 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained speaker diarization of TV series based on visual patterns
Paper and Code
Dec 29, 2018


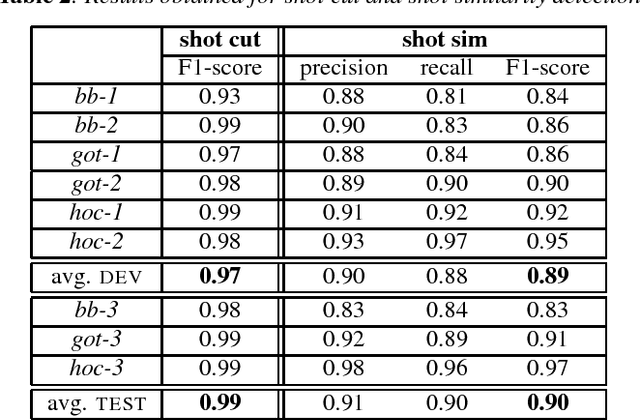
Speaker diarization, usually denoted as the ''who spoke when'' task, turns out to be particularly challenging when applied to fictional films, where many characters talk in various acoustic conditions (background music, sound effects...). Despite this acoustic variability , such movies exhibit specific visual patterns in the dialogue scenes. In this paper, we introduce a two-step method to achieve speaker diarization in TV series: a speaker diarization is first performed locally in the scenes detected as dialogues; then, the hypothesized local speakers are merged in a second agglomerative clustering process, with the constraint that speakers locally hypothesized to be distinct must not be assigned to the same cluster. The performances of our approach are compared to those obtained by standard speaker diarization tools applied to the same data.