 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupling Local Context and Global Semantic Prototypes via a Hierarchical Architecture for Rhetorical Roles Labeling
Mar 04, 2026Rhetorical Role Labeling (RRL) identifies the functional role of each sentence in a document, a key task for discourse understanding in domains such as law and medicine. While hierarchical models capture local dependencies effectively, they are limited in modeling global, corpus-level features. To address this limitation, we propose two prototype-based methods that integrate local context with global representations. Prototype-Based Regularization (PBR) learns soft prototypes through a distance-based auxiliary loss to structure the latent space, while Prototype-Conditioned Modulation (PCM) constructs corpus-level prototypes and injects them during training and inference. Given the scarcity of RRL resources, we introduce SCOTUS-Law, the first dataset of U.S. Supreme Court opinions annotated with rhetorical roles at three levels of granularity: category, rhetorical function, and step. Experiments on legal, medical, and scientific benchmarks show consistent improvements over strong baselines, with 4 Macro-F1 gains on low-frequency roles. We further analyze the implications in the era of Large Language Models and complement our findings with expert evaluation.
Who Judges the Judge? Evaluating LLM-as-a-Judge for French Medical open-ended QA
Mar 04, 2026Automatic evaluation of medical open-ended question answering (OEQA) remains challenging due to the need for expert annotations. We evaluate whether large language models (LLMs) can act as judges of semantic equivalence in French medical OEQA, comparing closed-access, general-purpose, and biomedical domain-adapted models. Our results show that LLM-based judgments are strongly influenced by the model that generated the answer, with agreement varying substantially across generators. Domain-adapted and large general-purpose models achieve the highest alignment with expert annotations. We further show that lightweight adaptation of a compact model using supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) substantially improves performance and reduces generator sensitivity, even with limited data. Overall, our findings highlight the need for generator-aware evaluation and suggest that carefully adapted small models can support scalable evaluation in low-resource medical settings.
Identifying Reliable Evaluation Metrics for Scientific Text Revision
Jun 06, 2025Evaluating text revision in scientific writing remains a challenge, as traditional metrics such as ROUGE and BERTScore primarily focus on similarity rather than capturing meaningful improvements. In this work, we analyse and identify the limitations of these metrics and explore alternative evaluation methods that better align with human judgments. We first conduct a manual annotation study to assess the quality of different revisions. Then, we investigate reference-free evaluation metrics from related NLP domains. Additionally, we examine LLM-as-a-judge approaches, analysing their ability to assess revisions with and without a gold reference. Our results show that LLMs effectively assess instruction-following but struggle with correctness, while domain-specific metrics provide complementary insights. We find that a hybrid approach combining LLM-as-a-judge evaluation and task-specific metrics offers the most reliable assessment of revision quality.
A Benchmark of French ASR Systems Based on Error Severity
Jan 18, 2025

Automatic Speech Recognition (ASR) transcription errors are commonly assessed using metrics that compare them with a reference transcription, such as Word Error Rate (WER), which measures spelling deviations from the reference, or semantic score-based metrics. However, these approaches often overlook what is understandable to humans when interpreting transcription errors. To address this limitation, a new evaluation is proposed that categorizes errors into four levels of severity, further divided into subtypes, based on objective linguistic criteria, contextual patterns, and the use of content words as the unit of analysis. This metric is applied to a benchmark of 10 state-of-the-art ASR systems on French language, encompassing both HMM-based and end-to-end models. Our findings reveal the strengths and weaknesses of each system, identifying those that provide the most comfortable reading experience for users.
ParaRev: Building a dataset for Scientific Paragraph Revision annotated with revision instruction
Jan 09, 2025Revision is a crucial step in scientific writing, where authors refine their work to improve clarity, structure, and academic quality. Existing approaches to automated writing assistance often focus on sentence-level revisions, which fail to capture the broader context needed for effective modification. In this paper, we explore the impact of shifting from sentence-level to paragraph-level scope for the task of scientific text revision. The paragraph level definition of the task allows for more meaningful changes, and is guided by detailed revision instructions rather than general ones. To support this task, we introduce ParaRev, the first dataset of revised scientific paragraphs with an evaluation subset manually annotated with revision instructions. Our experiments demonstrate that using detailed instructions significantly improves the quality of automated revisions compared to general approaches, no matter the model or the metric considered.
The Role of Natural Language Processing Tasks in Automatic Literary Character Network Construction
Dec 16, 2024



The automatic extraction of character networks from literary texts is generally carried out using natural language processing (NLP) cascading pipelines. While this approach is widespread, no study exists on the impact of low-level NLP tasks on their performance. In this article, we conduct such a study on a literary dataset, focusing on the role of named entity recognition (NER) and coreference resolution when extracting co-occurrence networks. To highlight the impact of these tasks' performance, we start with gold-standard annotations, progressively add uniformly distributed errors, and observe their impact in terms of character network quality. We demonstrate that NER performance depends on the tested novel and strongly affects character detection. We also show that NER-detected mentions alone miss a lot of character co-occurrences, and that coreference resolution is needed to prevent this. Finally, we present comparison points with 2 methods based on large language models (LLMs), including a fully end-to-end one, and show that these models are outperformed by traditional NLP pipelines in terms of recall.
Whole-Graph Representation Learning For the Classification of Signed Networks
Sep 30, 2024
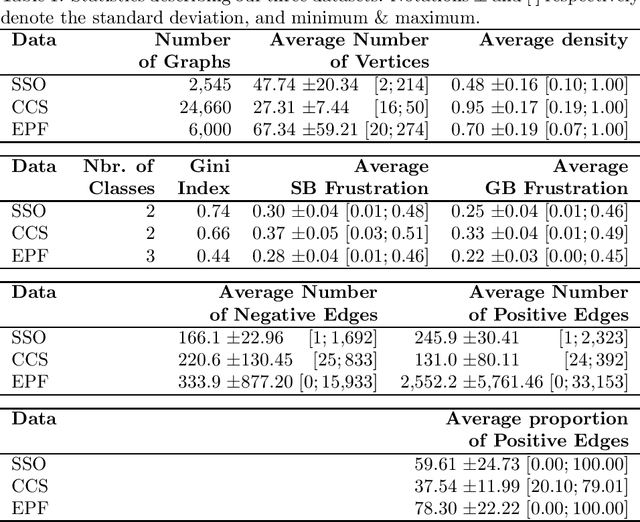

Graphs are ubiquitous for modeling complex systems involving structured data and relationships. Consequently, graph representation learning, which aims to automatically learn low-dimensional representations of graphs, has drawn a lot of attention in recent years. The overwhelming majority of existing methods handle unsigned graphs. However, signed graphs appear in an increasing number of application domains to model systems involving two types of opposed relationships. Several authors took an interest in signed graphs and proposed methods for providing vertex-level representations, but only one exists for whole-graph representations, and it can handle only fully connected graphs. In this article, we tackle this issue by proposing two approaches to learning whole-graph representations of general signed graphs. The first is a SG2V, a signed generalization of the whole-graph embedding method Graph2vec that relies on a modification of the Weisfeiler--Lehman relabelling procedure. The second one is WSGCN, a whole-graph generalization of the signed vertex embedding method SGCN that relies on the introduction of master nodes into the GCN. We propose several variants of both these approaches. A bottleneck in the development of whole-graph-oriented methods is the lack of data. We constitute a benchmark composed of three collections of signed graphs with corresponding ground truths. We assess our methods on this benchmark, and our results show that the signed whole-graph methods learn better representations for this task. Overall, the baseline obtains an F-measure score of 58.57, when SG2V and WSGCN reach 73.01 and 81.20, respectively. Our source code and benchmark dataset are both publicly available online.
Renard: A Modular Pipeline for Extracting Character Networks from Narrative Texts
Jul 02, 2024

Renard (Relationships Extraction from NARrative Documents) is a Python library that allows users to define custom natural language processing (NLP) pipelines to extract character networks from narrative texts. Contrary to the few existing tools, Renard can extract dynamic networks, as well as the more common static networks. Renard pipelines are modular: users can choose the implementation of each NLP subtask needed to extract a character network. This allows users to specialize pipelines to particular types of texts and to study the impact of each subtask on the extracted network.
* Accepted at JOSS
Zero-Shot End-To-End Spoken Question Answering In Medical Domain
Jun 09, 2024In the rapidly evolving landscape of spoken question-answering (SQA), the integration of large language models (LLMs) has emerged as a transformative development. Conventional approaches often entail the use of separate models for question audio transcription and answer selection, resulting in significant resource utilization and error accumulation. To tackle these challenges, we explore the effectiveness of end-to-end (E2E) methodologies for SQA in the medical domain. Our study introduces a novel zero-shot SQA approach, compared to traditional cascade systems. Through a comprehensive evaluation conducted on a new open benchmark of 8 medical tasks and 48 hours of synthetic audio, we demonstrate that our approach requires up to 14.7 times fewer resources than a combined 1.3B parameters LLM with a 1.55B parameters ASR model while improving average accuracy by 0.5\%. These findings underscore the potential of E2E methodologies for SQA in resource-constrained contexts.
* Accepted to INTERSPEECH 2024
CASIMIR: A Corpus of Scientific Articles enhanced with Multiple Author-Integrated Revisions
Mar 01, 2024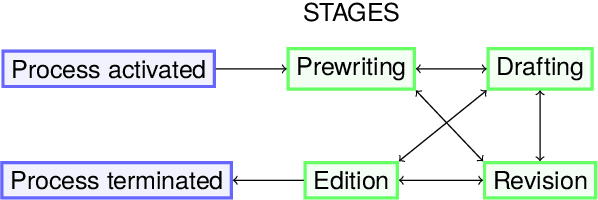
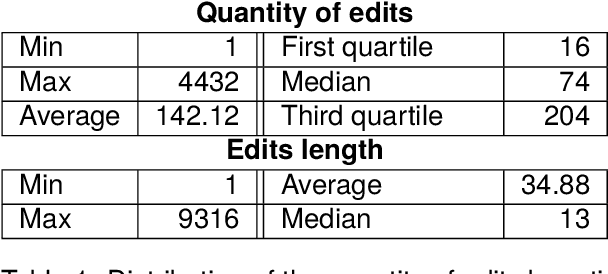


Writing a scientific article is a challenging task as it is a highly codified and specific genre, consequently proficiency in written communication is essential for effectively conveying research findings and ideas. In this article, we propose an original textual resource on the revision step of the writing process of scientific articles. This new dataset, called CASIMIR, contains the multiple revised versions of 15,646 scientific articles from OpenReview, along with their peer reviews. Pairs of consecutive versions of an article are aligned at sentence-level while keeping paragraph location information as metadata for supporting future revision studies at the discourse level. Each pair of revised sentences is enriched with automatically extracted edits and associated revision intention. To assess the initial quality on the dataset, we conducted a qualitative study of several state-of-the-art text revision approaches and compared various evaluation metrics. Our experiments led us to question the relevance of the current evaluation methods for the text revision task.