 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Text Summarization Approaches to Speed up Topic Model Learning Process
Paper and Code
Mar 20, 2017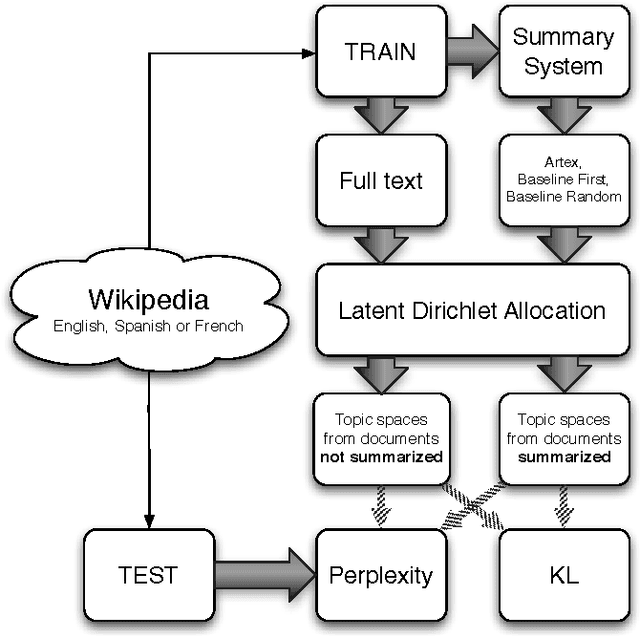
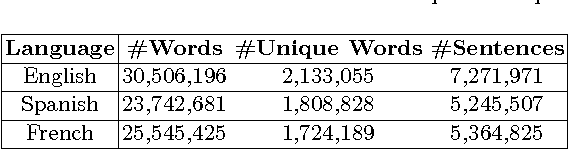
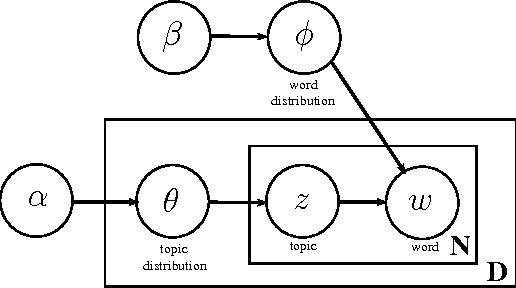
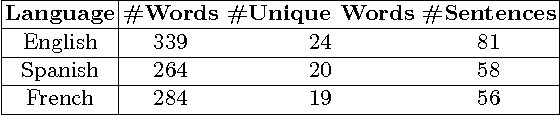
The number of documents available into Internet moves each day up. For this reason, processing this amount of information effectively and expressibly becomes a major concern for companies and scientists. Methods that represent a textual document by a topic representation are widely used in Information Retrieval (IR) to process big data such as Wikipedia articles. One of the main difficulty in using topic model on huge data collection is related to the material resources (CPU time and memory) required for model estimate. To deal with this issue, we propose to build topic spaces from summarized documents. In this paper, we present a study of topic space representation in the context of big data. The topic space representation behavior is analyzed on different languages. Experiments show that topic spaces estimated from text summaries are as relevant as those estimated from the complete documents. The real advantage of such an approach is the processing time gain: we showed that the processing time can be drastically reduced using summarized documents (more than 60\% in general). This study finally points out the differences between thematic representations of documents depending on the targeted languages such as English or latin languages.