 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Reliable Evaluation Metrics for Scientific Text Revision
Jun 06, 2025Evaluating text revision in scientific writing remains a challenge, as traditional metrics such as ROUGE and BERTScore primarily focus on similarity rather than capturing meaningful improvements. In this work, we analyse and identify the limitations of these metrics and explore alternative evaluation methods that better align with human judgments. We first conduct a manual annotation study to assess the quality of different revisions. Then, we investigate reference-free evaluation metrics from related NLP domains. Additionally, we examine LLM-as-a-judge approaches, analysing their ability to assess revisions with and without a gold reference. Our results show that LLMs effectively assess instruction-following but struggle with correctness, while domain-specific metrics provide complementary insights. We find that a hybrid approach combining LLM-as-a-judge evaluation and task-specific metrics offers the most reliable assessment of revision quality.
ParaRev: Building a dataset for Scientific Paragraph Revision annotated with revision instruction
Jan 09, 2025Revision is a crucial step in scientific writing, where authors refine their work to improve clarity, structure, and academic quality. Existing approaches to automated writing assistance often focus on sentence-level revisions, which fail to capture the broader context needed for effective modification. In this paper, we explore the impact of shifting from sentence-level to paragraph-level scope for the task of scientific text revision. The paragraph level definition of the task allows for more meaningful changes, and is guided by detailed revision instructions rather than general ones. To support this task, we introduce ParaRev, the first dataset of revised scientific paragraphs with an evaluation subset manually annotated with revision instructions. Our experiments demonstrate that using detailed instructions significantly improves the quality of automated revisions compared to general approaches, no matter the model or the metric considered.
CASIMIR: A Corpus of Scientific Articles enhanced with Multiple Author-Integrated Revisions
Mar 01, 2024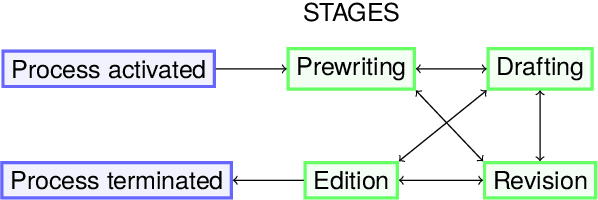


Writing a scientific article is a challenging task as it is a highly codified and specific genre, consequently proficiency in written communication is essential for effectively conveying research findings and ideas. In this article, we propose an original textual resource on the revision step of the writing process of scientific articles. This new dataset, called CASIMIR, contains the multiple revised versions of 15,646 scientific articles from OpenReview, along with their peer reviews. Pairs of consecutive versions of an article are aligned at sentence-level while keeping paragraph location information as metadata for supporting future revision studies at the discourse level. Each pair of revised sentences is enriched with automatically extracted edits and associated revision intention. To assess the initial quality on the dataset, we conducted a qualitative study of several state-of-the-art text revision approaches and compared various evaluation metrics. Our experiments led us to question the relevance of the current evaluation methods for the text revision task.
Language Model Adaptation to Specialized Domains through Selective Masking based on Genre and Topical Characteristics
Feb 26, 2024

Recent advances in pre-trained language modeling have facilitated significant progress across various natural language processing (NLP) tasks. Word masking during model training constitutes a pivotal component of language modeling in architectures like BERT. However, the prevalent method of word masking relies on random selection, potentially disregarding domain-specific linguistic attributes. In this article, we introduce an innovative masking approach leveraging genre and topicality information to tailor language models to specialized domains. Our method incorporates a ranking process that prioritizes words based on their significance, subsequently guiding the masking procedure. Experiments conducted using continual pre-training within the legal domain have underscored the efficacy of our approach on the LegalGLUE benchmark in the English language. Pre-trained language models and code are freely available for use.
Harnessing GPT-3.5-turbo for Rhetorical Role Prediction in Legal Cases
Oct 26, 2023We propose a comprehensive study of one-stage elicitation techniques for querying a large pre-trained generative transformer (GPT-3.5-turbo) in the rhetorical role prediction task of legal cases. This task is known as requiring textual context to be addressed. Our study explores strategies such as zero-few shots, task specification with definitions and clarification of annotation ambiguities, textual context and reasoning with general prompts and specific questions. We show that the number of examples, the definition of labels, the presentation of the (labelled) textual context and specific questions about this context have a positive influence on the performance of the model. Given non-equivalent test set configurations, we observed that prompting with a few labelled examples from direct context can lead the model to a better performance than a supervised fined-tuned multi-class classifier based on the BERT encoder (weighted F1 score of = 72%). But there is still a gap to reach the performance of the best systems = 86%) in the LegalEval 2023 task which, on the other hand, require dedicated resources, architectures and training.
Enhancing Pre-Trained Language Models with Sentence Position Embeddings for Rhetorical Roles Recognition in Legal Opinions
Oct 08, 2023The legal domain is a vast and complex field that involves a considerable amount of text analysis, including laws, legal arguments, and legal opinions. Legal practitioners must analyze these texts to understand legal cases, research legal precedents, and prepare legal documents. The size of legal opinions continues to grow, making it increasingly challenging to develop a model that can accurately predict the rhetorical roles of legal opinions given their complexity and diversity. In this research paper, we propose a novel model architecture for automatically predicting rhetorical roles using pre-trained language models (PLMs) enhanced with knowledge of sentence position information within a document. Based on an annotated corpus from the LegalEval@SemEval2023 competition, we demonstrate that our approach requires fewer parameters, resulting in lower computational costs when compared to complex architectures employing a hierarchical model in a global-context, yet it achieves great performance. Moreover, we show that adding more attention to a hierarchical model based only on BERT in the local-context, along with incorporating sentence position information, enhances the results.
* Workshop on Automated Semantic Analysis of Information in Legal Text
Text revision in Scientific Writing Assistance: An Overview
Mar 29, 2023Writing a scientific article is a challenging task as it is a highly codified genre. Good writing skills are essential to properly convey ideas and results of research work. Since the majority of scientific articles are currently written in English, this exercise is all the more difficult for non-native English speakers as they additionally have to face language issues. This article aims to provide an overview of text revision in writing assistance in the scientific domain. We will examine the specificities of scientific writing, including the format and conventions commonly used in research articles. Additionally, this overview will explore the various types of writing assistance tools available for text revision. Despite the evolution of the technology behind these tools through the years, from rule-based approaches to deep neural-based ones, challenges still exist (tools' accessibility, limited consideration of the context, inexplicit use of discursive information, etc.)
Deep Retrieval-Based Dialogue Systems: A Short Review
Jul 30, 2019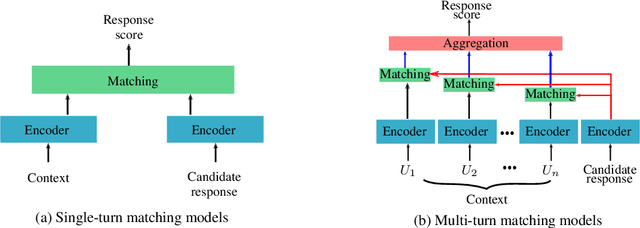
Building dialogue systems that naturally converse with humans is being an attractive and an active research domain. Multiple systems are being designed everyday and several datasets are being available. For this reason, it is being hard to keep an up-to-date state-of-the-art. In this work, we present the latest and most relevant retrieval-based dialogue systems and the available datasets used to build and evaluate them. We discuss their limitations and provide insights and guidelines for future work.
What's in a Message?
Feb 13, 2009
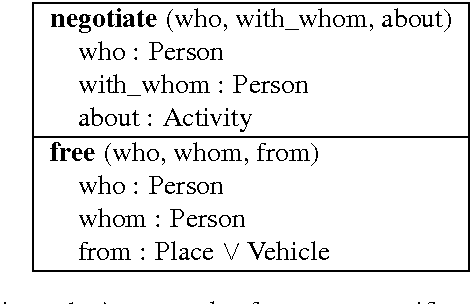

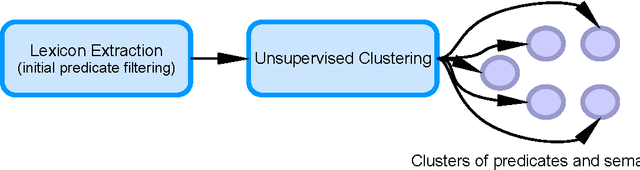
In this paper we present the first step in a larger series of experiments for the induction of predicate/argument structures. The structures that we are inducing are very similar to the conceptual structures that are used in Frame Semantics (such as FrameNet). Those structures are called messages and they were previously used in the context of a multi-document summarization system of evolving events. The series of experiments that we are proposing are essentially composed from two stages. In the first stage we are trying to extract a representative vocabulary of words. This vocabulary is later used in the second stage, during which we apply to it various clustering approaches in order to identify the clusters of predicates and arguments--or frames and semantic roles, to use the jargon of Frame Semantics. This paper presents in detail and evaluates the first stage.