 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole-Graph Representation Learning For the Classification of Signed Networks
Sep 30, 2024
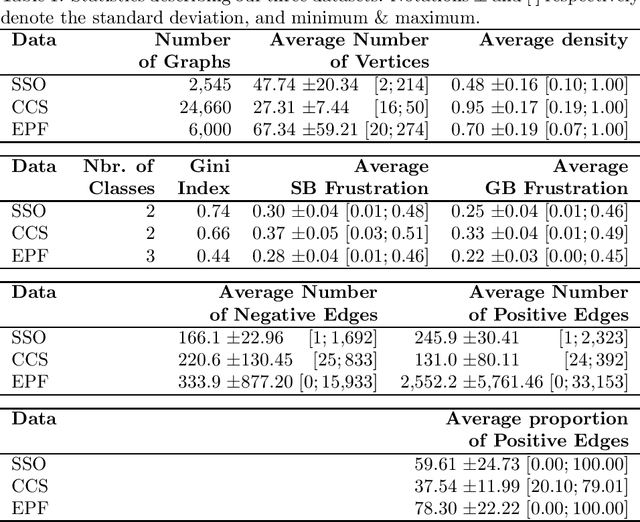
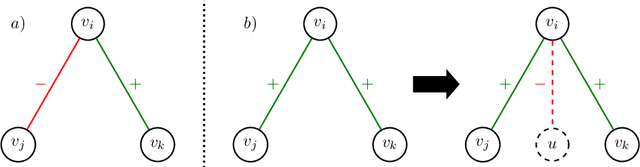

Graphs are ubiquitous for modeling complex systems involving structured data and relationships. Consequently, graph representation learning, which aims to automatically learn low-dimensional representations of graphs, has drawn a lot of attention in recent years. The overwhelming majority of existing methods handle unsigned graphs. However, signed graphs appear in an increasing number of application domains to model systems involving two types of opposed relationships. Several authors took an interest in signed graphs and proposed methods for providing vertex-level representations, but only one exists for whole-graph representations, and it can handle only fully connected graphs. In this article, we tackle this issue by proposing two approaches to learning whole-graph representations of general signed graphs. The first is a SG2V, a signed generalization of the whole-graph embedding method Graph2vec that relies on a modification of the Weisfeiler--Lehman relabelling procedure. The second one is WSGCN, a whole-graph generalization of the signed vertex embedding method SGCN that relies on the introduction of master nodes into the GCN. We propose several variants of both these approaches. A bottleneck in the development of whole-graph-oriented methods is the lack of data. We constitute a benchmark composed of three collections of signed graphs with corresponding ground truths. We assess our methods on this benchmark, and our results show that the signed whole-graph methods learn better representations for this task. Overall, the baseline obtains an F-measure score of 58.57, when SG2V and WSGCN reach 73.01 and 81.20, respectively. Our source code and benchmark dataset are both publicly available online.
WAC: A Corpus of Wikipedia Conversations for Online Abuse Detection
Mar 13, 2020
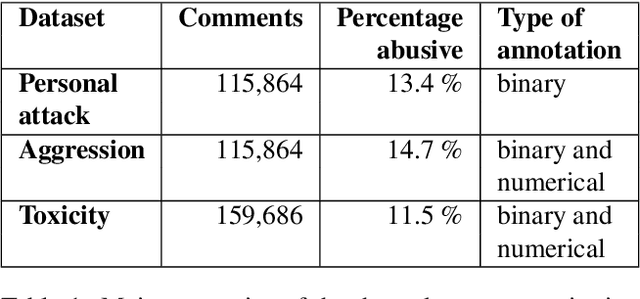

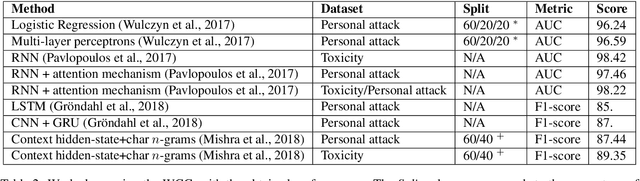
With the spread of online social networks, it is more and more difficult to monitor all the user-generated content. Automating the moderation process of the inappropriate exchange content on Internet has thus become a priority task. Methods have been proposed for this purpose, but it can be challenging to find a suitable dataset to train and develop them. This issue is especially true for approaches based on information derived from the structure and the dynamic of the conversation. In this work, we propose an original framework, based on the Wikipedia Comment corpus, with comment-level abuse annotations of different types. The major contribution concerns the reconstruction of conversations, by comparison to existing corpora, which focus only on isolated messages (i.e. taken out of their conversational context). This large corpus of more than 380k annotated messages opens perspectives for online abuse detection and especially for context-based approaches. We also propose, in addition to this corpus, a complete benchmarking platform to stimulate and fairly compare scientific works around the problem of content abuse detection, trying to avoid the recurring problem of result replication. Finally, we apply two classification methods to our dataset to demonstrate its potential.
Abusive Language Detection in Online Conversations by Combining Content-and Graph-based Features
May 20, 2019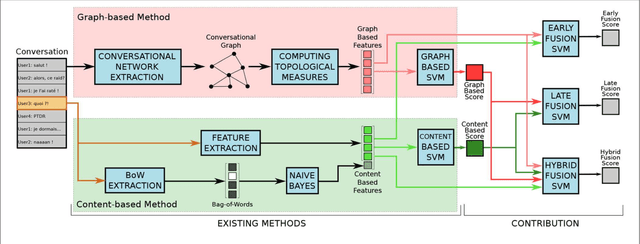
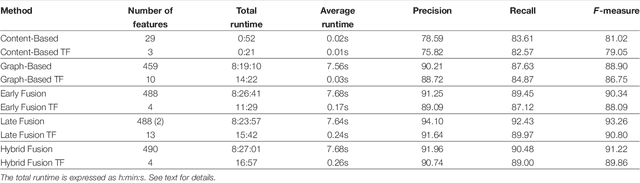
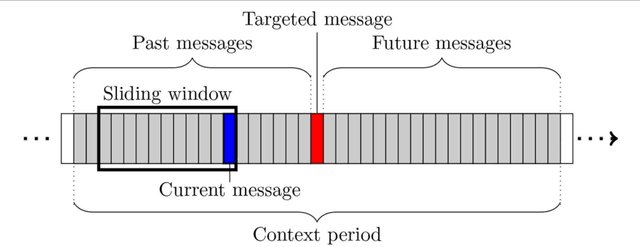
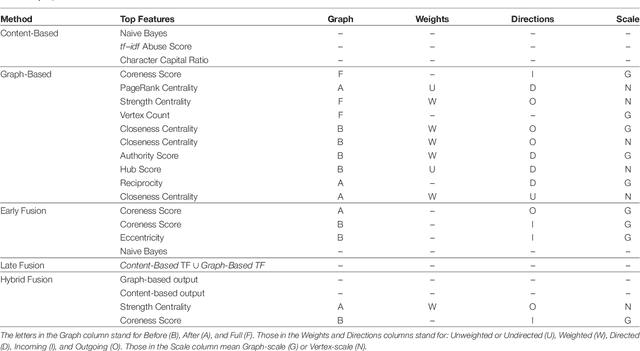
In recent years, online social networks have allowed worldwide users to meet and discuss. As guarantors of these communities, the administrators of these platforms must prevent users from adopting inappropriate behaviors. This verification task, mainly done by humans, is more and more difficult due to the ever growing amount of messages to check. Methods have been proposed to automatize this moderation process, mainly by providing approaches based on the textual content of the exchanged messages. Recent work has also shown that characteristics derived from the structure of conversations, in the form of conversational graphs, can help detecting these abusive messages. In this paper, we propose to take advantage of both sources of information by proposing fusion methods integrating content-and graph-based features. Our experiments on raw chat logs show that the content of the messages, but also of their dynamics within a conversation contain partially complementary information, allowing performance improvements on an abusive message classification task with a final F-measure of 93.26%.