 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Adaptation to Specialized Domains through Selective Masking based on Genre and Topical Characteristics
Feb 26, 2024

Recent advances in pre-trained language modeling have facilitated significant progress across various natural language processing (NLP) tasks. Word masking during model training constitutes a pivotal component of language modeling in architectures like BERT. However, the prevalent method of word masking relies on random selection, potentially disregarding domain-specific linguistic attributes. In this article, we introduce an innovative masking approach leveraging genre and topicality information to tailor language models to specialized domains. Our method incorporates a ranking process that prioritizes words based on their significance, subsequently guiding the masking procedure. Experiments conducted using continual pre-training within the legal domain have underscored the efficacy of our approach on the LegalGLUE benchmark in the English language. Pre-trained language models and code are freely available for use.
Keyphrase Generation for Scientific Document Retrieval
Jun 28, 2021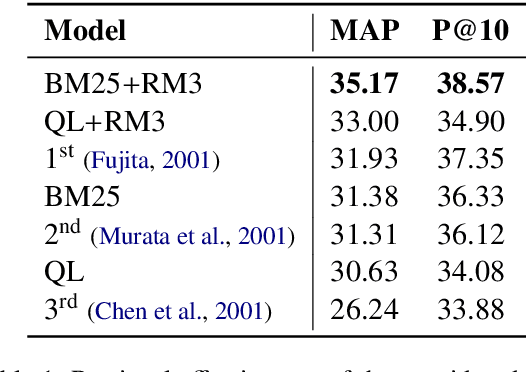
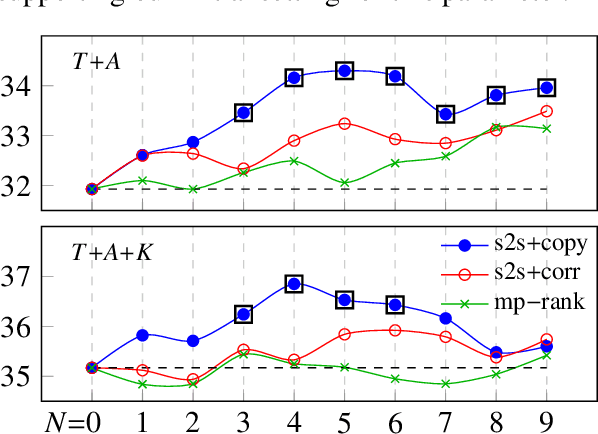


Sequence-to-sequence models have lead to significant progress in keyphrase generation, but it remains unknown whether they are reliable enough to be beneficial for document retrieval. This study provides empirical evidence that such models can significantly improve retrieval performance, and introduces a new extrinsic evaluation framework that allows for a better understanding of the limitations of keyphrase generation models. Using this framework, we point out and discuss the difficulties encountered with supplementing documents with -- not present in text -- keyphrases, and generalizing models across domains. Our code is available at https://github.com/boudinfl/ir-using-kg
Redefining Absent Keyphrases and their Effect on Retrieval Effectiveness
Apr 02, 2021
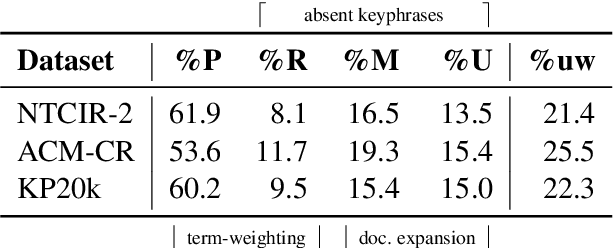
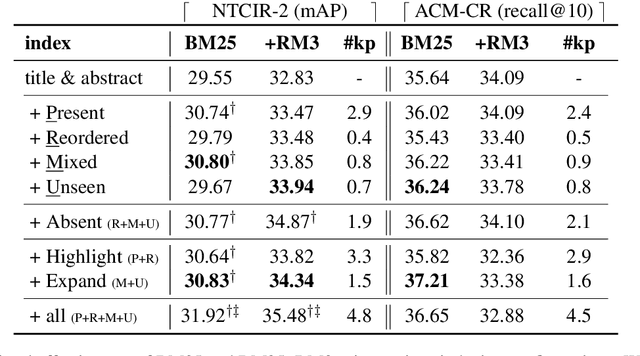

Neural keyphrase generation models have recently attracted much interest due to their ability to output absent keyphrases, that is, keyphrases that do not appear in the source text. In this paper, we discuss the usefulness of absent keyphrases from an Information Retrieval (IR) perspective, and show that the commonly drawn distinction between present and absent keyphrases is not made explicit enough. We introduce a finer-grained categorization scheme that sheds more light on the impact of absent keyphrases on scientific document retrieval. Under this scheme, we find that only a fraction (around 20%) of the words that make up keyphrases actually serves as document expansion, but that this small fraction of words is behind much of the gains observed in retrieval effectiveness. We also discuss how the proposed scheme can offer a new angle to evaluate the output of neural keyphrase generation models.
KPTimes: A Large-Scale Dataset for Keyphrase Generation on News Documents
Nov 28, 2019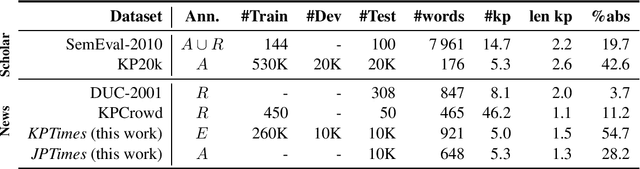
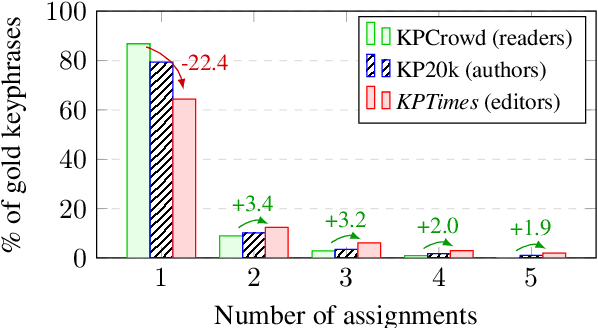

Keyphrase generation is the task of predicting a set of lexical units that conveys the main content of a source text. Existing datasets for keyphrase generation are only readily available for the scholarly domain and include non-expert annotations. In this paper we present KPTimes, a large-scale dataset of news texts paired with editor-curated keyphrases. Exploring the dataset, we show how editors tag documents, and how their annotations differ from those found in existing datasets. We also train and evaluate state-of-the-art neural keyphrase generation models on KPTimes to gain insights on how well they perform on the news domain. The dataset is available online at https://github.com/ygorg/KPTimes .