 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuaternion Neural Networks for Multi-channel Distant Speech Recognition
May 19, 2020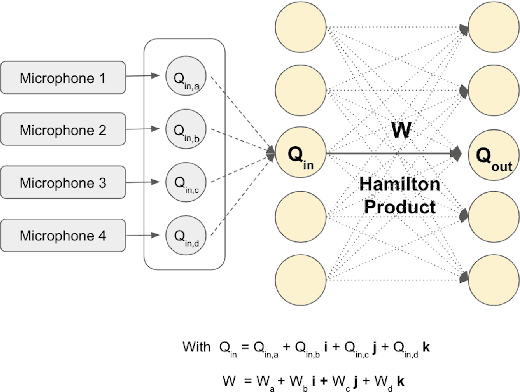

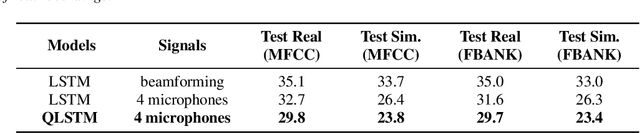
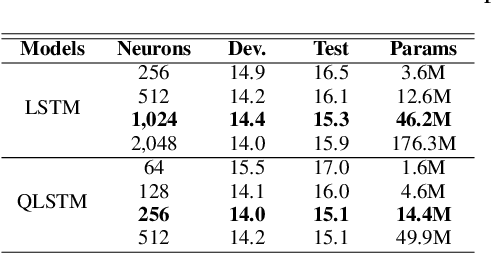
Despite the significant progress in automatic speech recognition (ASR), distant ASR remains challenging due to noise and reverberation. A common approach to mitigate this issue consists of equipping the recording devices with multiple microphones that capture the acoustic scene from different perspectives. These multi-channel audio recordings contain specific internal relations between each signal. In this paper, we propose to capture these inter- and intra- structural dependencies with quaternion neural networks, which can jointly process multiple signals as whole quaternion entities. The quaternion algebra replaces the standard dot product with the Hamilton one, thus offering a simple and elegant way to model dependencies between elements. The quaternion layers are then coupled with a recurrent neural network, which can learn long-term dependencies in the time domain. We show that a quaternion long-short term memory neural network (QLSTM), trained on the concatenated multi-channel speech signals, outperforms equivalent real-valued LSTM on two different tasks of multi-channel distant speech recognition.
Real to H-space Encoder for Speech Recognition
Jun 17, 2019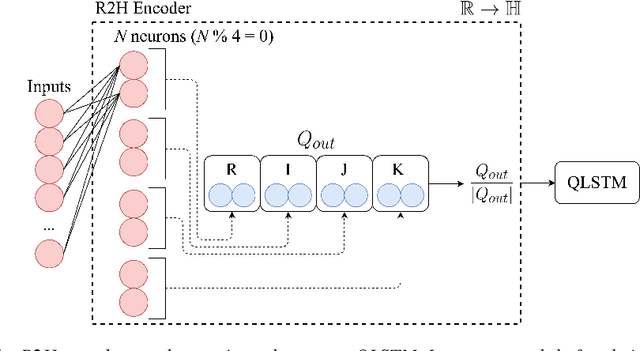
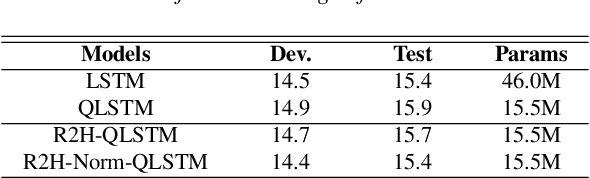
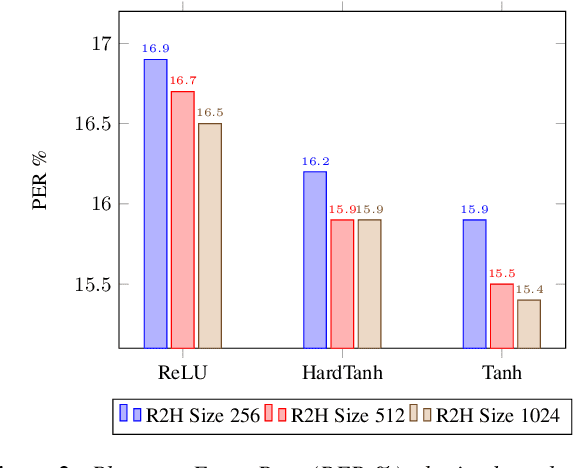
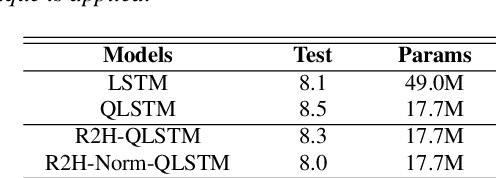
Deep neural networks (DNNs) and more precisely recurrent neural networks (RNNs) are at the core of modern automatic speech recognition systems, due to their efficiency to process input sequences. Recently, it has been shown that different input representations, based on multidimensional algebras, such as complex and quaternion numbers, are able to bring to neural networks a more natural, compressive and powerful representation of the input signal by outperforming common real-valued NNs. Indeed, quaternion-valued neural networks (QNNs) better learn both internal dependencies, such as the relation between the Mel-filter-bank value of a specific time frame and its time derivatives, and global dependencies, describing the relations that exist between time frames. Nonetheless, QNNs are limited to quaternion-valued input signals, and it is difficult to benefit from this powerful representation with real-valued input data. This paper proposes to tackle this weakness by introducing a real-to-quaternion encoder that allows QNNs to process any one dimensional input features, such as traditional Mel-filter-banks for automatic speech recognition.
M2H-GAN: A GAN-based Mapping from Machine to Human Transcripts for Speech Understanding
Apr 13, 2019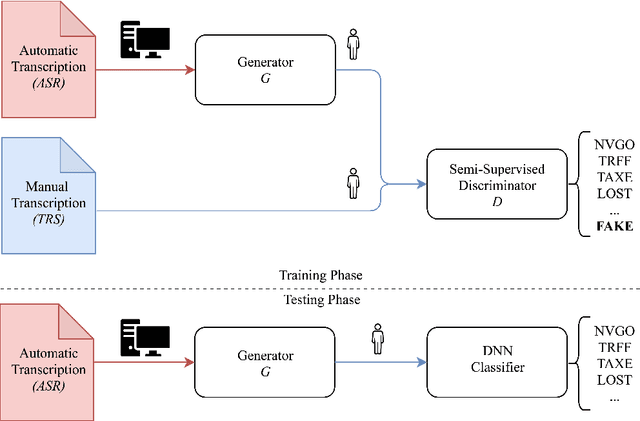
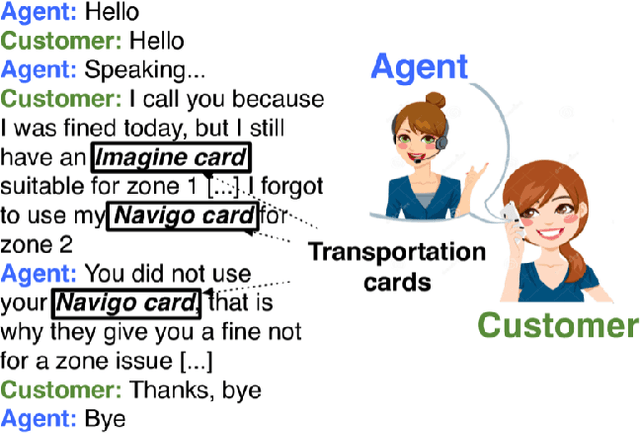
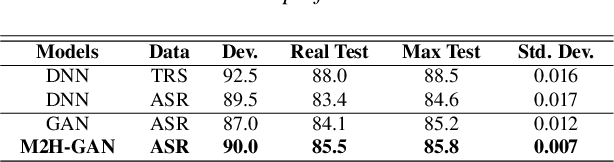
Deep learning is at the core of recent spoken language understanding (SLU) related tasks. More precisely, deep neural networks (DNNs) drastically increased the performances of SLU systems, and numerous architectures have been proposed. In the real-life context of theme identification of telephone conversations, it is common to hold both a human, manual (TRS) and an automatically transcribed (ASR) versions of the conversations. Nonetheless, and due to production constraints, only the ASR transcripts are considered to build automatic classifiers. TRS transcripts are only used to measure the performances of ASR systems. Moreover, the recent performances in term of classification accuracy, obtained by DNN related systems are close to the performances reached by humans, and it becomes difficult to further increase the performances by only considering the ASR transcripts. This paper proposes to distillates the TRS knowledge available during the training phase within the ASR representation, by using a new generative adversarial network called M2H-GAN to generate a TRS-like version of an ASR document, to improve the theme identification performances.
Speech recognition with quaternion neural networks
Nov 21, 2018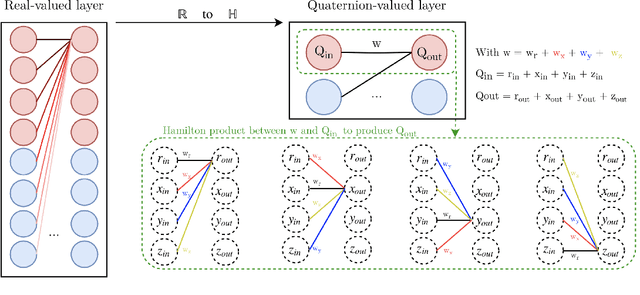
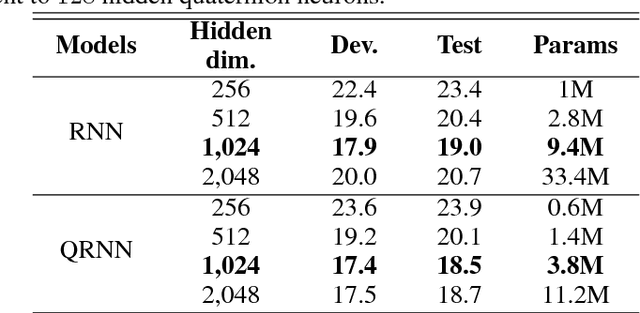
Neural network architectures are at the core of powerful automatic speech recognition systems (ASR). However, while recent researches focus on novel model architectures, the acoustic input features remain almost unchanged. Traditional ASR systems rely on multidimensional acoustic features such as the Mel filter bank energies alongside with the first, and second order derivatives to characterize time-frames that compose the signal sequence. Considering that these components describe three different views of the same element, neural networks have to learn both the internal relations that exist within these features, and external or global dependencies that exist between the time-frames. Quaternion-valued neural networks (QNN), recently received an important interest from researchers to process and learn such relations in multidimensional spaces. Indeed, quaternion numbers and QNNs have shown their efficiency to process multidimensional inputs as entities, to encode internal dependencies, and to solve many tasks with up to four times less learning parameters than real-valued models. We propose to investigate modern quaternion-valued models such as convolutional and recurrent quaternion neural networks in the context of speech recognition with the TIMIT dataset. The experiments show that QNNs always outperform real-valued equivalent models with way less free parameters, leading to a more efficient, compact, and expressive representation of the relevant information.
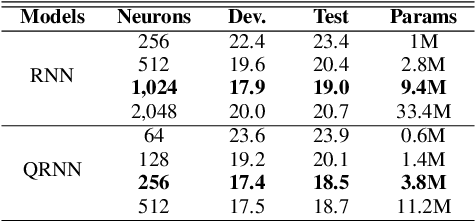
Bidirectional Quaternion Long-Short Term Memory Recurrent Neural Networks for Speech Recognition
Nov 06, 2018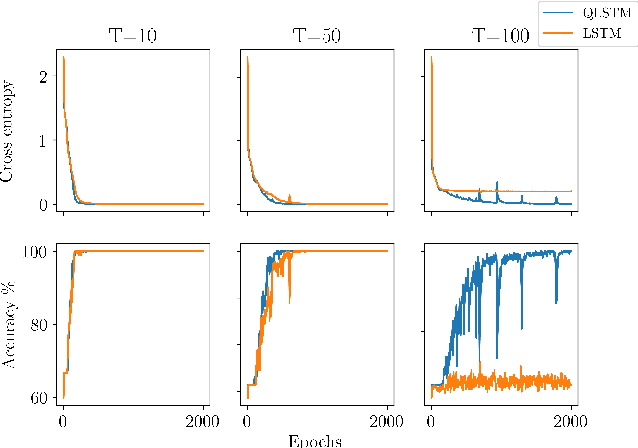
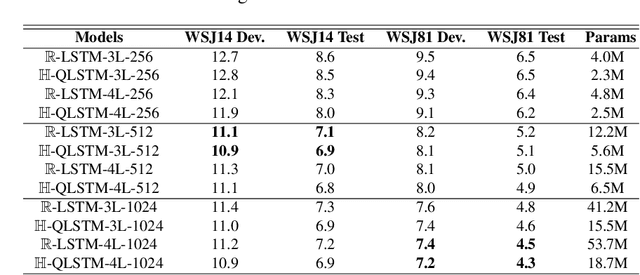
Recurrent neural networks (RNN) are at the core of modern automatic speech recognition (ASR) systems. In particular, long-short term memory (LSTM) recurrent neural networks have achieved state-of-the-art results in many speech recognition tasks, due to their efficient representation of long and short term dependencies in sequences of inter-dependent features. Nonetheless, internal dependencies within the element composing multidimensional features are weakly considered by traditional real-valued representations. We propose a novel quaternion long-short term memory (QLSTM) recurrent neural network that takes into account both the external relations between the features composing a sequence, and these internal latent structural dependencies with the quaternion algebra. QLSTMs are compared to LSTMs during a memory copy-task and a realistic application of speech recognition on the Wall Street Journal (WSJ) dataset. QLSTM reaches better performances during the two experiments with up to $2.8$ times less learning parameters, leading to a more expressive representation of the information.
Quaternion Recurrent Neural Networks
Jul 05, 2018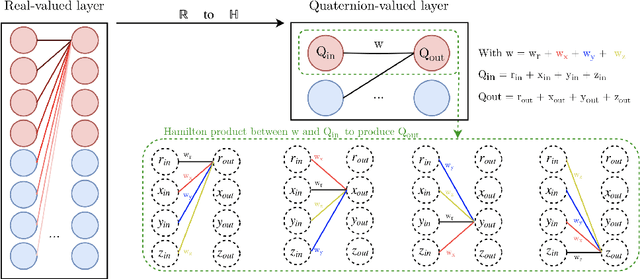

Recurrent neural networks (RNNs) are powerful architectures to model sequential data, due to their capability to learn short and long-term dependencies between the basic elements of a sequence. Nonetheless, popular tasks such as speech or images recognition, involve multi-dimensional input features that are characterized by strong internal dependencies between the dimensions of the input vector. We propose a novel quaternion recurrent neural network (QRNN) that takes into account both the external relations and these internal structural dependencies with the quaternion algebra. Similarly to capsules, quaternions allow the QRNN to code internal dependencies by composing and processing multidimensional features as single entities, while the recurrent operation reveals correlations between the elements composing the sequence. We show that the QRNN achieves better performances in both a synthetic memory copy task and in realistic applications of automatic speech recognition. Finally, we show that the QRNN reduces by a factor of 3x the number of free parameters needed, compared to RNNs to reach better results, leading to a more compact representation of the relevant information.
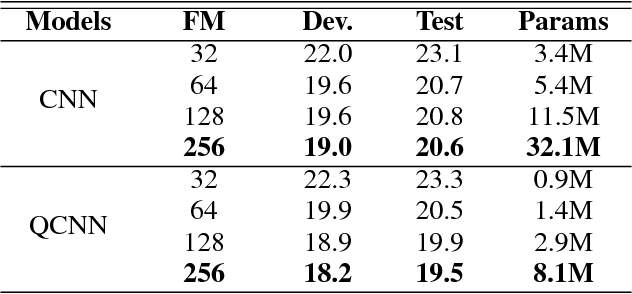
Quaternion Convolutional Neural Networks for End-to-End Automatic Speech Recognition
Jun 20, 2018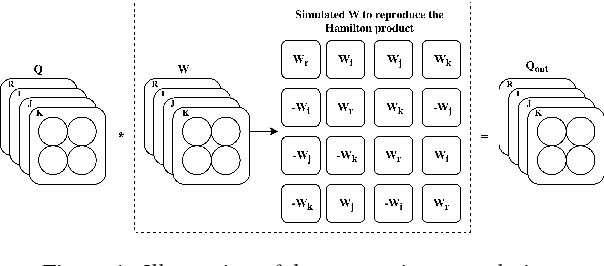
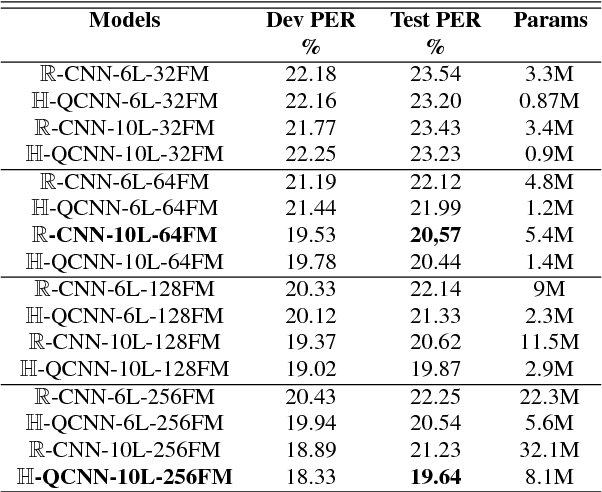
Recently, the connectionist temporal classification (CTC) model coupled with recurrent (RNN) or convolutional neural networks (CNN), made it easier to train speech recognition systems in an end-to-end fashion. However in real-valued models, time frame components such as mel-filter-bank energies and the cepstral coefficients obtained from them, together with their first and second order derivatives, are processed as individual elements, while a natural alternative is to process such components as composed entities. We propose to group such elements in the form of quaternions and to process these quaternions using the established quaternion algebra. Quaternion numbers and quaternion neural networks have shown their efficiency to process multidimensional inputs as entities, to encode internal dependencies, and to solve many tasks with less learning parameters than real-valued models. This paper proposes to integrate multiple feature views in quaternion-valued convolutional neural network (QCNN), to be used for sequence-to-sequence mapping with the CTC model. Promising results are reported using simple QCNNs in phoneme recognition experiments with the TIMIT corpus. More precisely, QCNNs obtain a lower phoneme error rate (PER) with less learning parameters than a competing model based on real-valued CNNs.
Automatic Text Summarization Approaches to Speed up Topic Model Learning Process
Mar 20, 2017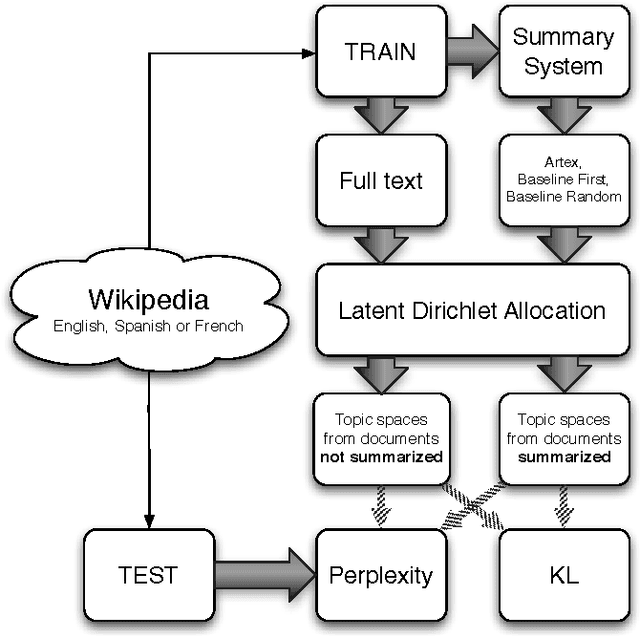
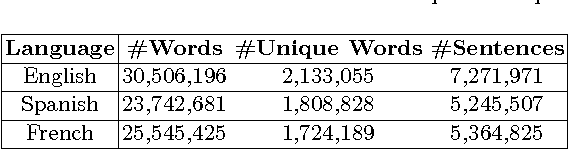
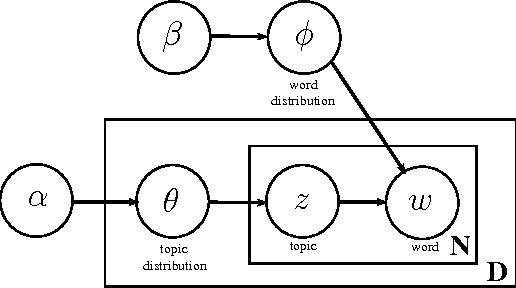
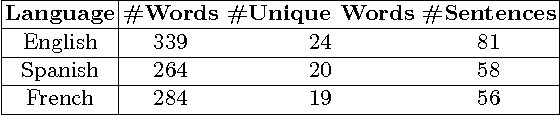
The number of documents available into Internet moves each day up. For this reason, processing this amount of information effectively and expressibly becomes a major concern for companies and scientists. Methods that represent a textual document by a topic representation are widely used in Information Retrieval (IR) to process big data such as Wikipedia articles. One of the main difficulty in using topic model on huge data collection is related to the material resources (CPU time and memory) required for model estimate. To deal with this issue, we propose to build topic spaces from summarized documents. In this paper, we present a study of topic space representation in the context of big data. The topic space representation behavior is analyzed on different languages. Experiments show that topic spaces estimated from text summaries are as relevant as those estimated from the complete documents. The real advantage of such an approach is the processing time gain: we showed that the processing time can be drastically reduced using summarized documents (more than 60\% in general). This study finally points out the differences between thematic representations of documents depending on the targeted languages such as English or latin languages.
* 16 pages, 4 tables, 8 figures
Systèmes du LIA à DEFT'13
Feb 21, 2017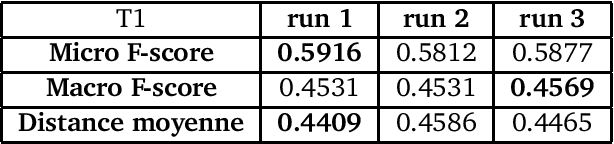


The 2013 D\'efi de Fouille de Textes (DEFT) campaign is interested in two types of language analysis tasks, the document classification and the information extraction in the specialized domain of cuisine recipes. We present the systems that the LIA has used in DEFT 2013. Our systems show interesting results, even though the complexity of the proposed tasks.
* 12 pages, 3 tables, (Paper in French)