 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAC: A Corpus of Wikipedia Conversations for Online Abuse Detection
Mar 13, 2020
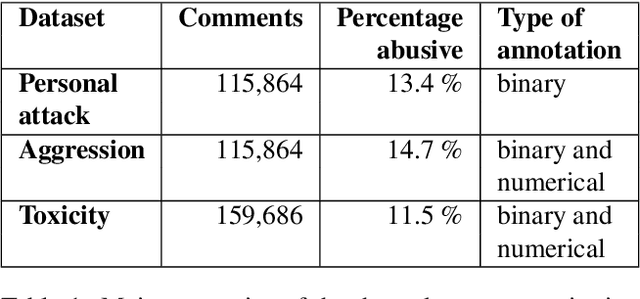

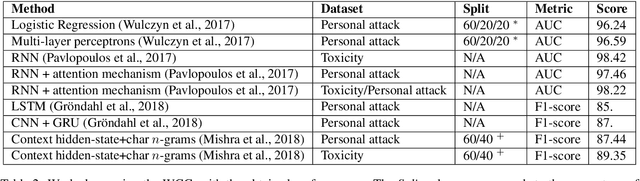
With the spread of online social networks, it is more and more difficult to monitor all the user-generated content. Automating the moderation process of the inappropriate exchange content on Internet has thus become a priority task. Methods have been proposed for this purpose, but it can be challenging to find a suitable dataset to train and develop them. This issue is especially true for approaches based on information derived from the structure and the dynamic of the conversation. In this work, we propose an original framework, based on the Wikipedia Comment corpus, with comment-level abuse annotations of different types. The major contribution concerns the reconstruction of conversations, by comparison to existing corpora, which focus only on isolated messages (i.e. taken out of their conversational context). This large corpus of more than 380k annotated messages opens perspectives for online abuse detection and especially for context-based approaches. We also propose, in addition to this corpus, a complete benchmarking platform to stimulate and fairly compare scientific works around the problem of content abuse detection, trying to avoid the recurring problem of result replication. Finally, we apply two classification methods to our dataset to demonstrate its potential.
Conversational Networks for Automatic Online Moderation
Jan 31, 2019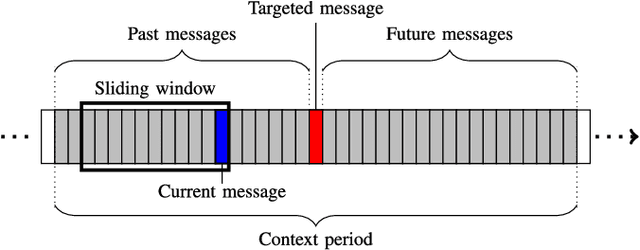
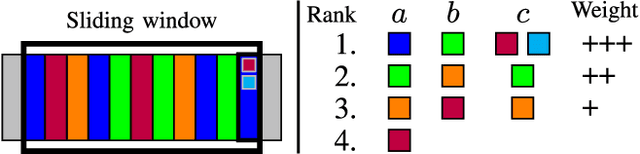

Moderation of user-generated content in an online community is a challenge that has great socio-economical ramifications. However, the costs incurred by delegating this work to human agents are high. For this reason, an automatic system able to detect abuse in user-generated content is of great interest. There are a number of ways to tackle this problem, but the most commonly seen in practice are word filtering or regular expression matching. The main limitations are their vulnerability to intentional obfuscation on the part of the users, and their context-insensitive nature. Moreover, they are language-dependent and may require appropriate corpora for training. In this paper, we propose a system for automatic abuse detection that completely disregards message content. We first extract a conversational network from raw chat logs and characterize it through topological measures. We then use these as features to train a classifier on our abuse detection task. We thoroughly assess our system on a dataset of user comments originating from a French Massively Multiplayer Online Game. We identify the most appropriate network extraction parameters and discuss the discriminative power of our features, relatively to their topological and temporal nature. Our method reaches an F-measure of 83.89 when using the full feature set, improving on existing approaches. With a selection of the most discriminative features, we dramatically cut computing time while retaining most of the performance (82.65).
Constrained speaker diarization of TV series based on visual patterns
Dec 29, 2018


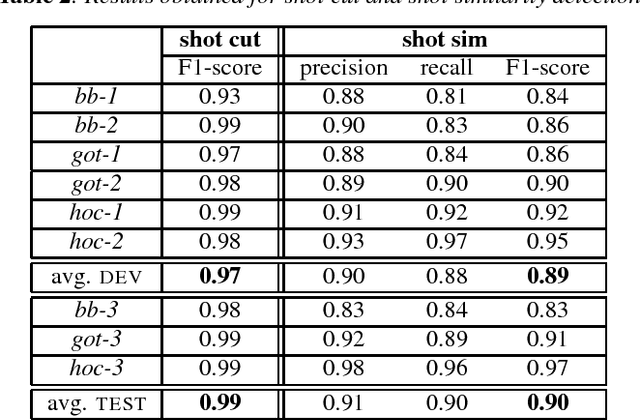
Speaker diarization, usually denoted as the ''who spoke when'' task, turns out to be particularly challenging when applied to fictional films, where many characters talk in various acoustic conditions (background music, sound effects...). Despite this acoustic variability , such movies exhibit specific visual patterns in the dialogue scenes. In this paper, we introduce a two-step method to achieve speaker diarization in TV series: a speaker diarization is first performed locally in the scenes detected as dialogues; then, the hypothesized local speakers are merged in a second agglomerative clustering process, with the constraint that speakers locally hypothesized to be distinct must not be assigned to the same cluster. The performances of our approach are compared to those obtained by standard speaker diarization tools applied to the same data.
D{é}tection de locuteurs dans les s{é}ries TV
Dec 18, 2018

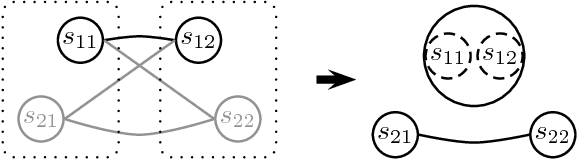
Speaker diarization of audio streams turns out to be particularly challenging when applied to fictional films, where many characters talk in various acoustic conditions (background music, sound effects, variations in intonation...). Despite this acoustic variability, such movies exhibit specific visual patterns, particularly within dialogue scenes. In this paper, we introduce a two-step method to achieve speaker diarization in TV series: speaker diarization is first performed locally within scenes visually identified as dialogues; then, the hypothesized local speakers are compared to each other during a second clustering process in order to detect recurring speakers: this second stage of clustering is subject to the constraint that the different speakers involved in the same dialogue have to be assigned to different clusters. The performances of our approach are compared to those obtained by standard speaker diarization tools applied to the same data.
* in French