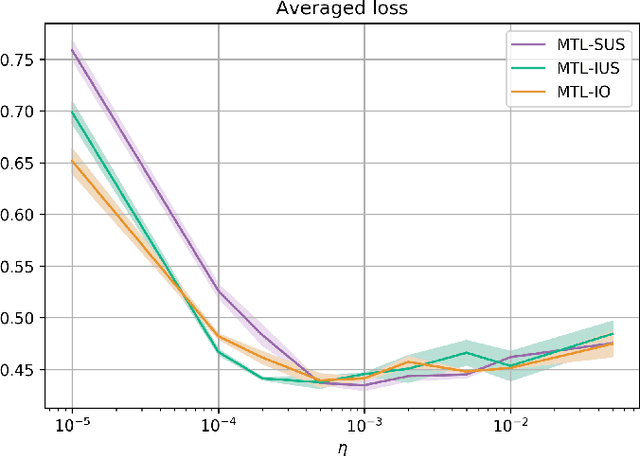
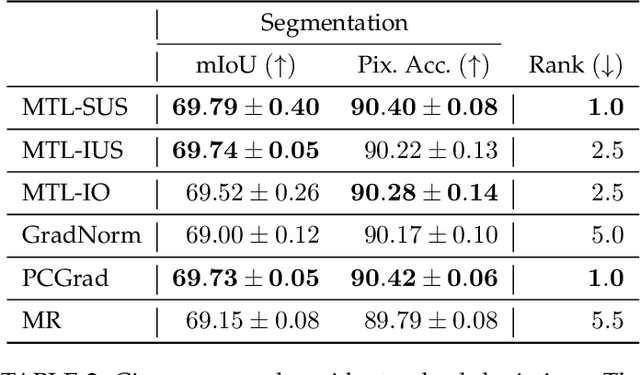
Multi-task learning has gained popularity due to the advantages it provides with respect to resource usage and performance. Nonetheless, the joint optimization of parameters with respect to multiple tasks remains an active research topic. Sub-partitioning the parameters between different tasks has proven to be an efficient way to relax the optimization constraints over the shared weights, may the partitions be disjoint or overlapping. However, one drawback of this approach is that it can weaken the inductive bias generally set up by the joint task optimization. In this work, we present a novel way to partition the parameter space without weakening the inductive bias. Specifically, we propose Maximum Roaming, a method inspired by dropout that randomly varies the parameter partitioning, while forcing them to visit as many tasks as possible at a regulated frequency, so that the network fully adapts to each update. We study the properties of our method through experiments on a variety of visual multi-task data sets. Experimental results suggest that the regularization brought by roaming has more impact on performance than usual partitioning optimization strategies. The overall method is flexible, easily applicable, provides superior regularization and consistently achieves improved performances compared to recent multi-task learning formulations.
Semantic and Visual Similarities for Efficient Knowledge Transfer in CNN Training
Sep 13, 2019
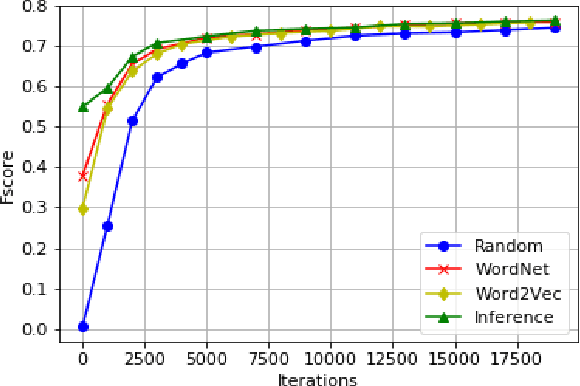
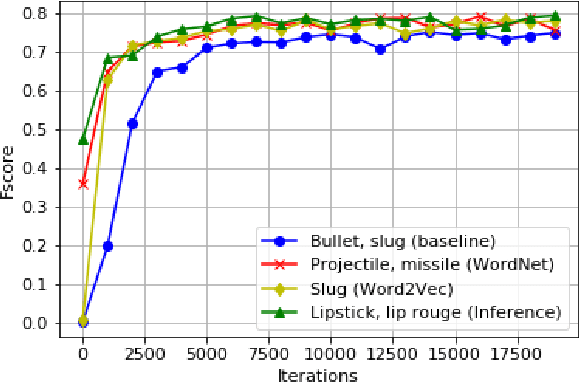
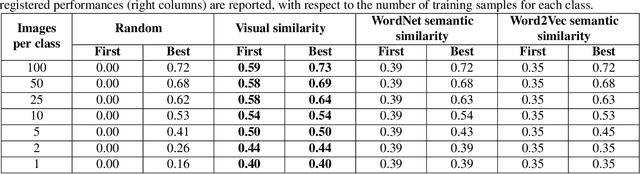
In recent years, representation learning approaches have disrupted many multimedia computing tasks. Among those approaches, deep convolutional neural networks (CNNs) have notably reached human level expertise on some constrained image classification tasks. Nonetheless, training CNNs from scratch for new task or simply new data turns out to be complex and time-consuming. Recently, transfer learning has emerged as an effective methodology for adapting pre-trained CNNs to new data and classes, by only retraining the last classification layer. This paper focuses on improving this process, in order to better transfer knowledge between CNN architectures for faster trainings in the case of fine tuning for image classification. This is achieved by combining and transfering supplementary weights, based on similarity considerations between source and target classes. The study includes a comparison between semantic and content-based similarities, and highlights increased initial performances and training speed, along with superior long term performances when limited training samples are available.
Extraction and Analysis of Fictional Character Networks: A Survey
Jul 05, 2019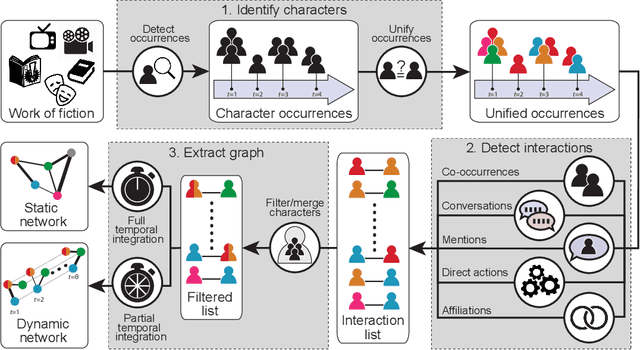
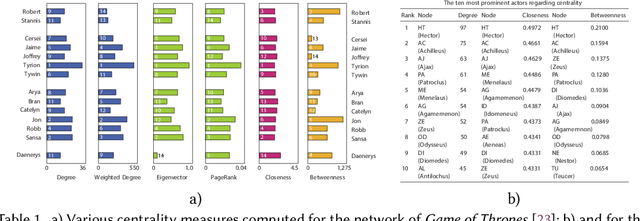

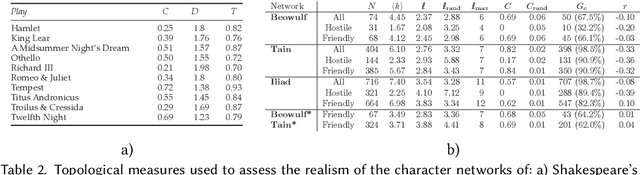
A character network is a graph extracted from a narrative, in which vertices represent characters and edges correspond to interactions between them. A number of narrative-related problems can be addressed automatically through the analysis of character networks, such as summarization, classification, or role detection. Character networks are particularly relevant when considering works of fictions (e.g. novels, plays, movies, TV series), as their exploitation allows developing information retrieval and recommendation systems. However, works of fiction possess specific properties making these tasks harder. This survey aims at presenting and organizing the scientific literature related to the extraction of character networks from works of fiction, as well as their analysis. We first describe the extraction process in a generic way, and explain how its constituting steps are implemented in practice, depending on the medium of the narrative, the goal of the network analysis, and other factors. We then review the descriptive tools used to characterize character networks, with a focus on the way they are interpreted in this context. We illustrate the relevance of character networks by also providing a review of applications derived from their analysis. Finally, we identify the limitations of the existing approaches, and the most promising perspectives.
M2H-GAN: A GAN-based Mapping from Machine to Human Transcripts for Speech Understanding
Apr 13, 2019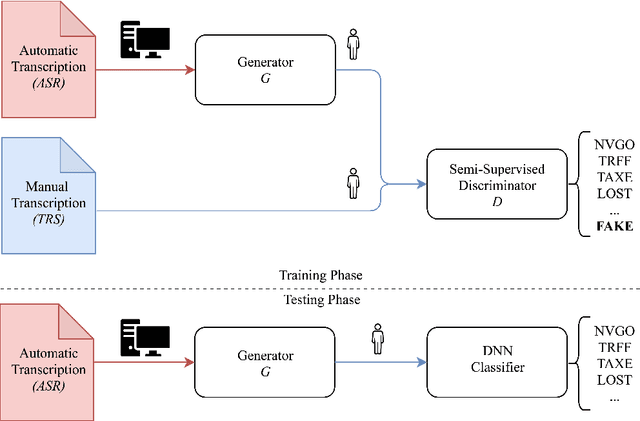
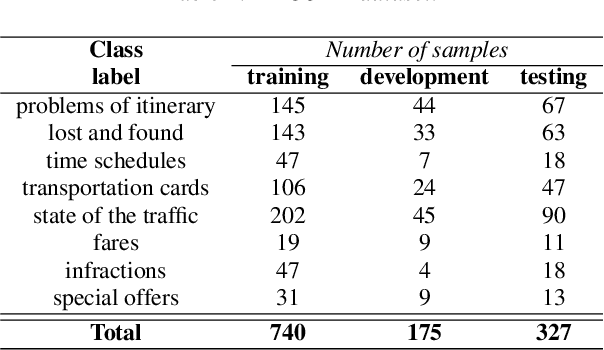
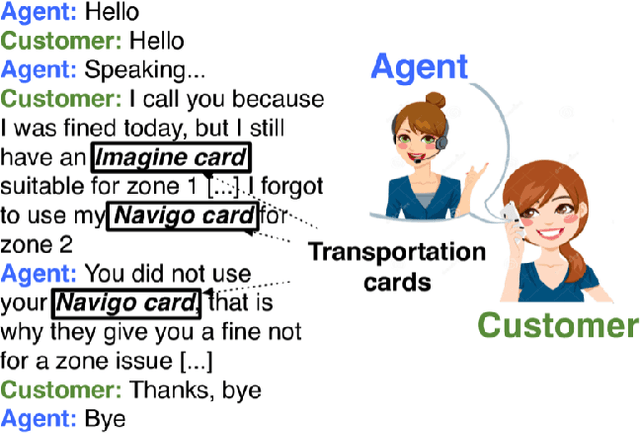
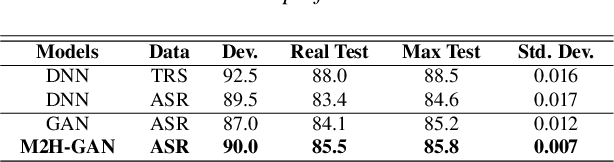
Deep learning is at the core of recent spoken language understanding (SLU) related tasks. More precisely, deep neural networks (DNNs) drastically increased the performances of SLU systems, and numerous architectures have been proposed. In the real-life context of theme identification of telephone conversations, it is common to hold both a human, manual (TRS) and an automatically transcribed (ASR) versions of the conversations. Nonetheless, and due to production constraints, only the ASR transcripts are considered to build automatic classifiers. TRS transcripts are only used to measure the performances of ASR systems. Moreover, the recent performances in term of classification accuracy, obtained by DNN related systems are close to the performances reached by humans, and it becomes difficult to further increase the performances by only considering the ASR transcripts. This paper proposes to distillates the TRS knowledge available during the training phase within the ASR representation, by using a new generative adversarial network called M2H-GAN to generate a TRS-like version of an ASR document, to improve the theme identification performances.
Multiple topic identification in telephone conversations
Dec 29, 2018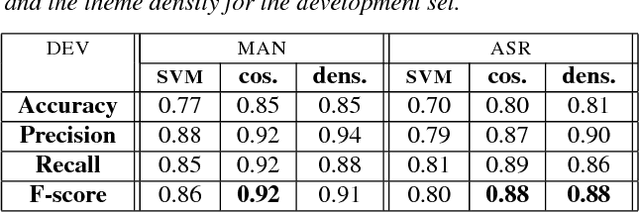
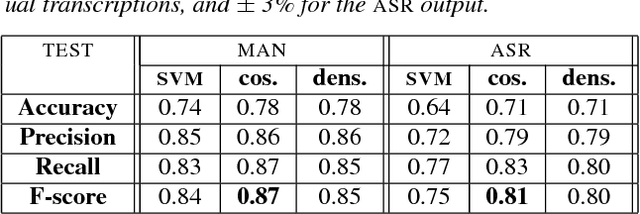
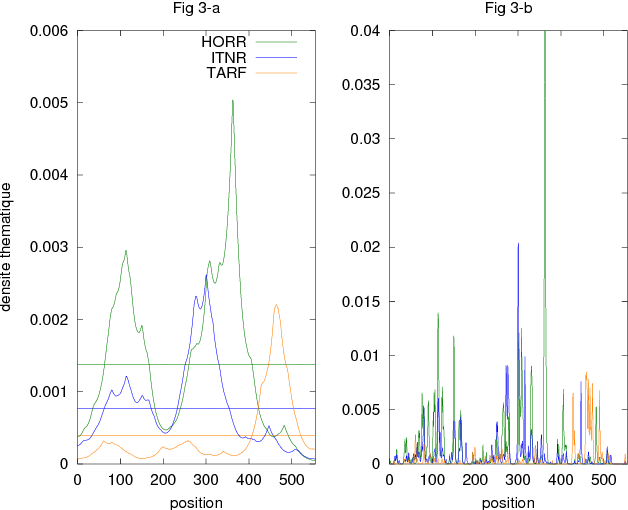
This paper deals with the automatic analysis of conversations between a customer and an agent in a call centre of a customer care service. The purpose of the analysis is to hypothesize themes about problems and complaints discussed in the conversation. Themes are defined by the application documentation topics. A conversation may contain mentions that are irrelevant for the application purpose and multiple themes whose mentions may be interleaved portions of a conversation that cannot be well defined. Two methods are proposed for multiple theme hypothesization. One of them is based on a cosine similarity measure using a bag of features extracted from the entire conversation. The other method introduces the concept of thematic density distributed around specific word positions in a conversation. In addition to automatically selected words, word bi-grams with possible gaps between successive words are also considered and selected. Experimental results show that the results obtained with the proposed methods outperform the results obtained with support vector machines on the same data. Furthermore, using the theme skeleton of a conversation from which thematic densities are derived, it will be possible to extract components of an automatic conversation report to be used for improving the service performance. Index Terms: multi-topic audio document classification, hu-man/human conversation analysis, speech analytics, distance bigrams
* arXiv admin note: text overlap with arXiv:1812.07207
Constrained speaker diarization of TV series based on visual patterns
Dec 29, 2018


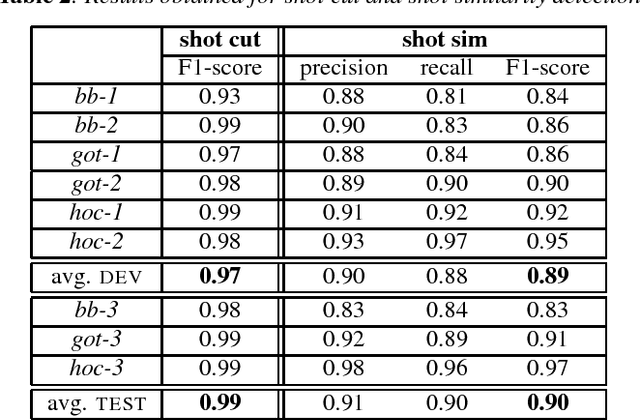
Speaker diarization, usually denoted as the ''who spoke when'' task, turns out to be particularly challenging when applied to fictional films, where many characters talk in various acoustic conditions (background music, sound effects...). Despite this acoustic variability , such movies exhibit specific visual patterns in the dialogue scenes. In this paper, we introduce a two-step method to achieve speaker diarization in TV series: a speaker diarization is first performed locally in the scenes detected as dialogues; then, the hypothesized local speakers are merged in a second agglomerative clustering process, with the constraint that speakers locally hypothesized to be distinct must not be assigned to the same cluster. The performances of our approach are compared to those obtained by standard speaker diarization tools applied to the same data.
Audiovisual speaker diarization of TV series
Dec 29, 2018



Speaker diarization may be difficult to achieve when applied to narrative films, where speakers usually talk in adverse acoustic conditions: background music, sound effects, wide variations in intonation may hide the inter-speaker variability and make audio-based speaker diarization approaches error prone. On the other hand, such fictional movies exhibit strong regularities at the image level, particularly within dialogue scenes. In this paper, we propose to perform speaker diarization within dialogue scenes of TV series by combining the audio and video modalities: speaker diarization is first performed by using each modality, the two resulting partitions of the instance set are then optimally matched, before the remaining instances, corresponding to cases of disagreement between both modalities, are finally processed. The results obtained by applying such a multi-modal approach to fictional films turn out to outperform those obtained by relying on a single modality.
D{é}tection de locuteurs dans les s{é}ries TV
Dec 18, 2018

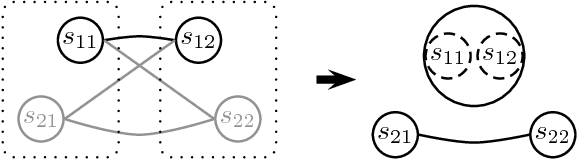
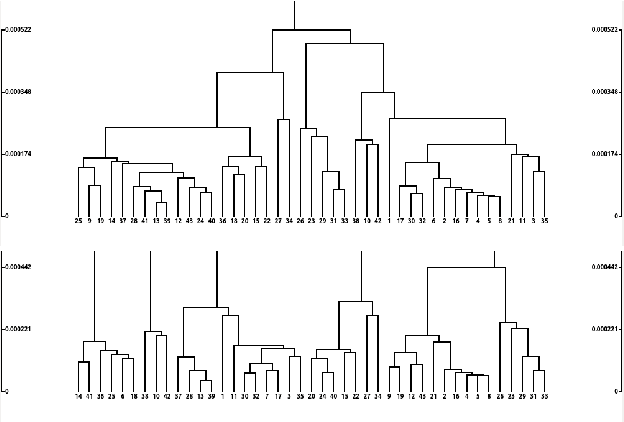
Speaker diarization of audio streams turns out to be particularly challenging when applied to fictional films, where many characters talk in various acoustic conditions (background music, sound effects, variations in intonation...). Despite this acoustic variability, such movies exhibit specific visual patterns, particularly within dialogue scenes. In this paper, we introduce a two-step method to achieve speaker diarization in TV series: speaker diarization is first performed locally within scenes visually identified as dialogues; then, the hypothesized local speakers are compared to each other during a second clustering process in order to detect recurring speakers: this second stage of clustering is subject to the constraint that the different speakers involved in the same dialogue have to be assigned to different clusters. The performances of our approach are compared to those obtained by standard speaker diarization tools applied to the same data.
* in French
Systèmes du LIA à DEFT'13
Feb 21, 2017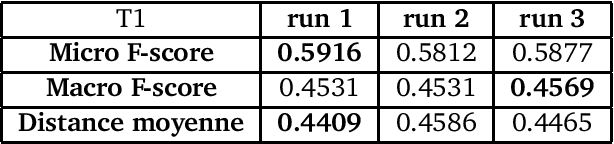


The 2013 D\'efi de Fouille de Textes (DEFT) campaign is interested in two types of language analysis tasks, the document classification and the information extraction in the specialized domain of cuisine recipes. We present the systems that the LIA has used in DEFT 2013. Our systems show interesting results, even though the complexity of the proposed tasks.
* 12 pages, 3 tables, (Paper in French)